Design Consistent Hashing
3 min readConsistent hashing distributes requests/data efficiently across servers for horizontal scaling, minimizing redistribution when servers are added/removed.
The rehashing problem
Traditional approach: serverIndex = hash(key) % N where N = server count.
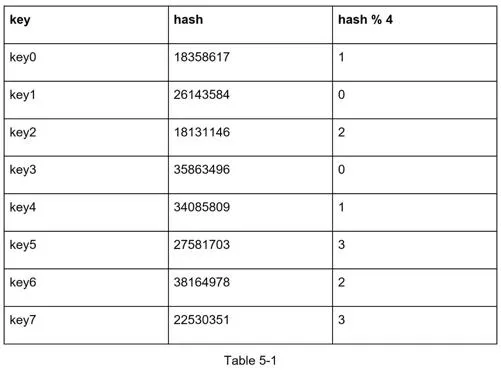
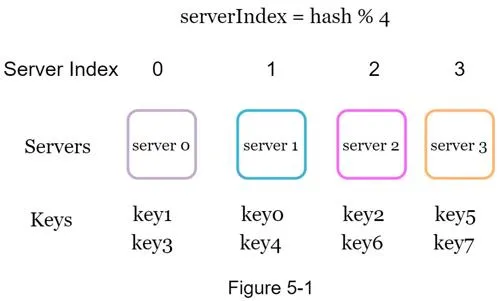
When N changes (server added/removed), most keys get different server indexes — not just the keys from the affected server. This causes a storm of cache misses.
Example: Server 1 goes offline (N=4 → N=3).
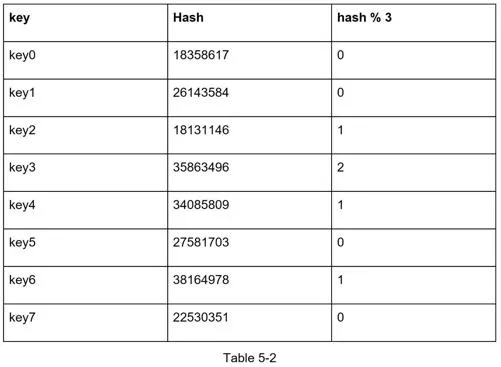
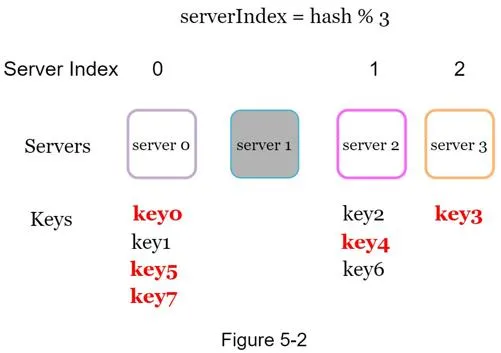
Most keys are redistributed to different servers even if they weren't stored on server 1.
Consistent hashing
Only k/n keys need remapping on average (k = keys, n = slots), vs nearly all keys with traditional hashing.
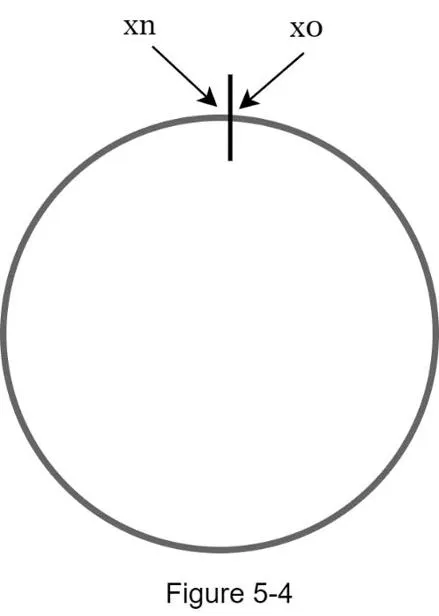
Hash space and hash ring
Using SHA-1 (hash space 0 to 2^160 − 1):

Connect both ends → hash ring:
Hash servers
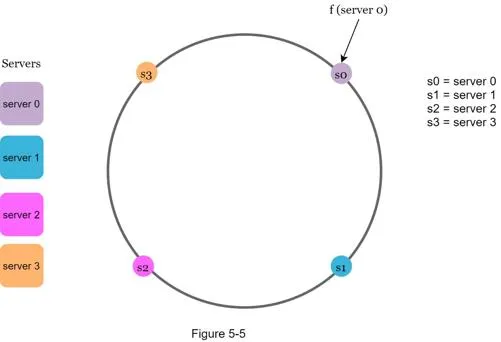
Map servers onto ring by hashing IP or name:
Hash keys
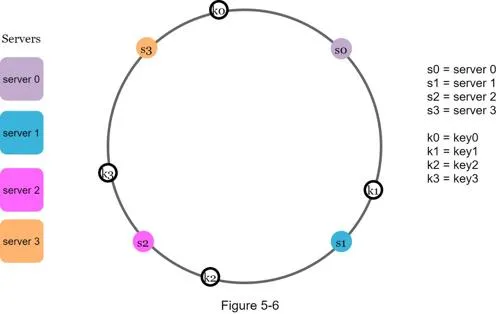
Hash cache keys onto the same ring (no modular operation):
Server lookup
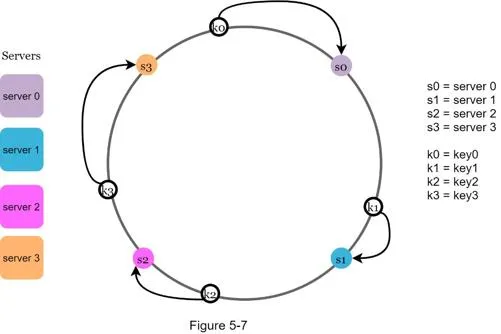
To find which server stores a key: go clockwise from key's position until a server is found.
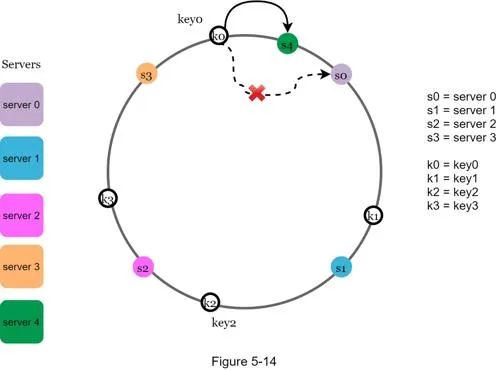
Add a server
Only keys between the new server and its predecessor (anticlockwise) need redistribution.
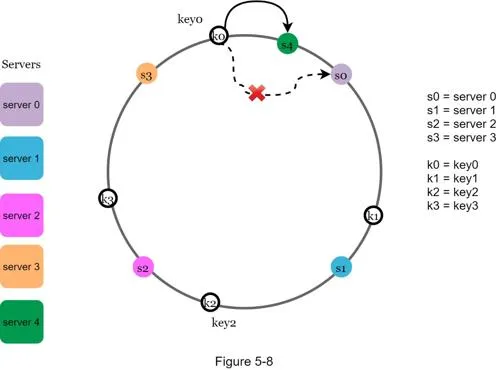
After adding server 4: only key0 redistributed (moves from server 0 to server 4). k1, k2, k3 stay.
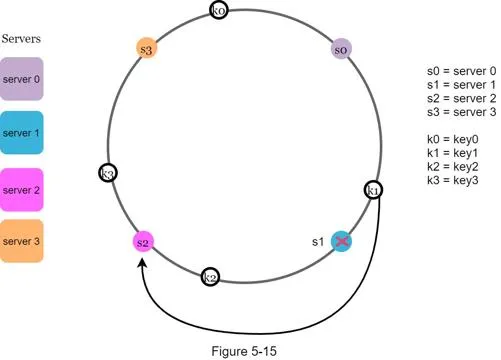
Remove a server
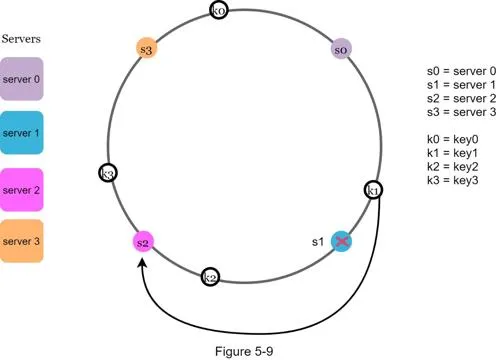
When server 1 removed: only key1 remapped (to server 2). Others unaffected.
Two issues in the basic approach
- Uneven partition sizes: Partitions between adjacent servers can vary greatly. If s1 removed, s2's partition becomes twice the size of s0 and s3.
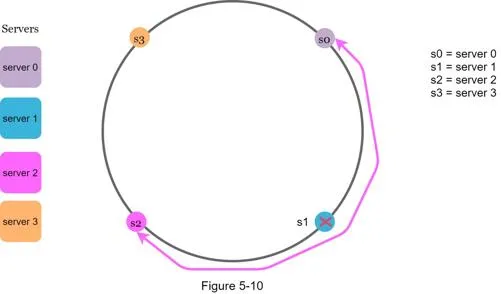
- Non-uniform key distribution: Keys may cluster on specific servers, leaving others empty.
Virtual nodes
Each physical server represented by multiple virtual nodes on the ring.
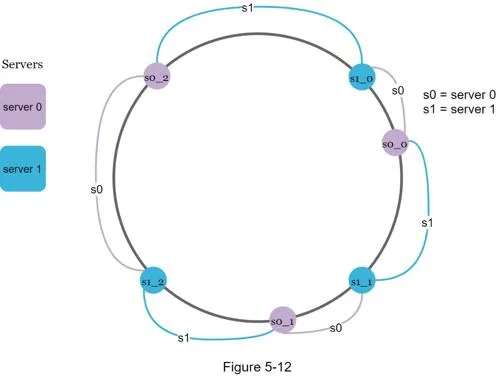
- Server 0 → s0_0, s0_1, s0_2; Server 1 → s1_0, s1_1, s1_2
- Each server responsible for multiple partitions
- Lookup: go clockwise from key to first virtual node → maps to physical server
Tradeoff: More virtual nodes = more balanced distribution, smaller standard deviation. But more memory to store virtual node data.
- 100–200 virtual nodes → standard deviation 5–10% of mean
- More virtual nodes → smaller standard deviation
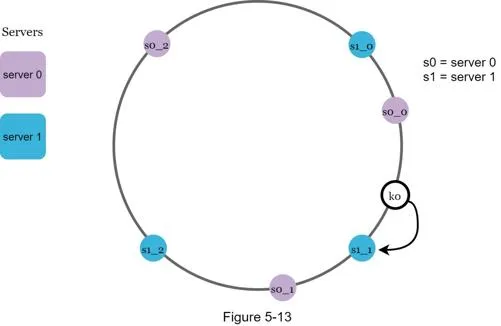
Find affected keys
Adding server 4: Affected range starts from s4, goes anticlockwise to next server (s3). Keys between s3 and s4 redistributed to s4.
Removing server 1: Affected range starts from s1, goes anticlockwise to next server (s0). Keys between s0 and s1 redistributed to s2.
Wrap up
Benefits:
- Minimized keys redistributed when servers added/removed
- Easy horizontal scaling with even data distribution
- Mitigates hotspot key problem (e.g., celebrity shard overload)
Real-world usage:
- Partitioning in Amazon's Dynamo database
- Data partitioning in Apache Cassandra
- Discord chat application
- Akamai CDN
- Maglev network load balancer
Reference materials
[1] Consistent hashing: https://en.wikipedia.org/wiki/Consistent_hashing [2] Consistent Hashing: https://tom-e-white.com/2007/11/consistent-hashing.html [3] Dynamo: Amazon's Highly Available Key-value Store: https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf [4] Cassandra - A Decentralized Structured Storage System: http://www.cs.cornell.edu/Projects/ladis2009/papers/Lakshman-ladis2009.PDF [5] How Discord Scaled Elixir to 5,000,000 Concurrent Users: https://blog.discord.com/scaling-elixir-f9b8e1e7c29b [6] CS168: The Modern Algorithmic Toolbox Lecture #1: Introduction and Consistent Hashing: http://theory.stanford.edu/~tim/s16/l/l1.pdf [7] Maglev: A Fast and Reliable Software Network Load Balancer: https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/44824.pdf