Scale from Zero to Millions of Users
6 min readScaling from a single server to millions of users requires continuous refinement through multiple architectural layers.
Single server setup
Everything runs on one server: web app, database, cache, etc.
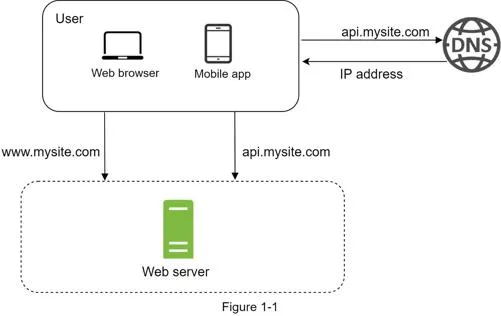
Request flow:
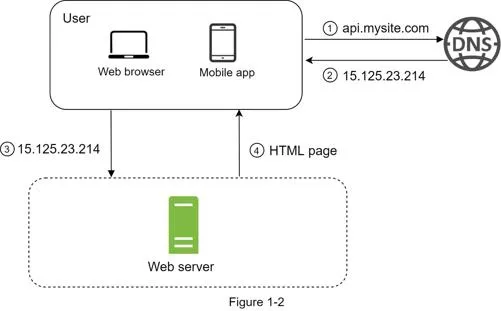
- Users access via domain names (DNS, usually 3rd-party service)
- DNS returns IP address to browser/mobile app
- HTTP requests sent directly to web server
- Web server returns HTML/JSON
Traffic sources: Web applications (server-side languages + client-side HTML/JS) and mobile applications (HTTP + JSON). Example: GET /users/12 returns JSON user object.

Database
With growth, separate web tier from data tier to scale independently.
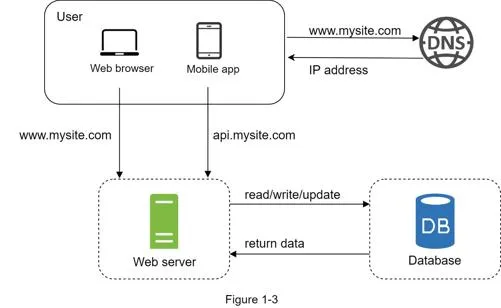
Relational (SQL): MySQL, Oracle, PostgreSQL. Data in tables/rows, supports JOINs. Non-relational (NoSQL): CouchDB, Neo4j, Cassandra, HBase, DynamoDB. Four categories: key-value, graph, column, document stores. No JOINs.
Choose NoSQL when: super-low latency needed, unstructured data, only need serialization (JSON/XML/YAML), or massive data storage.
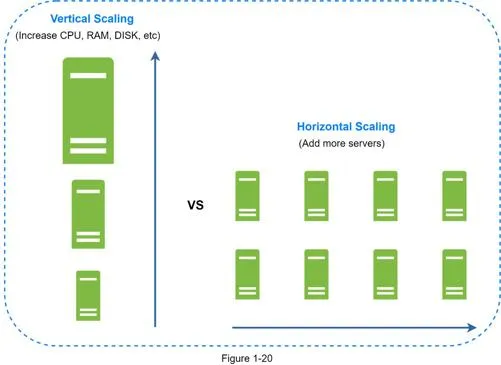
Vertical scaling vs horizontal scaling
- Vertical (scale up): Add more CPU/RAM to existing server. Simple but has hard limits, no failover, expensive.
- Horizontal (scale out): Add more servers to resource pool. Preferred for large-scale applications.
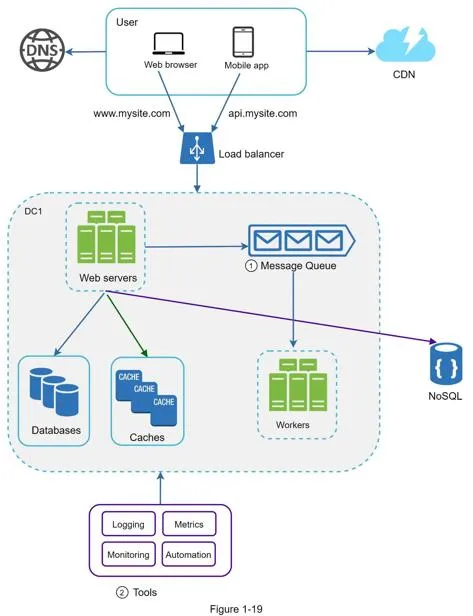
Load balancer
Evenly distributes incoming traffic among web servers in a load-balanced set.
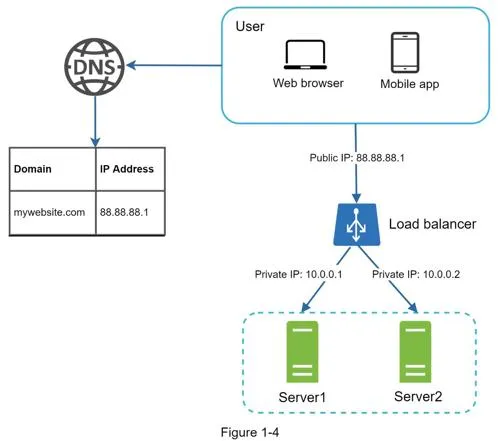
- Users connect to load balancer's public IP
- Web servers use private IPs (unreachable from internet)
- If one server goes offline, traffic routes to healthy servers; new servers added seamlessly
- Solves failover and availability issues for the web tier
Database replication
Master/slave model: master supports writes only, slaves support reads only (typically more slaves since read ratio is higher).
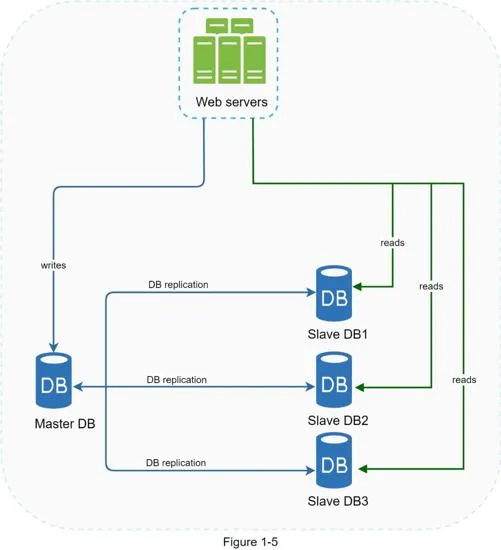
Advantages:
- Better performance: parallel query processing across slaves
- Reliability: data preserved even if one server destroyed
- High availability: system operates even if one database offline
Failure handling:
- Slave offline: reads redirected to master (or other slaves), new slave replaces old one
- Master offline: a slave promoted to new master (requires data recovery scripts for missing data). Multi-master and circular replication are more complex alternatives.
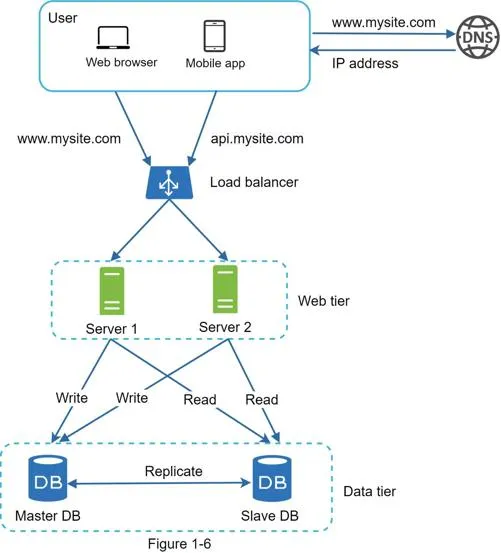
Full request flow: User → DNS → LB public IP → HTTP request routed to Server 1/2 → read from slave DB → write/update/delete → master DB.
Cache
Temporary storage for expensive responses or frequently accessed data in memory. Mitigates repeated database calls.

Read-through cache strategy: Web server checks cache → if hit, return data → if miss, query DB, store in cache, return data.
Considerations:
- Use when data is read frequently, modified infrequently. Not ideal for persistent data (volatile memory).
- Expiration policy: Too short = frequent DB reloads; too long = stale data.
- Consistency: Keeping data store and cache in sync is challenging at scale (see Facebook's "Scaling Memcache" paper).
- Mitigating failures: Multiple cache servers across data centers avoid SPOF. Overprovision memory by percentage.
- Eviction Policy: LRU most popular. Also LFU, FIFO.
Content delivery network (CDN)
Network of geographically dispersed servers caching static content (images, videos, CSS, JS).
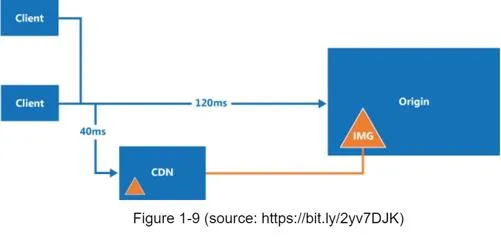
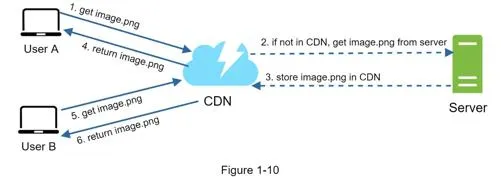
CDN workflow:
- User requests image via CDN-provided URL (e.g.,
https://mysite.cloudfront.net/logo.jpg) - CDN server checks cache; if miss, requests from origin (web server or S3)
- Origin returns file with optional TTL header
- CDN caches and returns to User A
- User B requests same image → served from CDN cache (if TTL not expired)
Considerations:
- Cost: charged for data transfers in/out. Remove infrequently used assets.
- Cache expiry: too long = stale content; too short = repeated origin reloading.
- CDN fallback: clients should detect CDN outage and request from origin.
- Invalidating files: Use CDN vendor APIs or object versioning (e.g.,
image.png?v=2).
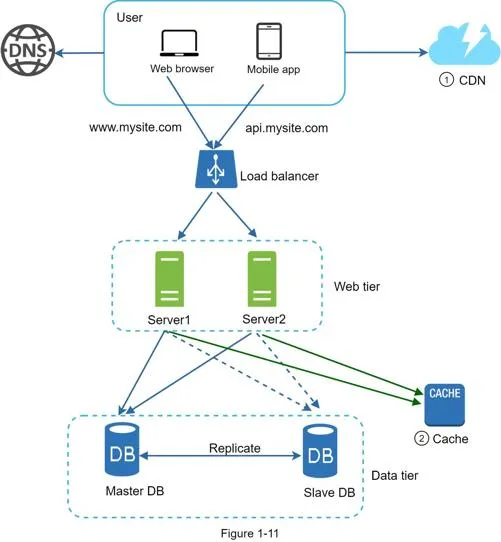
After CDN + cache: static assets served from CDN, database load lightened.
Stateless web tier
Move state (session data) out of web tier into persistent storage (DB or NoSQL) so any web server can handle any request.
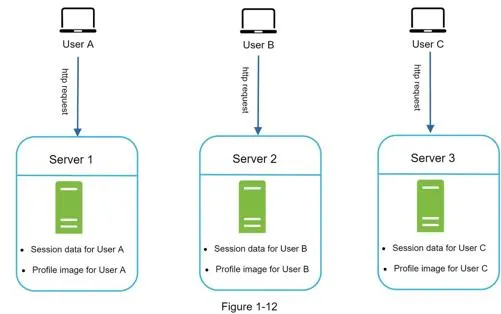
Stateful architecture: Sticky sessions required to route same client to same server. Adding/removing servers is difficult.
Stateless architecture: HTTP requests go to any server; state fetched from shared data store.
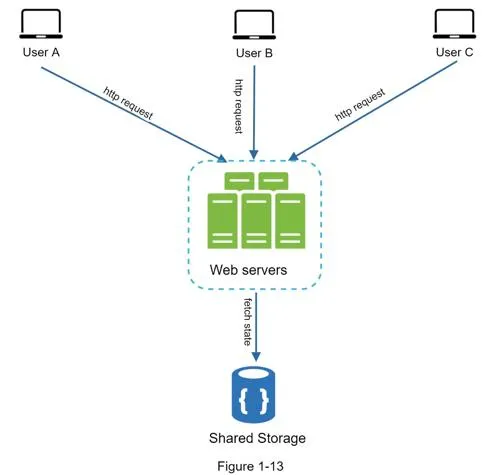
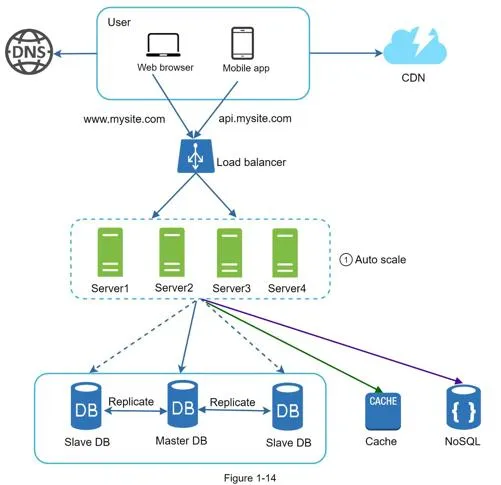
Benefits: simpler, more robust, scalable. Enables auto-scaling (add/remove servers based on traffic). NoSQL data store preferred for session data.
Data centers
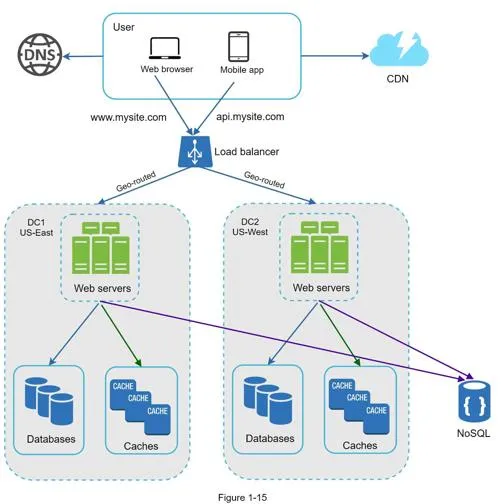
- Users geoDNS-routed to closest data center (split traffic x% US-East, (100−x)% US-West)
- On data center outage, all traffic routed to healthy data center
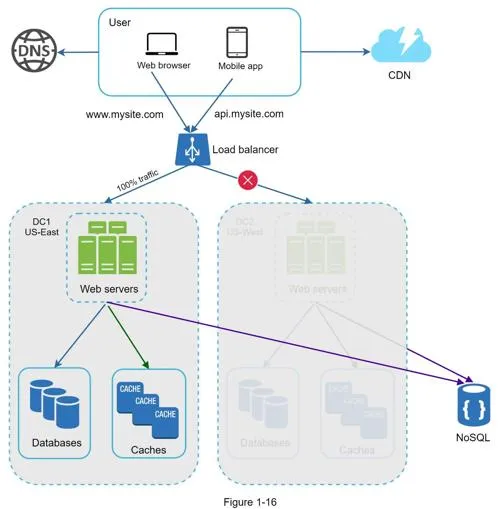
Technical challenges:
- Traffic redirection: GeoDNS directs to nearest data center
- Data synchronization: Replicate data across multiple data centers (see Netflix's async multi-datacenter replication)
- Test and deployment: Automated deployment tools essential for consistency across data centers
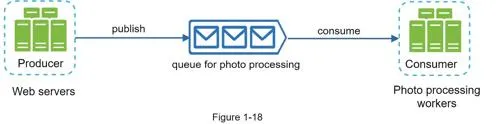
Message queue
Durable, in-memory component supporting asynchronous communication. Producers publish messages, consumers subscribe and process.

Decouples components so they scale independently. Example: photo processing — web servers publish jobs to queue, photo processing workers consume asynchronously. When queue grows, add more workers; when empty, reduce workers.
Logging, metrics, automation
Essential at scale:
- Logging: Monitor error logs per server or aggregate to centralized service
- Metrics: Host-level (CPU, memory, disk I/O), aggregated (DB/cache tier performance), business (DAU, retention, revenue)
- Automation: CI (verify each check-in), automated build/test/deploy
Database scaling
Vertical scaling
Add more CPU/RAM/Disk to existing machine. Stack Overflow (2013): 10M+ monthly unique visitors, 1 master DB. Limitations: hardware limits, SPOF risk, expensive.
Horizontal scaling (sharding)
Separate large databases into smaller shards, each with same schema but unique data.
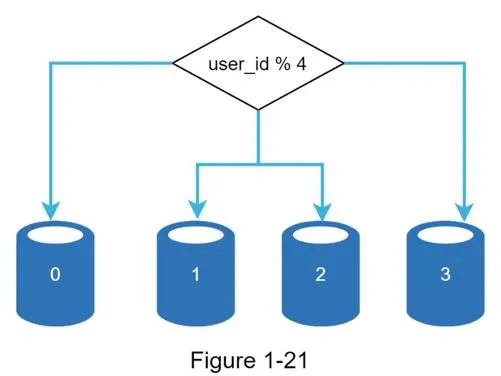
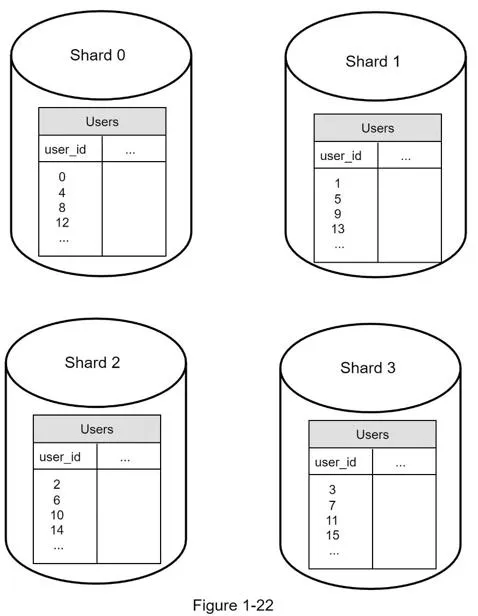
- Sharding key (partition key): Determines data distribution. Example:
user_id % 4= shard index. Must evenly distribute data. - Challenges:
- Resharding: Needed when a shard can't hold more data or uneven distribution causes shard exhaustion. Consistent hashing (Chapter 5) helps.
- Celebrity/hotspot key problem: Excessive access to specific shard overloads server. Solution: allocate dedicated shards for celebrities.
- Join and de-normalization: Hard to perform JOINs across shards. Workaround: de-normalize so queries work on single table.
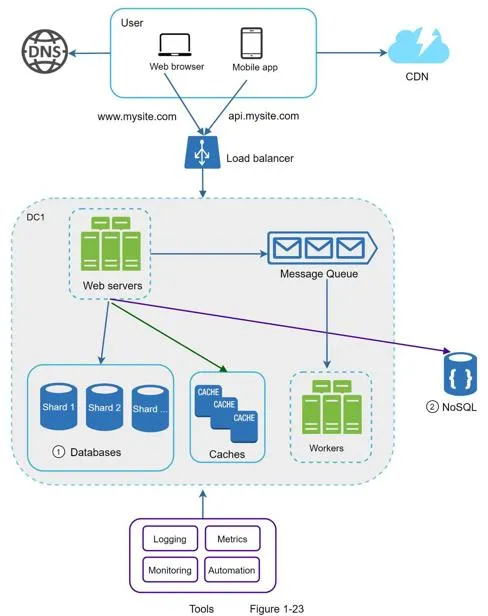
Summary: scaling to millions of users
- Keep web tier stateless
- Build redundancy at every tier
- Cache data as much as you can
- Support multiple data centers
- Host static assets in CDN
- Scale data tier by sharding
- Split tiers into individual services
- Monitor your system and use automation tools
Reference materials
[1] Hypertext Transfer Protocol: https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol [2] Should you go Beyond Relational Databases?: https://blog.teamtreehouse.com/should-you-go-beyond-relational-databases [3] Replication: https://en.wikipedia.org/wiki/Replication_(computing) [4] Multi-master replication: https://en.wikipedia.org/wiki/Multi-master_replication [5] NDB Cluster Replication: Multi-Master and Circular Replication: https://dev.mysql.com/doc/refman/5.7/en/mysql-cluster-replication-multi-master.html [6] Caching Strategies and How to Choose the Right One: https://codeahoy.com/2017/08/11/caching-strategies-and-how-to-choose-the-right-one/ [7] R. Nishtala, "Facebook, Scaling Memcache at," 10th USENIX Symposium on Networked Systems Design and Implementation (NSDI '13). [8] Single point of failure: https://en.wikipedia.org/wiki/Single_point_of_failure [9] Amazon CloudFront Dynamic Content Delivery: https://aws.amazon.com/cloudfront/dynamic-content/ [10] Configure Sticky Sessions for Your Classic Load Balancer: https://docs.aws.amazon.com/elasticloadbalancing/latest/classic/elb-sticky-sessions.html [11] Active-Active for Multi-Regional Resiliency: https://netflixtechblog.com/active-active-for-multi-regional-resiliency-c47719f6685b [12] Amazon EC2 High Memory Instances: https://aws.amazon.com/ec2/instance-types/high-memory/ [13] What it takes to run Stack Overflow: http://nickcraver.com/blog/2013/11/22/what-it-takes-to-run-stack-overflow [14] What The Heck Are You Actually Using NoSQL For: http://highscalability.com/blog/2010/12/6/what-the-heck-are-you-actually-using-nosql-for.html