Design a Rate Limiter
6 min readA rate limiter controls the rate of traffic sent by a client or service. In HTTP, it limits client requests allowed over a specified period; excess calls are blocked. Examples:
- Max 2 posts per second per user
- Max 10 accounts per day from same IP
- Max 5 reward claims per week from same device
Benefits:
- Prevent resource starvation from DoS attacks (Twitter: 300 tweets/3h; Google Docs: 300 read reqs/60s per user)
- Reduce cost (fewer servers, limiting paid 3rd-party API calls)
- Prevent server overload from bots/user misbehavior
Step 1 — Understand the problem and establish design scope
Requirements:
- Server-side API rate limiter
- Flexible throttle rules (by IP, user ID, etc.)
- Handles large request volume
- Works in distributed environment
- Informs users when throttled
System requirements:
- Accurately limit excessive requests
- Low latency (no HTTP slowdown)
- Use as little memory as possible
- Distributed rate limiting (across multiple servers/processes)
- Return clear exceptions to throttled users
- High fault tolerance (cache server offline shouldn't break entire system)
Step 2 — Propose high-level design and get buy-in
Where to put the rate limiter?
Client-side: Unreliable — requests easily forged by malicious actors, no control over client implementation.
Server-side:
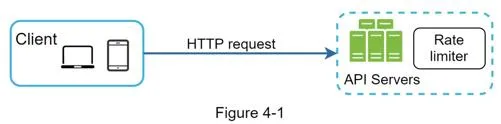
Middleware approach (API gateway):
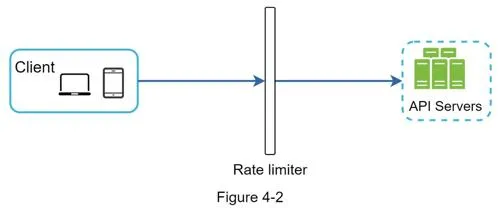
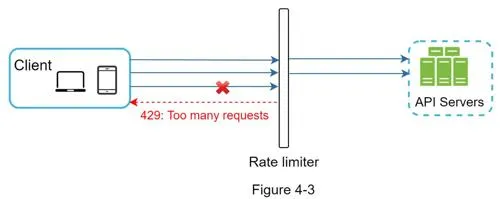
Example: API allows 2 req/s. Client sends 3 requests in a second → first 2 routed to API servers, 3rd throttled with HTTP 429.
Decision factors:
- Current technology stack (language, cache service)
- Algorithm control (full control server-side vs limited with 3rd-party gateway)
- Existing microservice architecture + API gateway → add rate limiter to gateway
- Engineering resources → build vs buy commercial API gateway
Algorithms for rate limiting
Token bucket algorithm
Used by Amazon and Stripe.
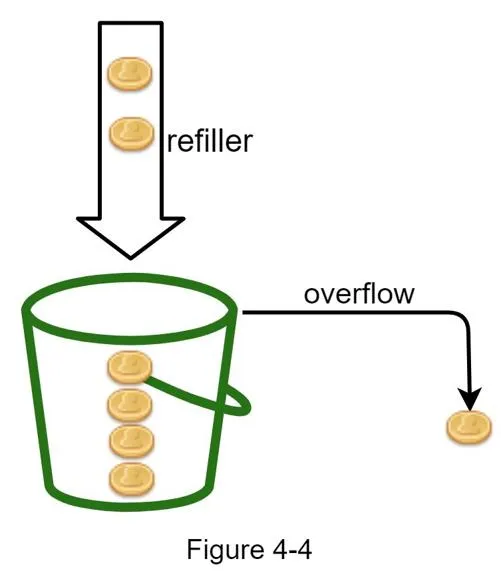
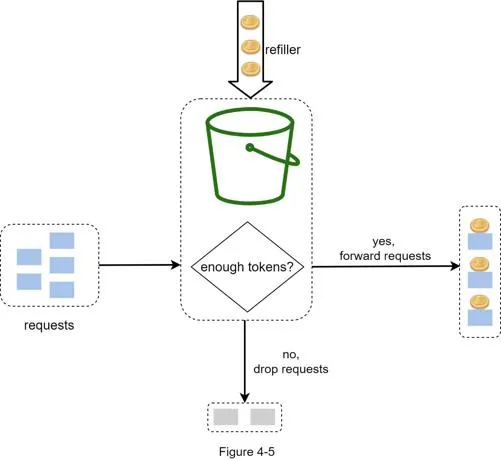
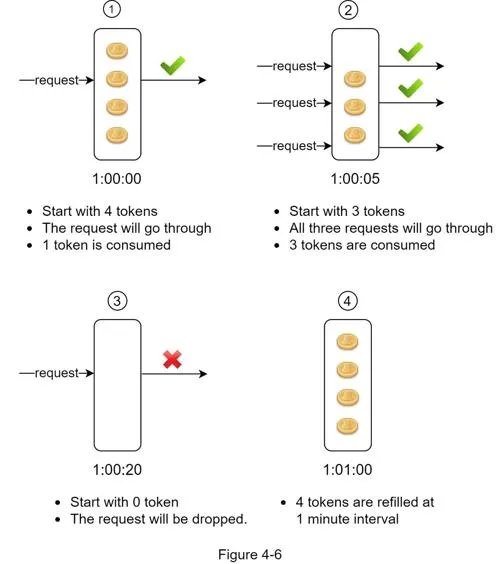
How it works: Bucket with predefined capacity. Tokens added at preset rate periodically. Each request consumes one token. No tokens → request dropped.
Parameters: Bucket size, refill rate.
Buckets needed: Per API endpoint, per IP address, global bucket (10,000 req/s).
Pros: Easy to implement, memory efficient, allows burst traffic. Cons: Two parameters challenging to tune properly.
Leaking bucket algorithm
Used by Shopify. Implemented with FIFO queue.
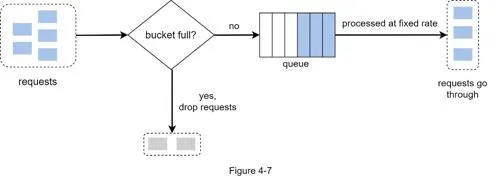
How it works: Request arrives → check if queue full → if not, add to queue; otherwise drop. Requests pulled from queue at fixed rate.
Parameters: Bucket size (queue size), outflow rate.
Pros: Memory efficient, fixed rate suitable for stable outflow use cases. Cons: Burst traffic fills queue with old requests, starving recent ones. Two parameters hard to tune.
Fixed window counter algorithm
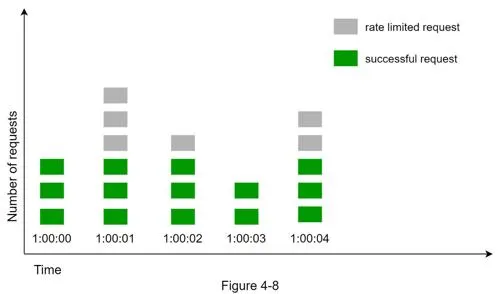
How it works: Divide timeline into fixed windows, each with a counter. Each request increments counter. Counter reaches threshold → new requests dropped until new window.
Critical flaw: Traffic spikes at window edges let double the allowed requests through.
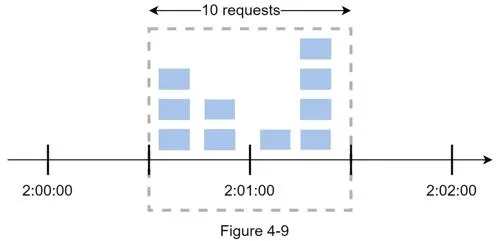
Example: 5 req/min allowed, but in a rolling window from 2:00:30 to 2:01:30, 10 requests pass — twice the limit.
Pros: Memory efficient, easy to understand, quota reset fits certain use cases. Cons: Spike at window edges allows excess requests.
Sliding window log algorithm
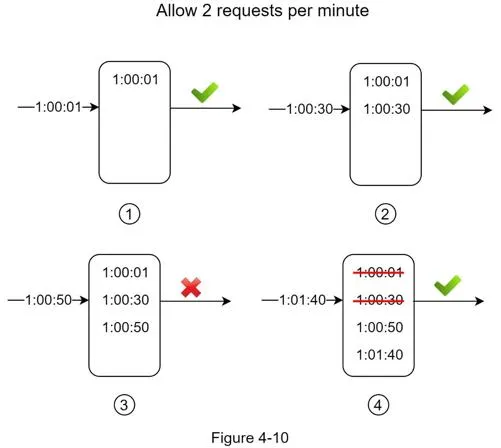
How it works: Track request timestamps (e.g., Redis sorted sets). On new request: remove outdated timestamps (older than window start), add new timestamp, check if log size ≤ allowed count.
Example: 2 req/min allowed. Requests at 1:00:01 ✓, 1:00:30 ✓, 1:00:50 ✗ (log=3 > 2). At 1:01:40, outdated 1:00:01 and 1:00:30 removed, log=2, request accepted.
Pros: Very accurate — no request will exceed rate limit in any rolling window. Cons: High memory usage (rejected request timestamps still stored).
Sliding window counter algorithm
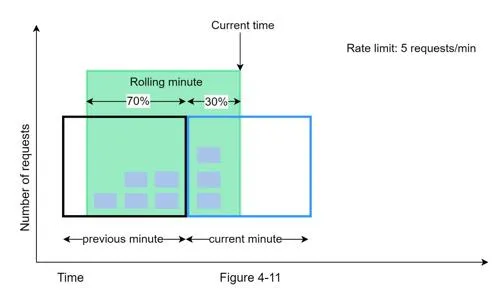
Hybrid of fixed window counter and sliding window log. Formula:
Requests in rolling window = current_window_count + previous_window_count × overlap_percentage
Example: Max 7 req/min. Previous window: 5 requests, current window: 3 requests. New request at 30% into current window → 3 + 5 × 0.7 = 6.5 → rounded to 6. Request accepted.
Pros: Smooths traffic spikes (average rate of previous window), memory efficient. Cons: Approximation (assumes even distribution in previous window). Cloudflare experiment: only 0.003% of requests incorrectly allowed/blocked among 400M.
High-level architecture
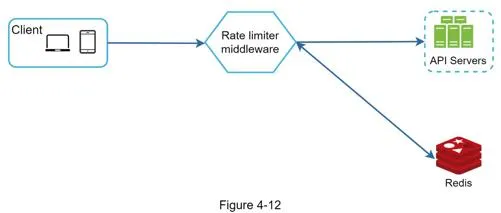
Store counters in in-memory cache (Redis) using INCR (increment counter) and EXPIRE (set timeout for auto-deletion). Flow:
- Client → rate limiting middleware
- Middleware checks counter from Redis bucket
- Limit reached → reject request
- Not reached → forward to API servers, increment counter in Redis
Step 3 — Design deep dive
Rate limiting rules
Configuration in files on disk (Lyft example):
domain: messaging
descriptors:
- key: message_type
value: marketing
rate_limit:
unit: day
requests_per_unit: 5
Exceeding the rate limit
Return HTTP 429 (too many requests). May enqueue rate-limited requests for later processing (e.g., orders during system overload).
Rate limiter HTTP headers:
X-Ratelimit-Remaining: remaining allowed requests in windowX-Ratelimit-Limit: max calls per time windowX-Ratelimit-Retry-After: seconds to wait before retry
Detailed design
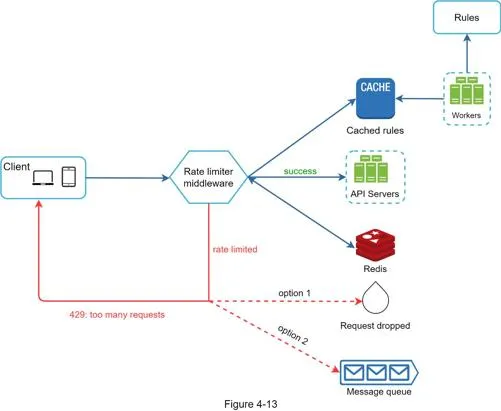
- Rules stored on disk, workers pull into cache
- Client request → rate limiter middleware → loads rules from cache → fetches counters/timestamps from Redis → decides: forward to API servers or return 429 (request dropped or queued)
Rate limiter in a distributed environment
Race condition
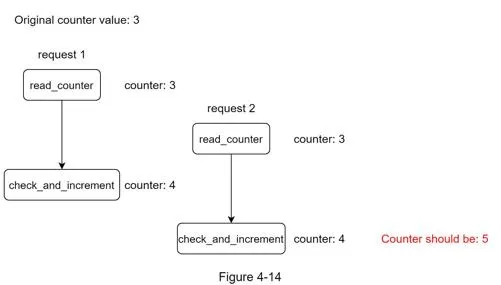
Counter value is 3. Two concurrent threads both read 3, both increment to 4, both write 4. Correct value should be 5.
Solutions: Lua scripts or Redis sorted sets (locks slow down system).
Synchronization issue
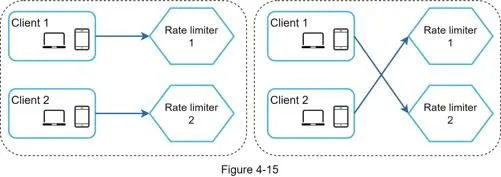
Multiple rate limiter servers: Client 1 → limiter 1, Client 2 → limiter 2. Without synchronization, limiter 1 has no data about client 2.
Bad solution: Sticky sessions (not scalable/flexible). Good solution: Centralized data store (Redis).
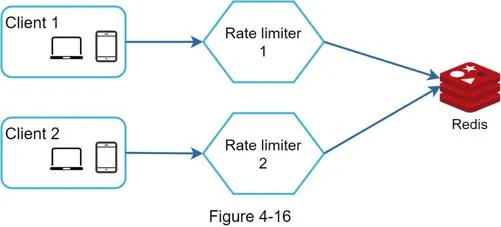
Performance optimization
- Multi-data center setup: Route traffic to closest edge server (Cloudflare: 194 edge locations as of 2020) to reduce latency.
- Eventual consistency model for data synchronization.
Monitoring
Verify:
- Rate limiting algorithm is effective
- Rate limiting rules are effective (not too strict, handle traffic surges)
Step 4 — Wrap up
Algorithms covered: Token bucket, leaking bucket, fixed window, sliding window log, sliding window counter.
Additional talking points:
- Hard vs soft rate limiting (hard: never exceed; soft: exceed briefly)
- Rate limiting at different OSI layers (application layer 7 HTTP shown; possible at layer 3 IP via Iptables)
- Client best practices: cache to avoid frequent calls, understand limits, catch exceptions gracefully, add backoff time to retry logic
Reference materials
[1] Rate-limiting strategies and techniques: https://cloud.google.com/solutions/rate-limiting-strategies-techniques [2] Twitter rate limits: https://developer.twitter.com/en/docs/basics/rate-limits [3] Google docs usage limits: https://developers.google.com/docs/api/limits [4] IBM microservices: https://www.ibm.com/cloud/learn/microservices [5] Throttle API requests for better throughput: https://docs.aws.amazon.com/apigateway/latest/developerguide/api-gateway-request-throttling.html [6] Stripe rate limiters: https://stripe.com/blog/rate-limiters [7] Shopify REST Admin API rate limits: https://help.shopify.com/en/api/reference/rest-admin-api-rate-limits [8] Better Rate Limiting With Redis Sorted Sets: https://engineering.classdojo.com/blog/2015/02/06/rolling-rate-limiter/ [9] System Design — Rate limiter and Data modelling: https://medium.com/@saisandeepmopuri/system-design-rate-limiter-and-data-modelling-9304b0d18250 [10] How we built rate limiting capable of scaling to millions of domains: https://blog.cloudflare.com/counting-things-a-lot-of-different-things/ [11] Redis website: https://redis.io/ [12] Lyft rate limiting: https://github.com/lyft/ratelimit [13] Scaling your API with rate limiters: https://gist.github.com/ptarjan/e38f45f2dfe601419ca3af937fff574d#request-rate-limiter [14] What is edge computing: https://www.cloudflare.com/learning/serverless/glossary/what-is-edge-computing/ [15] Rate Limit Requests with Iptables: https://blog.programster.org/rate-limit-requests-with-iptables [16] OSI model: https://en.wikipedia.org/wiki/OSI_model#Layer_architecture