Proximity Service
7 min readDesign a proximity service to discover nearby places (restaurants, hotels, etc.) on Yelp or Google Maps.
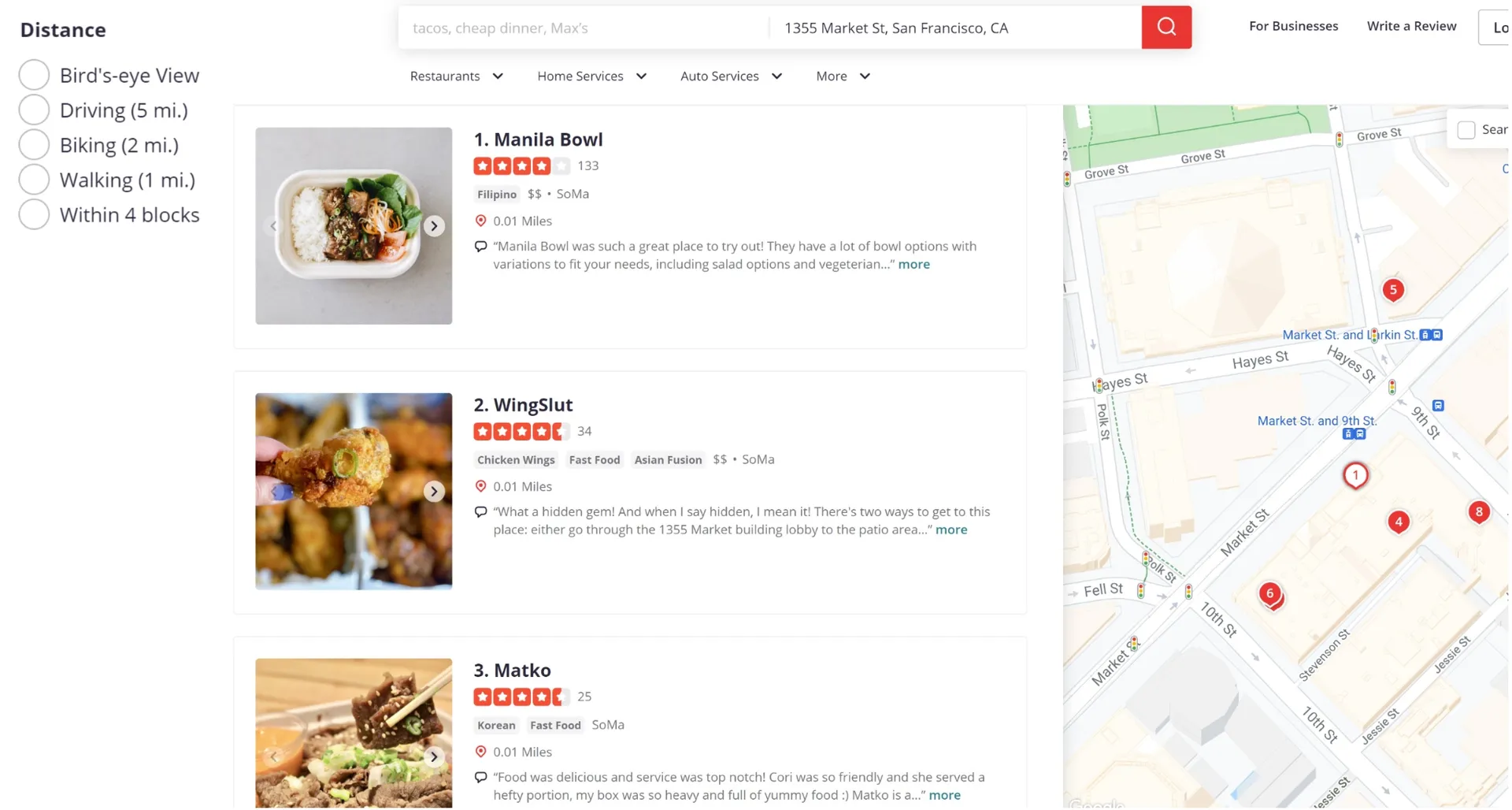
Figure 1 Nearby search on Yelp
Step 1 - Understand the Problem and Establish Design Scope
Functional requirements
- Return all businesses based on user's location (lat/lng) and radius.
- Business owners can add/delete/update a business; updates effective next day (not real-time).
- Customers can view detailed information about a business.
- Search radius options: 0.5km, 1km, 2km, 5km, 20km. Max radius: 20km.
- User's moving speed is slow; no constant page refresh needed.
Non-functional requirements
- Low latency for nearby business search.
- Data privacy: comply with GDPR, CCPA.
- High availability and scalability for peak hours in dense areas.
Back-of-the-envelope estimation
- 100M DAU, 200M businesses.
- 5 search queries per user per day.
- Search QPS = 100M × 5 / 10⁵ = ~5,000.
Step 2 - Propose High-Level Design and Get Buy-In
API Design
GET /v1/search/nearby — returns businesses based on search criteria (paginated).
| Field | Description | Type |
|---|---|---|
| latitude | Latitude of location | decimal |
| longitude | Longitude of location | decimal |
| radius | Optional, default 5000m | int |
Business CRUD APIs:
| API | Detail |
|---|---|
| GET /v1/businesses/{:id} | Return detailed business info |
| POST /v1/businesses | Add a business |
| PUT /v1/businesses/{:id} | Update business details |
| DELETE /v1/businesses/{:id} | Delete a business |
Data model
- Read/write ratio: Read-heavy (search + detail views), write volume low (infrequent business edits).
- Business table: Primary key =
business_id.

Table 3 Business table
- Geo index table: For efficient spatial operations (discussed in deep dive).
High-level design
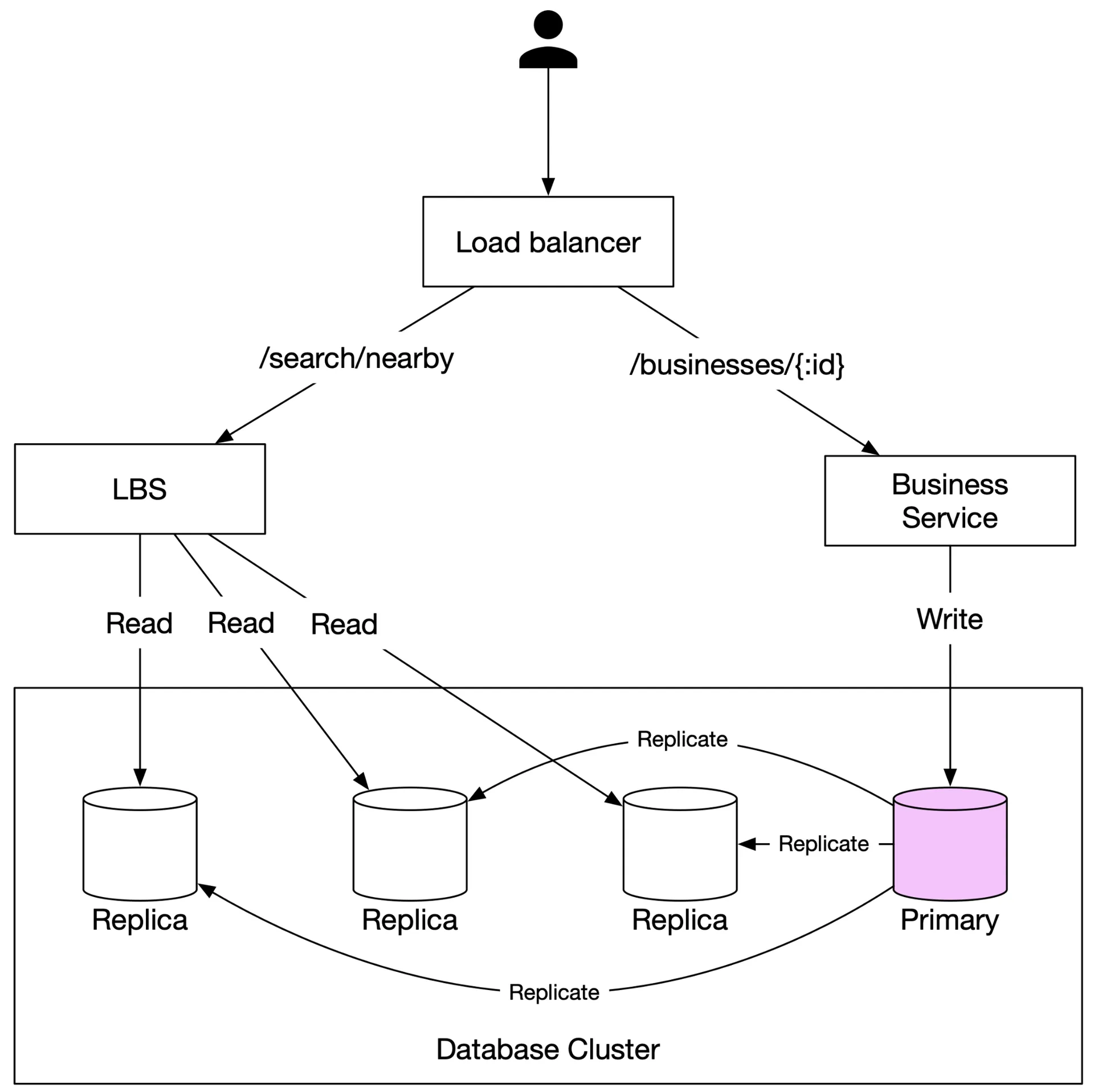
Figure 2 High-level design
- Load balancer: Distributes traffic across services; single DNS entry routes to appropriate services by URL path.
- LBS (Location-Based Service): Read-heavy, stateless, horizontally scalable. No write requests. High QPS at peak.
- Business service: Handles CRUD (low QPS writes) + detail views (high QPS reads).
- Database cluster: Primary-secondary setup. Primary handles writes; replicas for reads. Replication lag acceptable for non-real-time business data.
- Scalability: Auto-scale for peak (mealtimes), scale down off-peak; multi-region deployment on cloud.
Algorithms to fetch nearby businesses
Options: even grid, geohash, cartesian tiers (hash-based); quadtree, Google S2, RTree (tree-based).
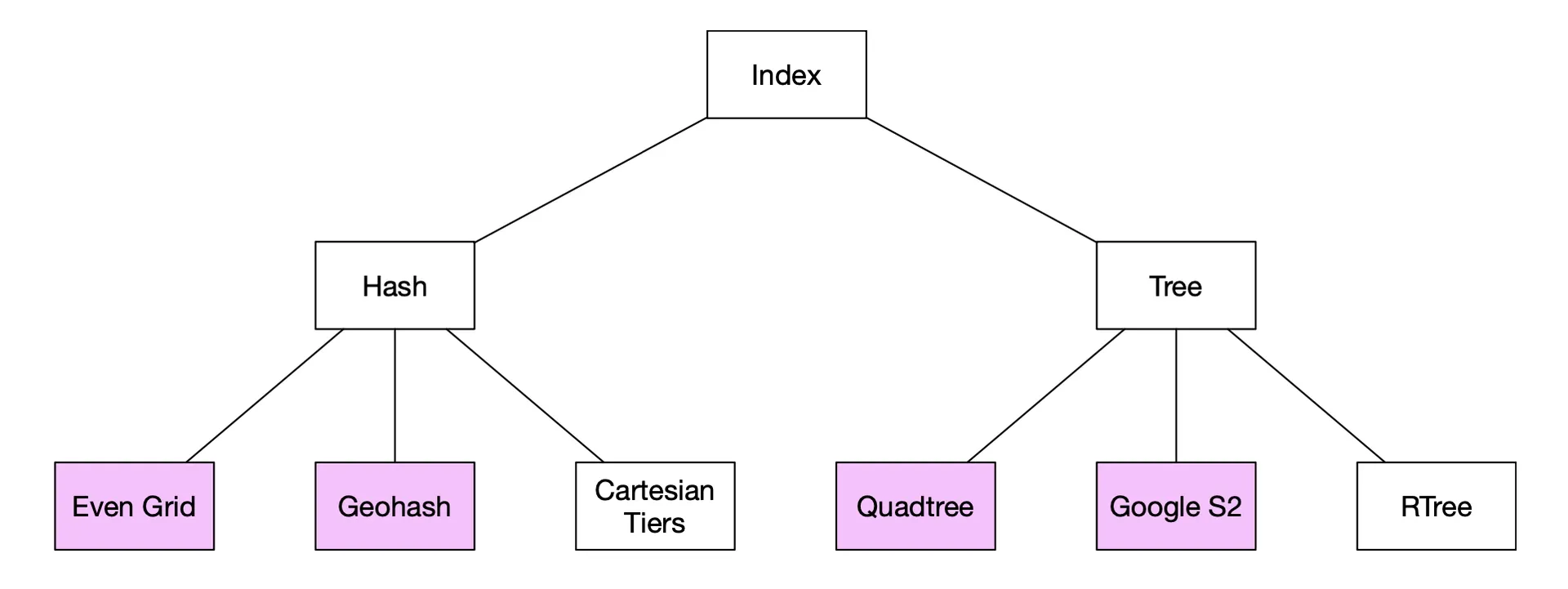
Figure 5 Geospatial index types
All divide the map into smaller areas and build indexes for fast search. Geohash, quadtree, and Google S2 are most widely used.
Option 1: Two-dimensional search (naive)
Draw a circle with radius, find all businesses within it. Inefficient — requires full table scan. Indexes on lat/lng columns help but the intersect of two large 1D datasets is still slow.
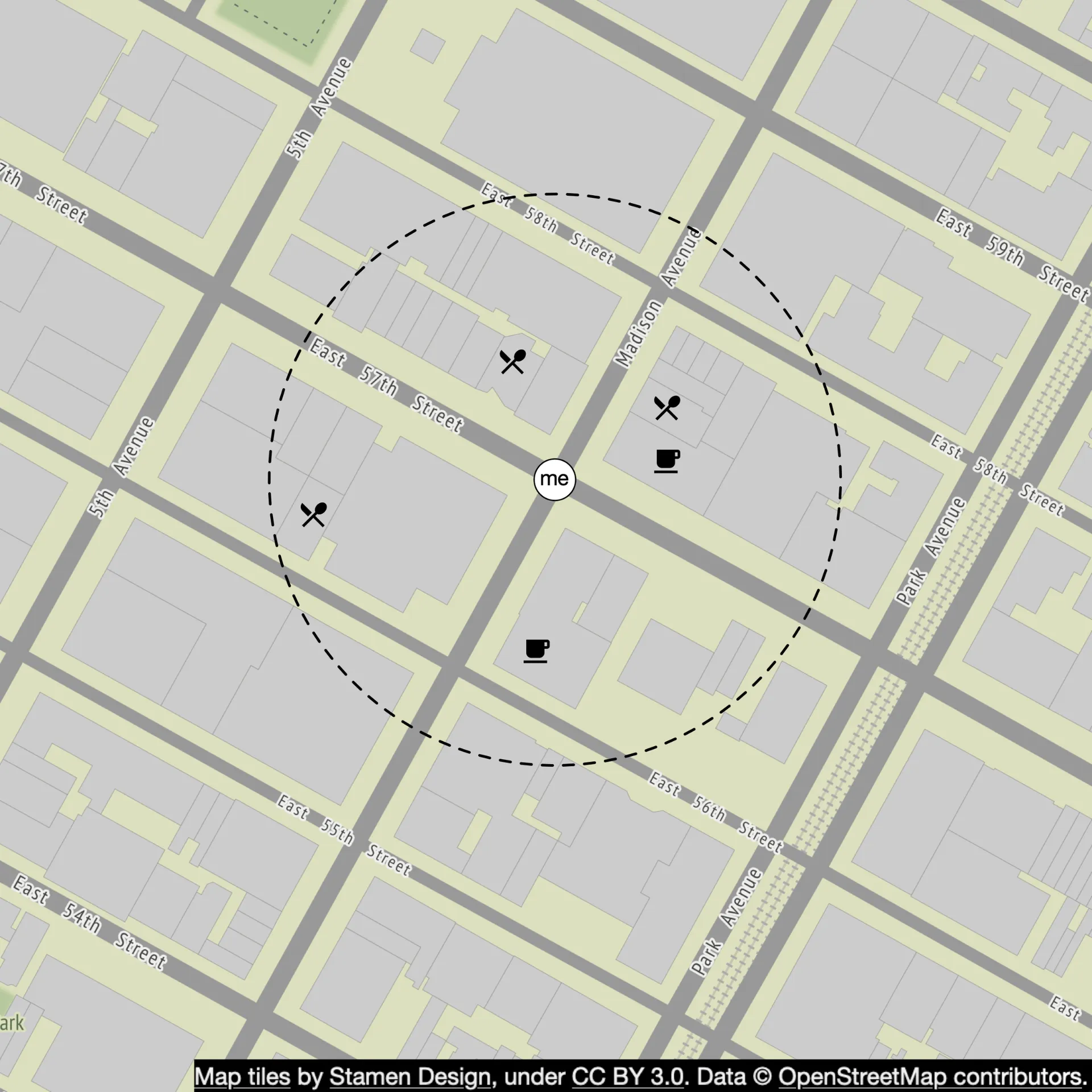
Option 2: Evenly divided grid
Divide world into even grids. Problem: uneven business distribution (dense in NYC, empty in deserts). Need adaptive granularity.
Option 3: Geohash
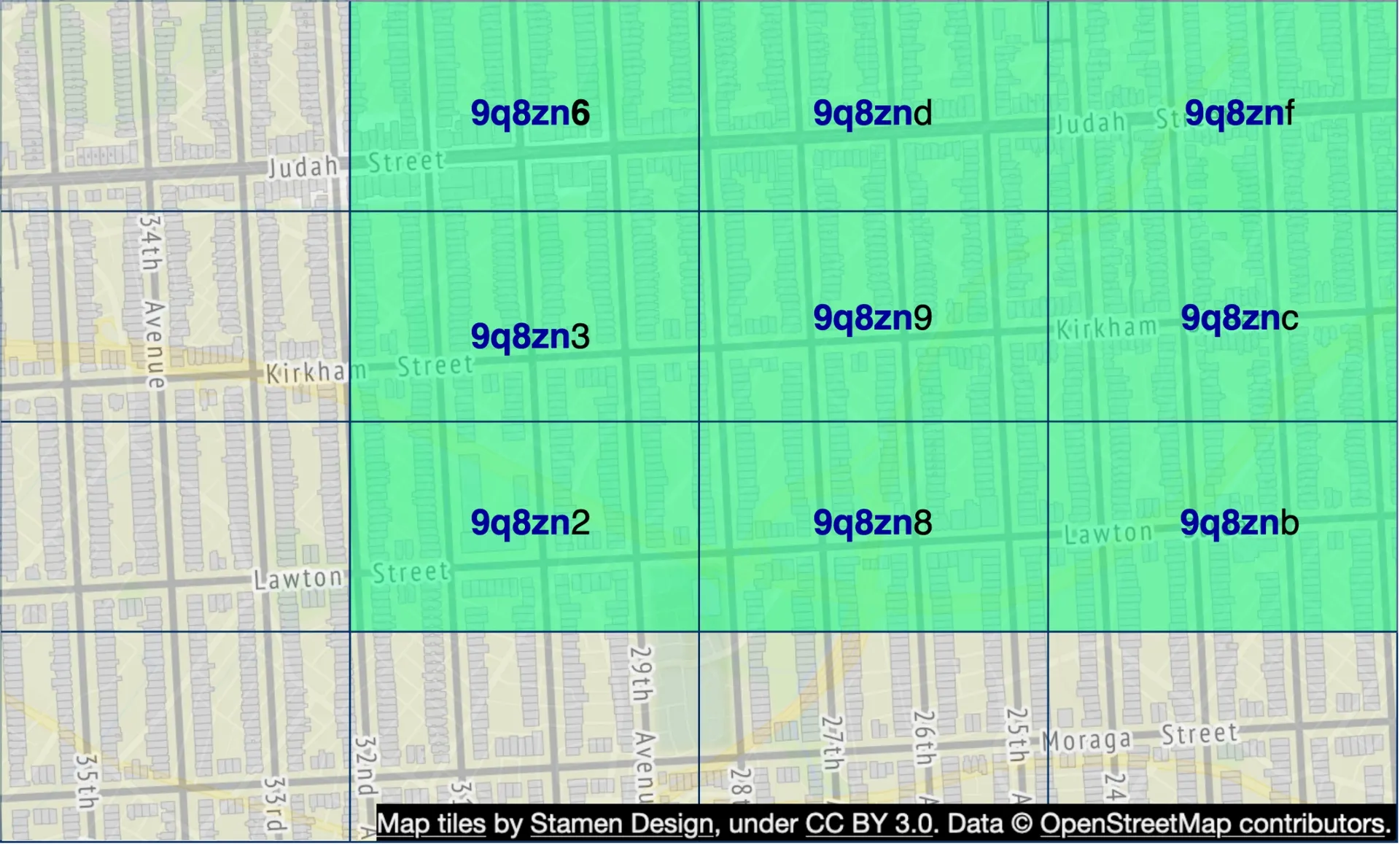
Reduces 2D lat/lng to a 1D string. Recursively subdivides world into quadrants, each additional bit = finer precision. Uses base32 representation.
Examples: Google HQ → 9q9hvu, Facebook HQ → 9q9jhr.
Geohash precision table:
| Length | Grid size |
|---|---|
| 1 | 5,009km × 4,993km |
| 2 | 1,252km × 624km |
| 3 | 156.5km × 156km |
| 4 | 39.1km × 19.5km |
| 5 | 4.9km × 4.9km |
| 6 | 1.2km × 609.4m |
| 7 | 152.9m × 152.4m |
| 8 | 38.2m × 19m |
Useful lengths: 4–6 (longer → too small; shorter → too large).
Radius → geohash mapping:
| Radius | Geohash length |
|---|---|
| 0.5 km | 6 |
| 1 km | 5 |
| 2 km | 5 |
| 5 km | 4 |
| 20 km | 4 |
Boundary issues:
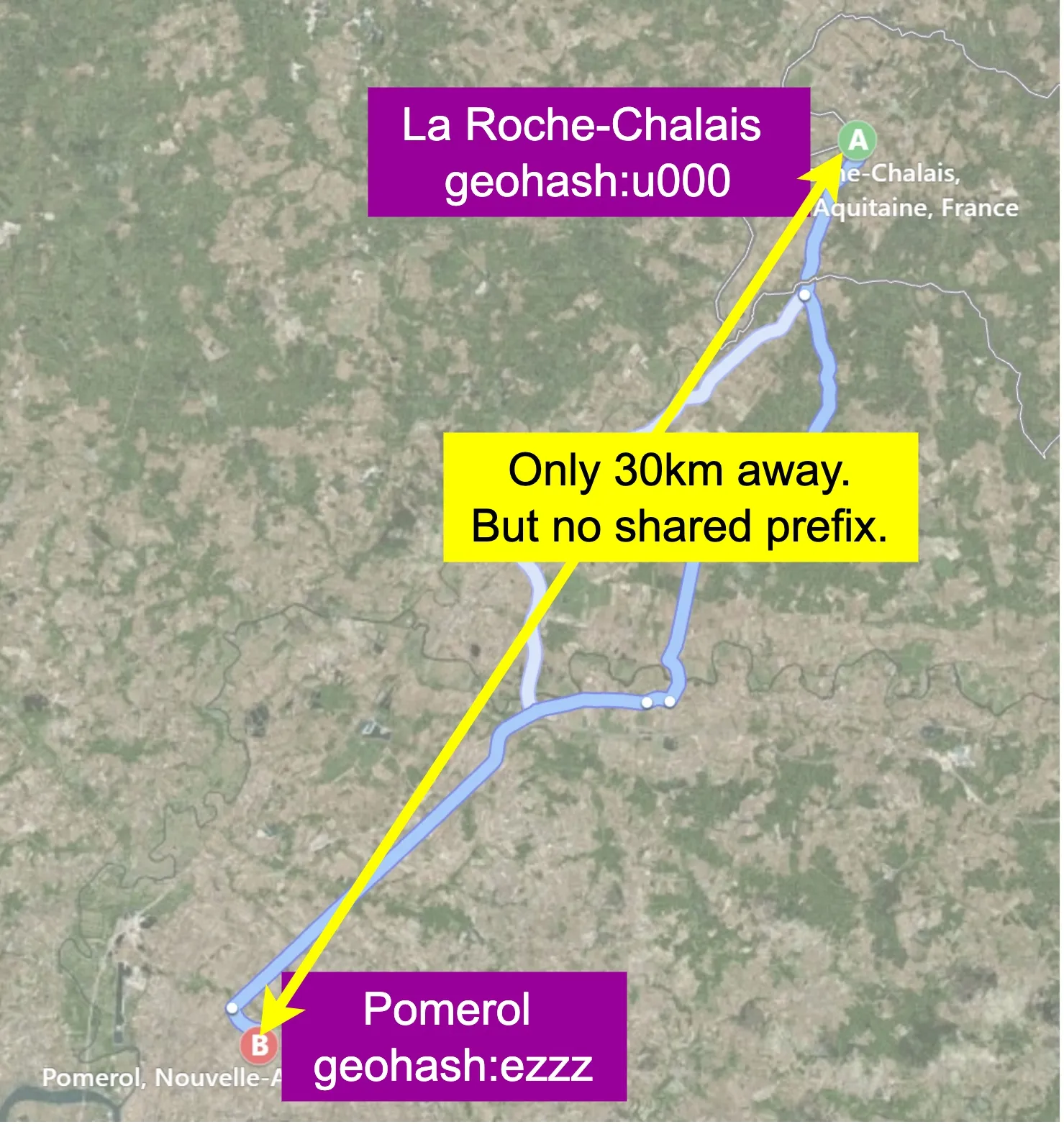
- Two close locations on opposite sides of equator/meridian share no prefix (e.g.,
u000andezzz30km apart in France). - Long shared prefix doesn't guarantee same grid — must also query neighbor grids.
- Solution: fetch from current grid + all 8 neighbors. Neighbor geohashes computable in constant time.
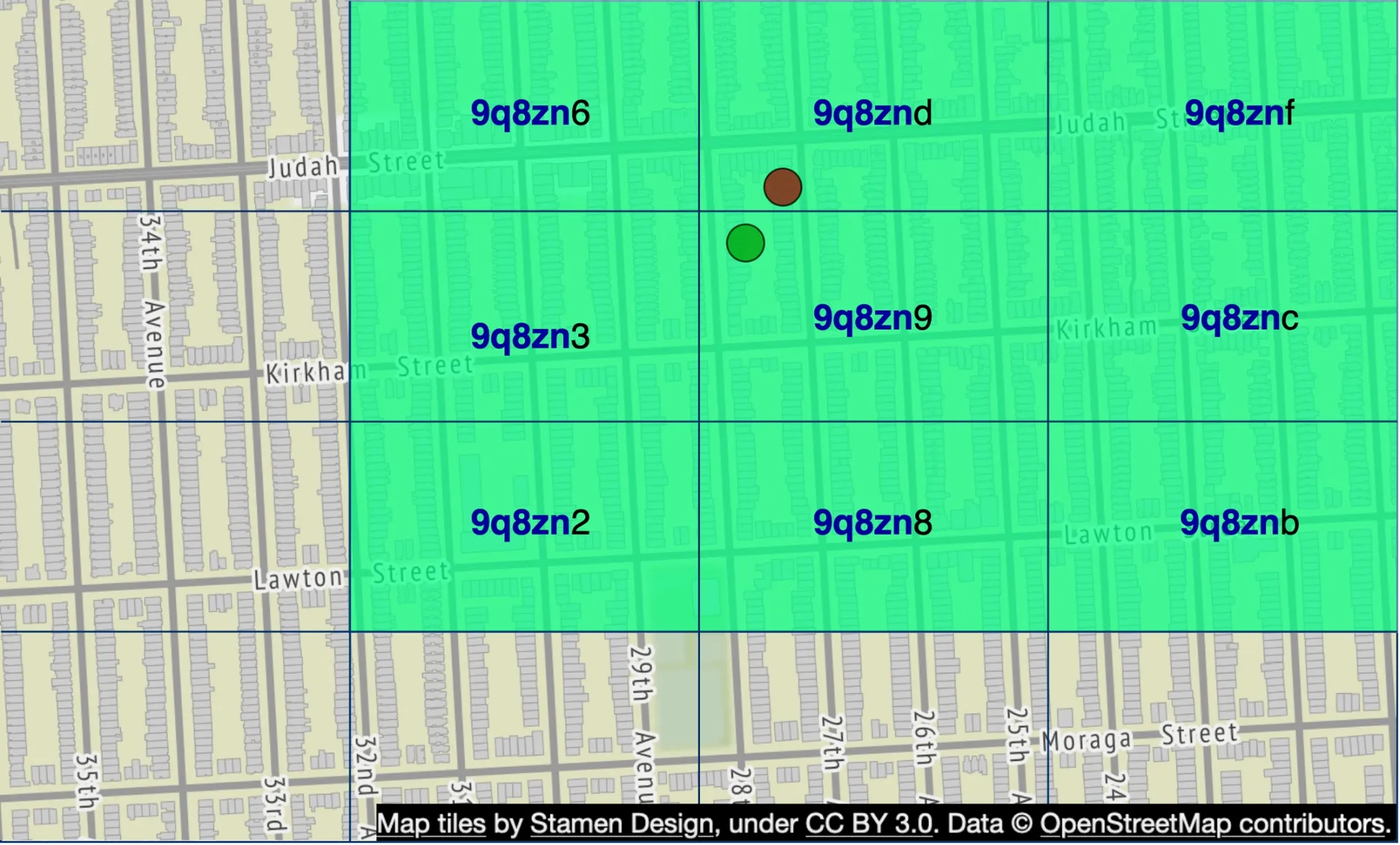
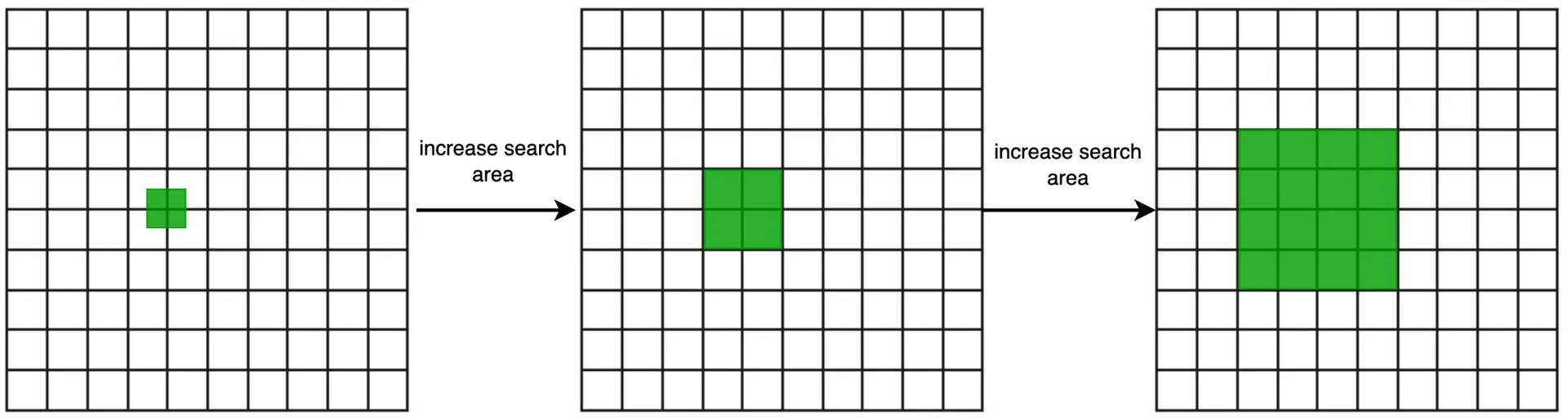
Not enough businesses: Remove last geohash digit to expand search radius gradually until enough results returned.
Option 4: Quadtree
In-memory data structure (NOT a database). Recursively subdivides 2D space into 4 quadrants until grid has ≤ N businesses (e.g., ≤100).

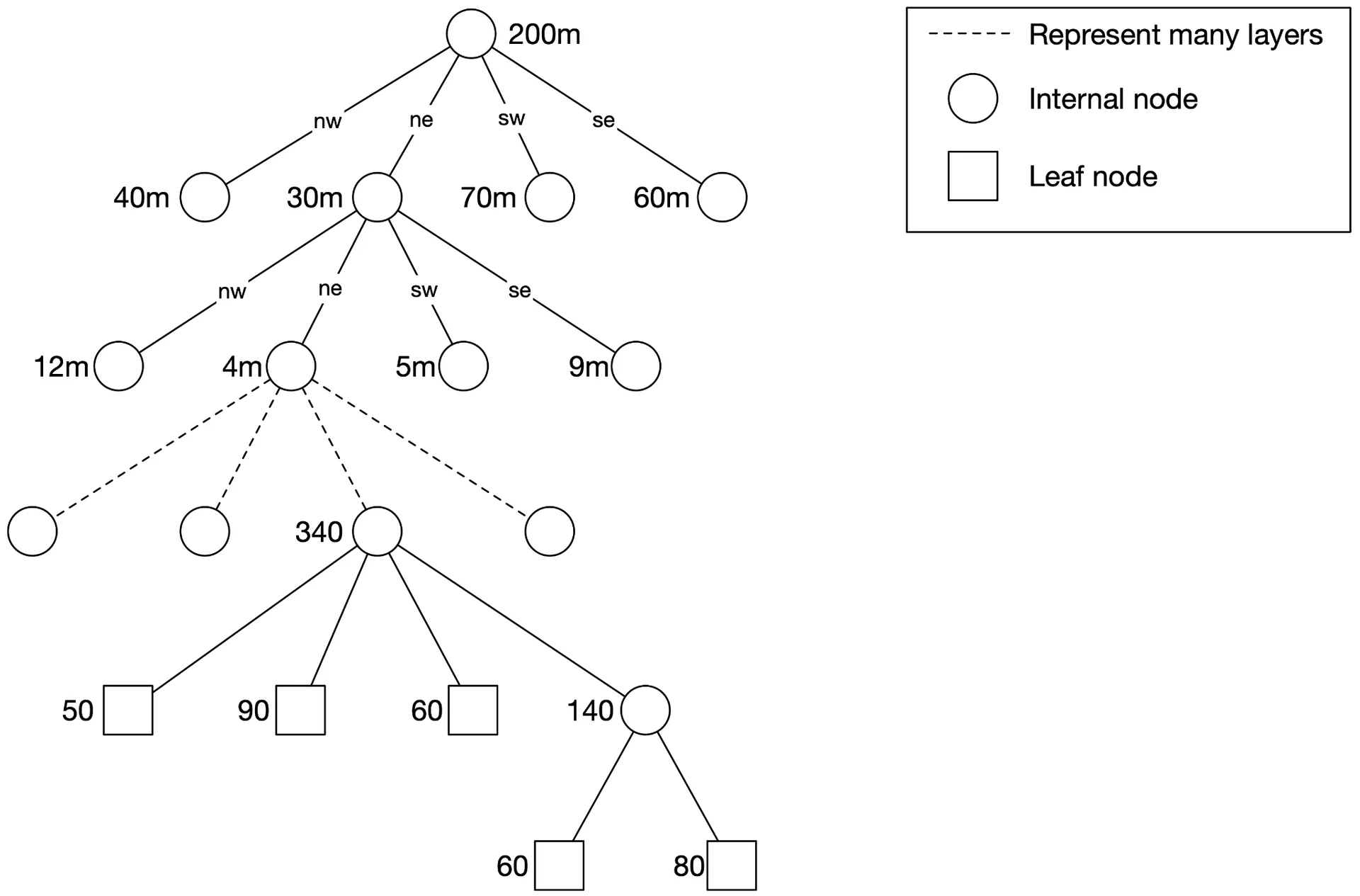
Memory estimation (200M businesses):
- Leaf nodes: ~200M / 100 = ~2M
- Internal nodes: ~0.67M (≈ 1/3 of leaf nodes)
- Leaf node size: 832 bytes (32B coords + 8B × 100 business IDs)
- Internal node size: 64 bytes (32B coords + 32B child pointers)
- Total: ~1.71 GB — fits in one server's memory.
Build time: O(n/100 log(n/100)) — several minutes for 200M businesses.
Operational considerations:
- Long server start-up → incremental rollout (subset of servers at a time) or blue/green deployment.
- Updates: nightly rebuild (acceptable per "next day effective" agreement). On-the-fly update requires locking → complex.
- Quadtree supports k-nearest queries (unlike geohash's fixed radius). Dynamically adjusts grid size by density.
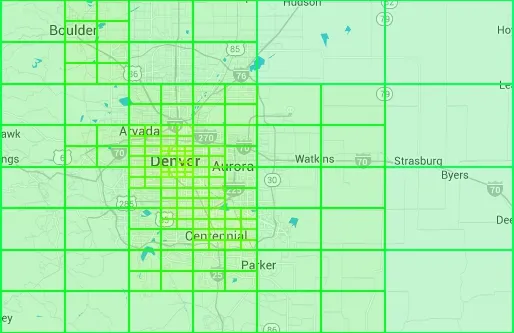 — Real-world quadtree near Denver
— Real-world quadtree near Denver
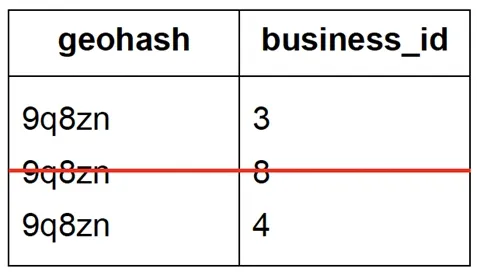 — Remove a business from geohash index
— Remove a business from geohash index
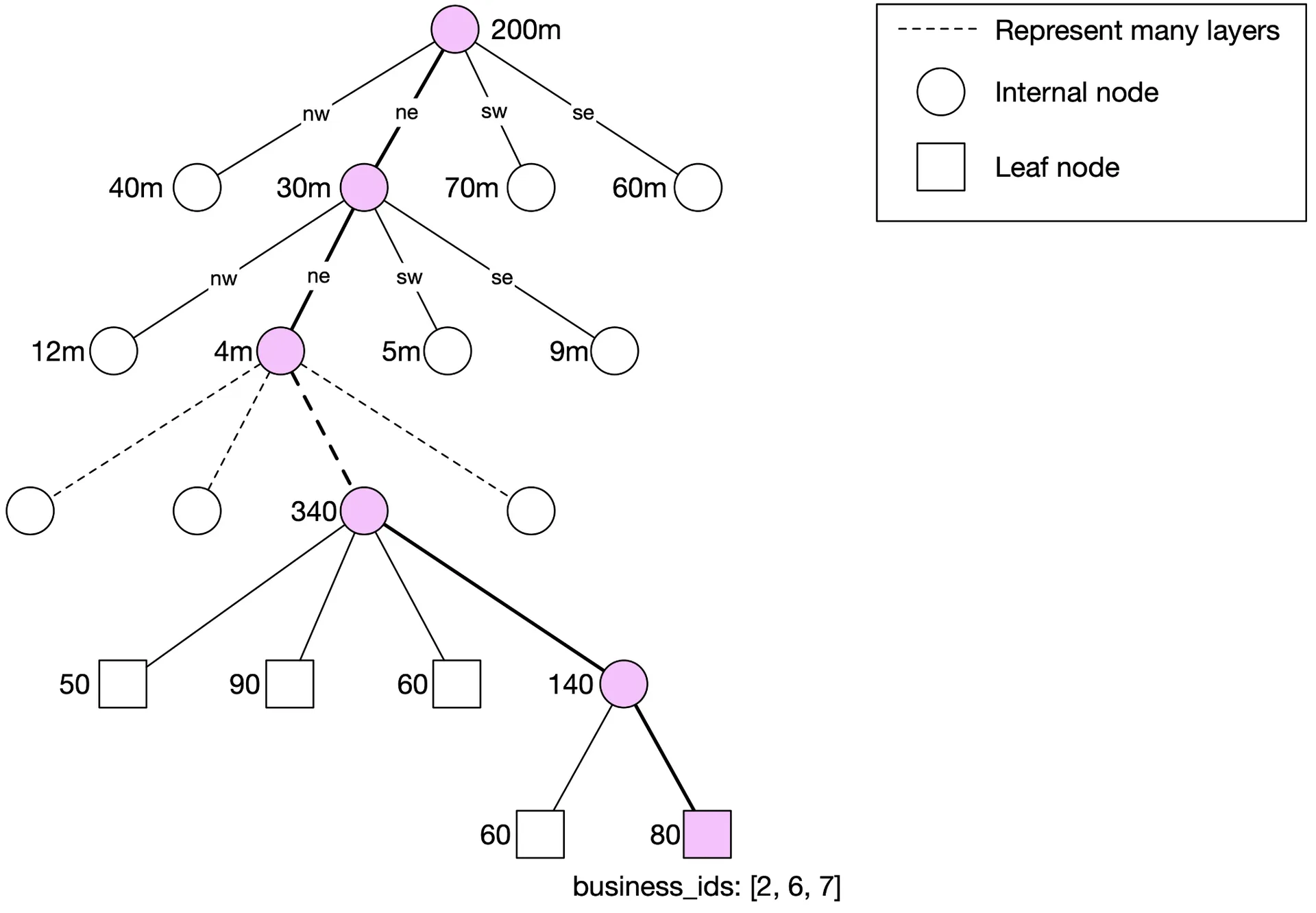 — Update quadtree (O(log n) but needs locking)
— Update quadtree (O(log n) but needs locking)
Option 5: Google S2
Maps sphere to 1D index via Hilbert curve. Two close points on the curve are close in 1D. Advantages: geofencing with arbitrary areas at varying levels; flexible Region Cover algorithm (min/max level + max cells).
 — Hilbert curve
— Hilbert curve
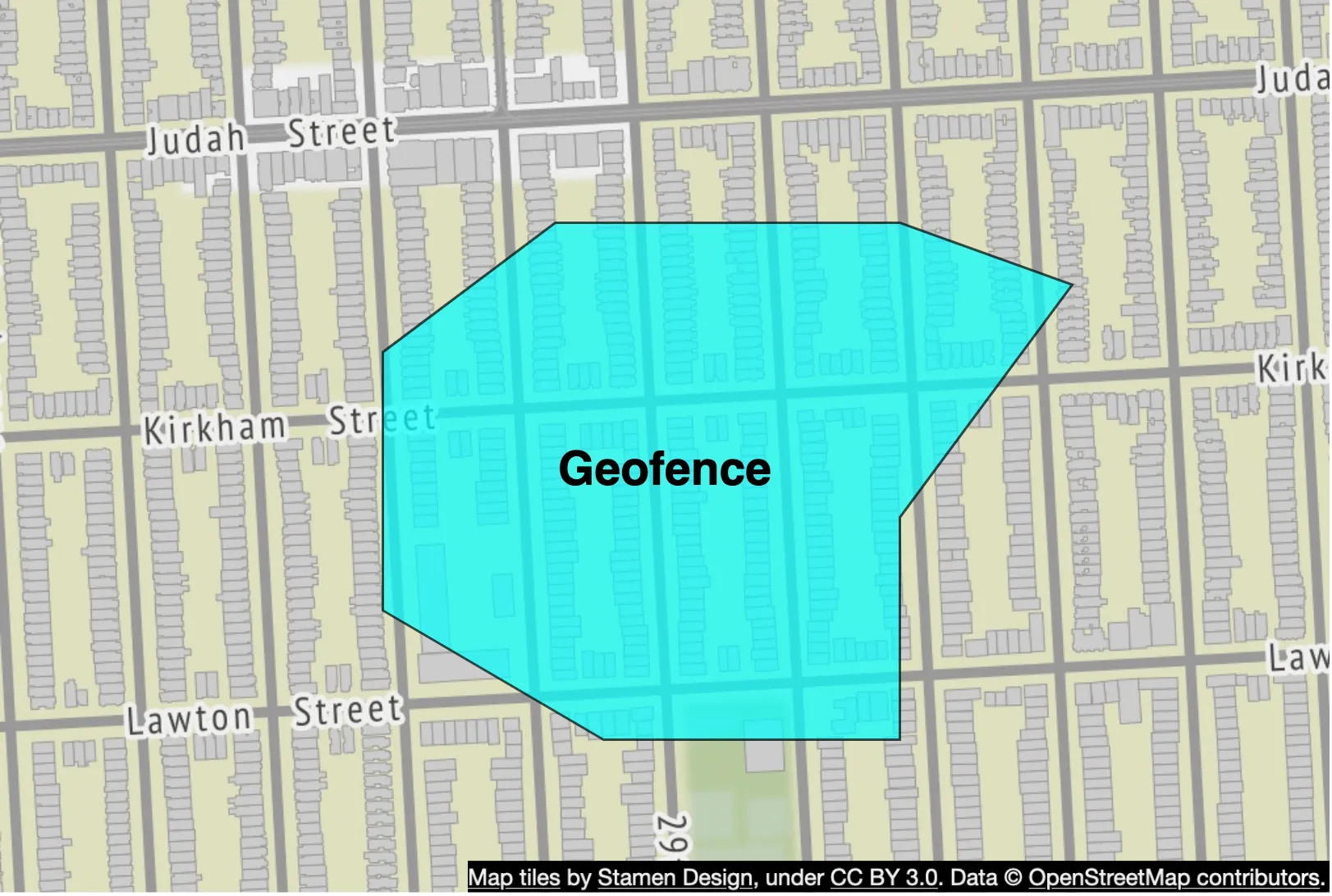 — Geofence
— Geofence
Industry adoption
| Geo Index | Companies |
|---|---|
| Geohash | Bing Maps, Redis, MongoDB, Lyft |
| Quadtree | Yext |
| Both | Elasticsearch |
| S2 | Google Maps, Tinder |
Geohash vs Quadtree comparison
Geohash: Easy to implement; fixed precision → fixed grid size; simple index updates (remove row); supports radius-based queries.
Quadtree: Harder (tree build needed); supports k-nearest queries; dynamic grid sizing by density; updating is O(log n) but complex with locking.
Recommendation for interview: Choose geohash or quadtree (S2 too complex to explain).
Step 3 - Design Deep Dive
Scale the database
Business table: Shard by business_id — even load distribution, easy to maintain.
Geospatial index table (geohash-based):
Two schema options:
Option 1: Single row per geohash with JSON array of business IDs — complex updates (scan array, lock row, handle duplicates).
Option 2: Compound key (geohash, business_id) with one row per business — simple add/remove, no locking needed. Recommended.


Scaling: Full geospatial index fits in working set of a modern DB (~1.71GB). No need to shard — use read replicas instead. Sharding adds application-layer complexity unnecessarily.
Caching
Heavily read-heavy, small dataset → DB queries already fast. Caching requires careful benchmarking. If beneficial:
Cache key: geohash (not raw lat/lng, which varies slightly with each reading). Small location changes map to same geohash.
Cache data types:
| Key | Value |
|---|---|
| geohash | List of business IDs |
| business_id | Business object |
Memory for Redis geohash cache (3 precisions):
- 8 bytes × 200M × 3 = ~5 GB.
- One modern Redis server sufficient; deploy global Redis cluster for HA and low cross-continent latency.
- Radii mapping: 500m→geohash_6, 1km/2km→geohash_5, 5km→geohash_4.
Business info cache: Key=business_id, value=business object. Updated nightly via batch job.
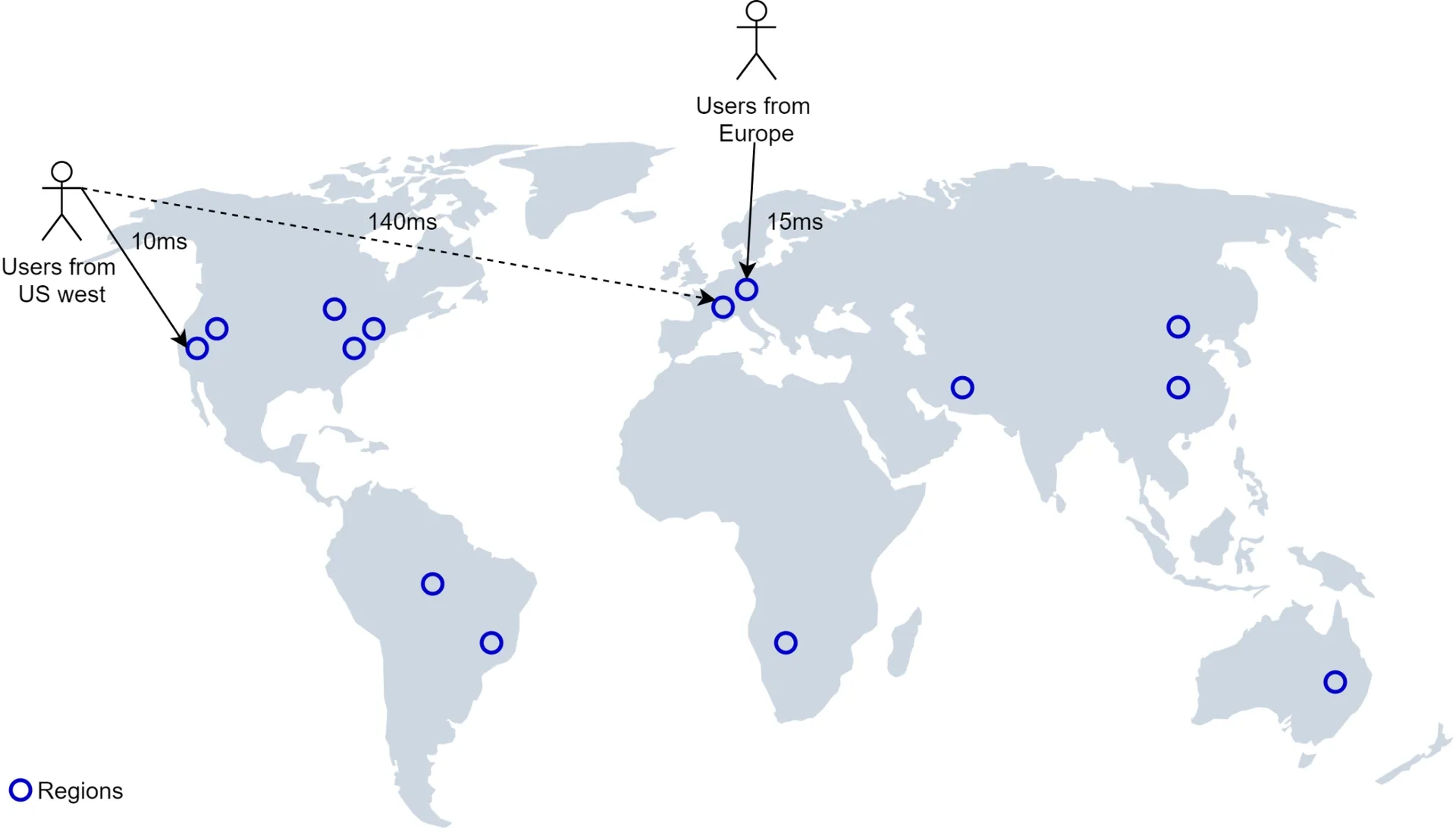
Region and availability zones
Deploy LBS to multiple regions:
- Users physically closer to servers.
- Spread traffic across dense regions (Japan, Korea → separate regions or multi-AZ).
- Comply with local privacy laws (country-specific deployments via DNS routing).
Filter results by time or business type
Return business IDs first, hydrate business objects, then filter on opening time/type. Result set is small enough (per-grid) for this approach.
Final design diagram
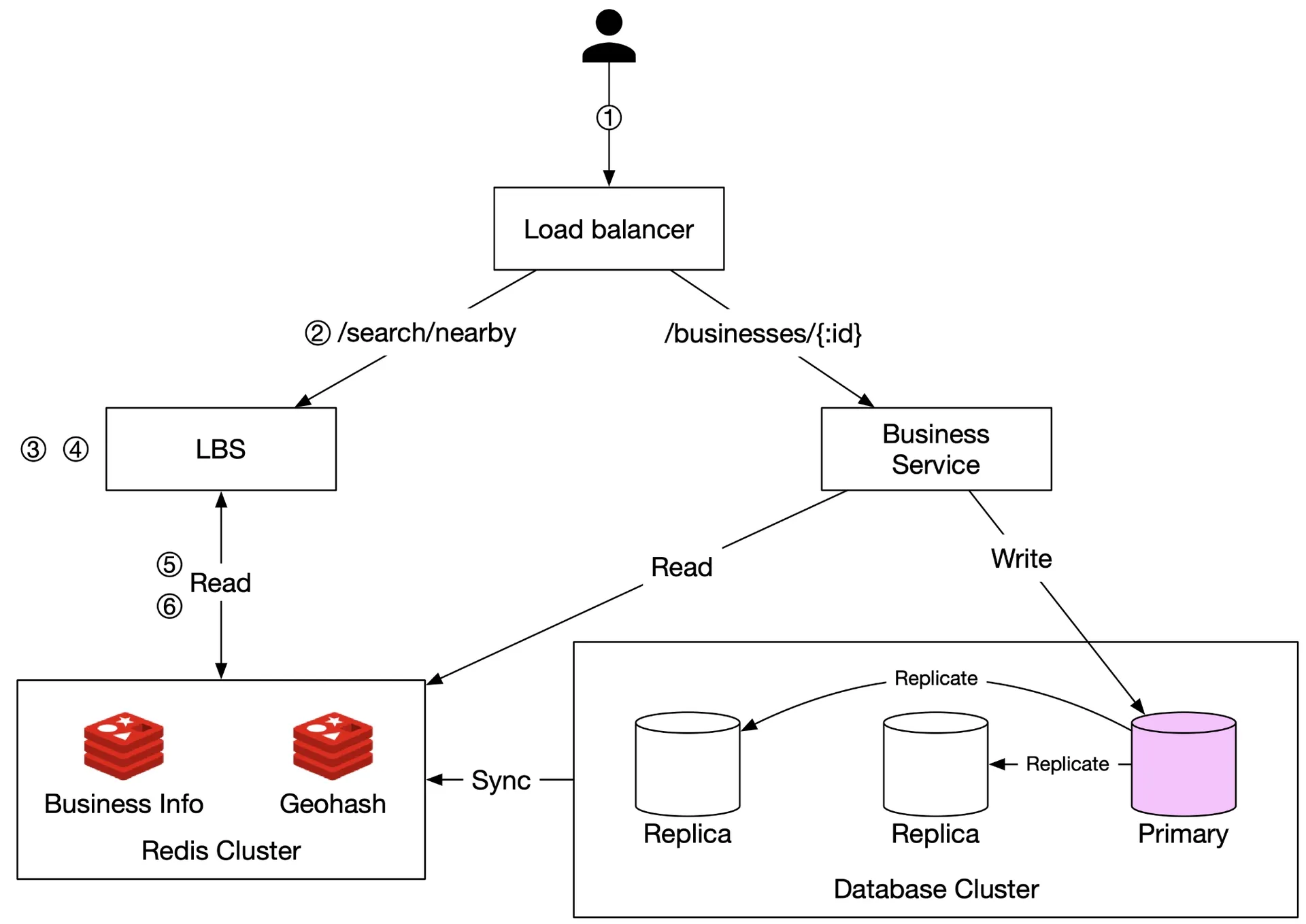
Figure 21 Design diagram
Flow for nearby search (500m radius example):
- Client sends (lat=37.776720, lng=-122.416730, radius=500m) to load balancer.
- LBS receives request.
- LBS maps 500m → geohash length 6 (per Table 5).
- LBS computes neighboring geohashes → list of 9 geohashes.
- LBS fetches business IDs from "Geohash" Redis (parallel calls per geohash).
- LBS fetches hydrated business info from "Business info" Redis, computes distances, ranks, returns to client.
Business CRUD flow: Business service handles all. Checks "Business info" cache first; falls back to DB. Cache updated nightly.
Step 4 - Wrap Up
Geospatial indexing options covered: 2D search, even grid, geohash, quadtree, Google S2. Geohash chosen for simplicity. Caching with Redis reduces latency. Database scaled via replication and sharding. Multi-region deployment for availability, latency, and privacy compliance.