Nearby Friends
6 min readDesign a "Nearby Friends" feature: opt-in mobile users see geographically nearby friends. Unlike Proximity Service (static business locations), friend locations change frequently — dynamic data.
Figure 1 Facebook's nearby friends
Step 1 - Understand the Problem and Establish Design Scope
Functional requirements
- Users see nearby friends with distance and last-updated timestamp.
- "Nearby" = within 5 miles (configurable). Straight-line distance.
- Friend lists update every few seconds.
- Inactive friends (no update >10 min) disappear from list.
- Store location history (for ML purposes).
- Privacy laws (GDPR/CCPA) out of scope for now.
Non-functional requirements
- Low latency for location updates.
- Reliable overall but occasional data point loss acceptable.
- Eventual consistency: few seconds delay between replicas is fine.
Back-of-the-envelope estimation
- 1B total users; 10% use nearby friends → 100M DAU.
- Concurrent users: 10% of DAU → 10M.
- Users report locations every 30 seconds (walking speed ~3-4 mph, 30s movement negligible).
- Average user has 400 friends (all using the feature).
- Display 20 nearby friends per page.
- Location update QPS = 10M / 30 = ~334,000.
- If ~10% of friends are online and nearby: each update forwarded to ~40 friends.
- Total forwarded updates: 334K × 40 = ~13M/sec.
Step 2 - Propose High-Level Design and Get Buy-In
High-level design
P2P approach (persistent connections to every friend) is impractical for mobile (flaky connections, power constraints). Shared backend approach:
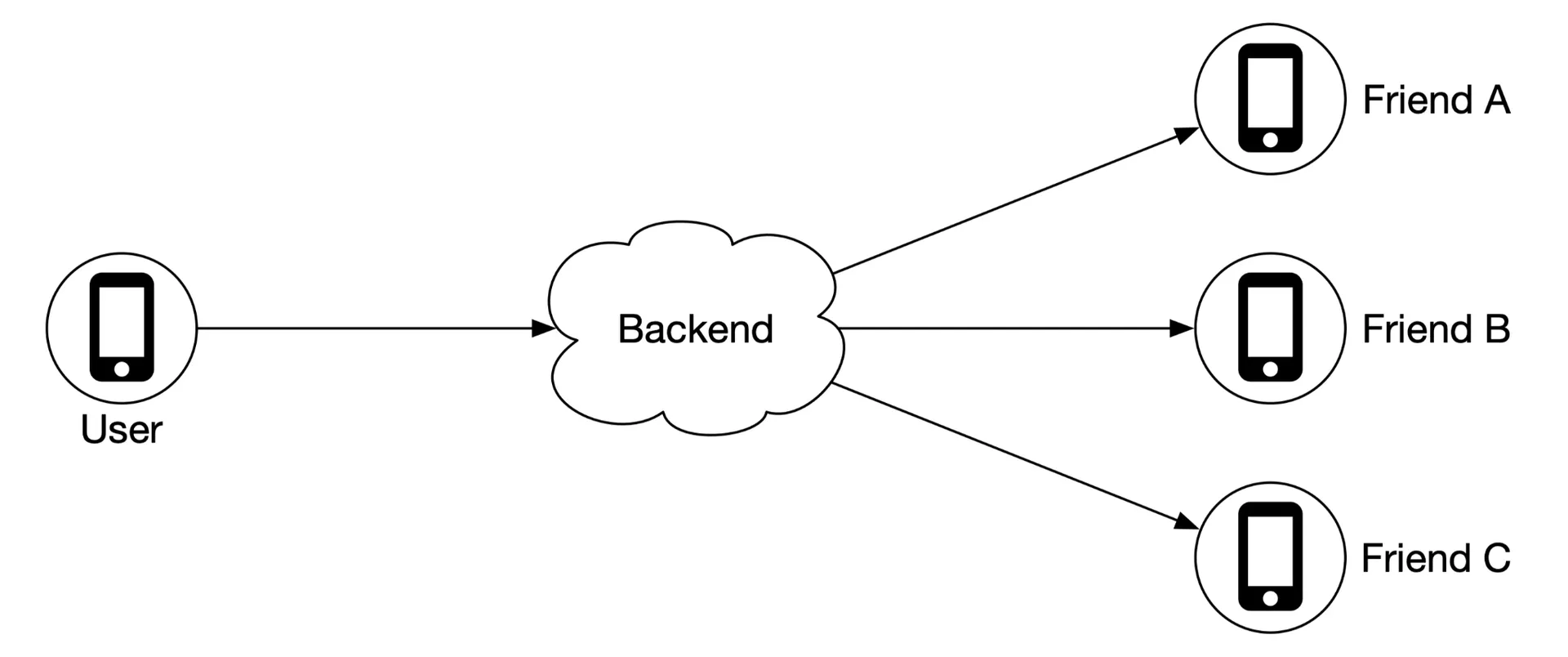
Backend responsibilities:
- Receive location updates from all active users.
- Find active friends who should receive each update.
- Forward only if distance ≤ threshold.
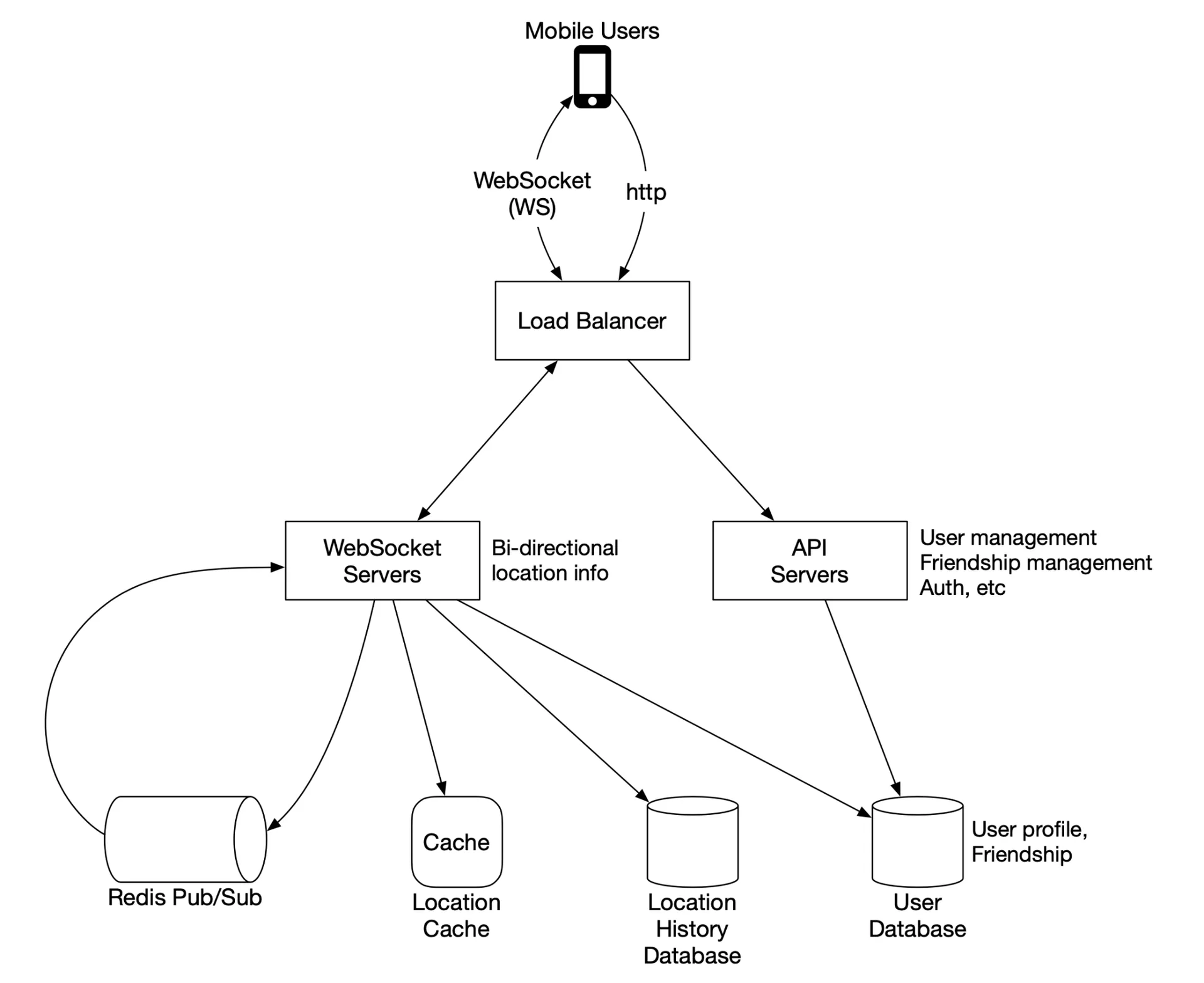
Figure 4 High-level design
Components:
- Load balancer: Fronts REST API + WebSocket servers. Distributes traffic.
- RESTful API servers: Stateless HTTP. Handles friends management, user profiles, etc.
- WebSocket servers: Stateful. Each client maintains one persistent connection. Handles real-time location updates and client initialization (seeds initial nearby friends list).
- Redis location cache: Latest location per active user. TTL on each entry; update refreshes TTL. Expired = user inactive.
- User database: User profiles + friendship data. Relational or NoSQL.
- Location history database: Historical locations. Cassandra (write-heavy, horizontally scalable) or sharded relational DB by user_id.
- Redis pub/sub server: Lightweight message bus. Each user has a channel; online friends subscribe. Location updates published to user's channel → broadcast to all subscribers → each subscriber's WebSocket handler recomputes distance → forwards if within radius.
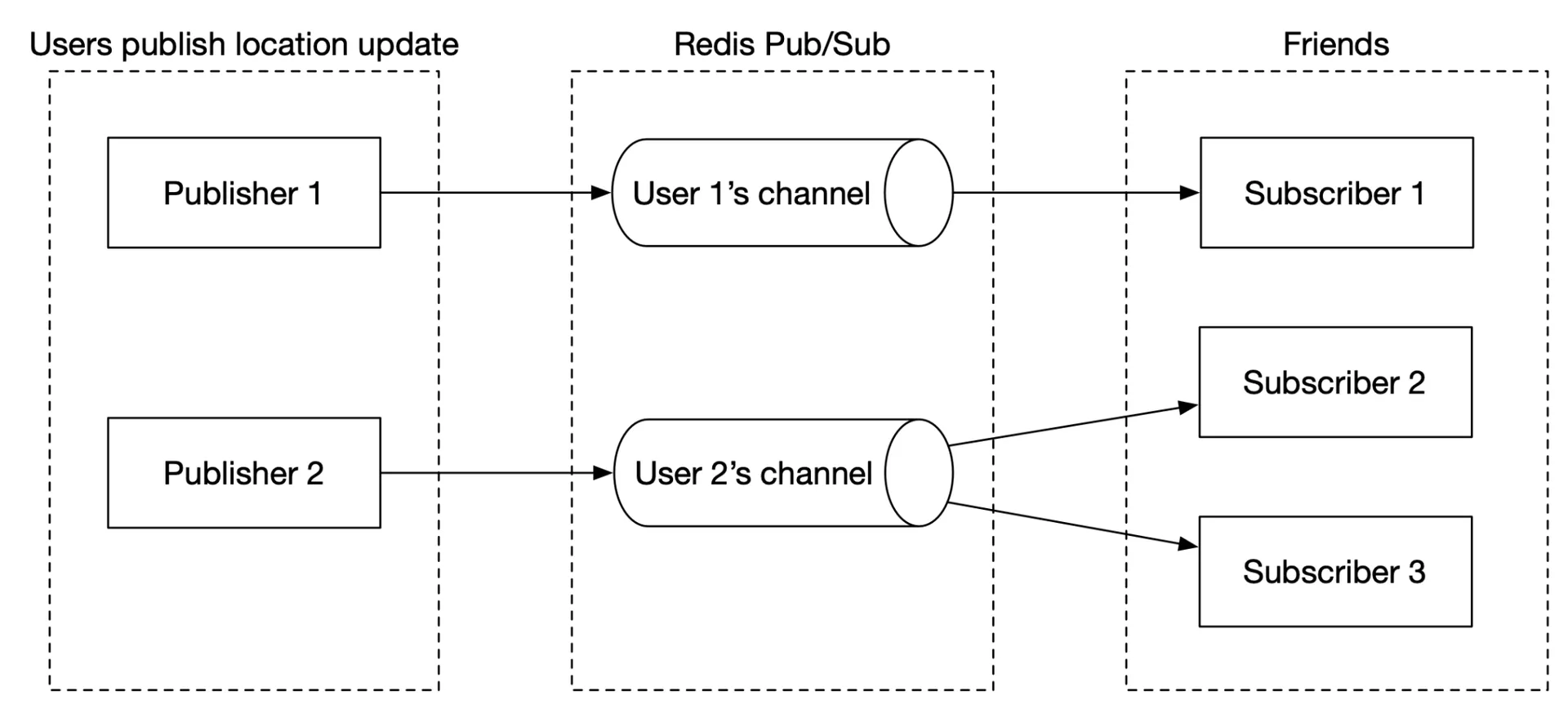
Figure 6 Redis Pub/Sub
Periodic location update flow
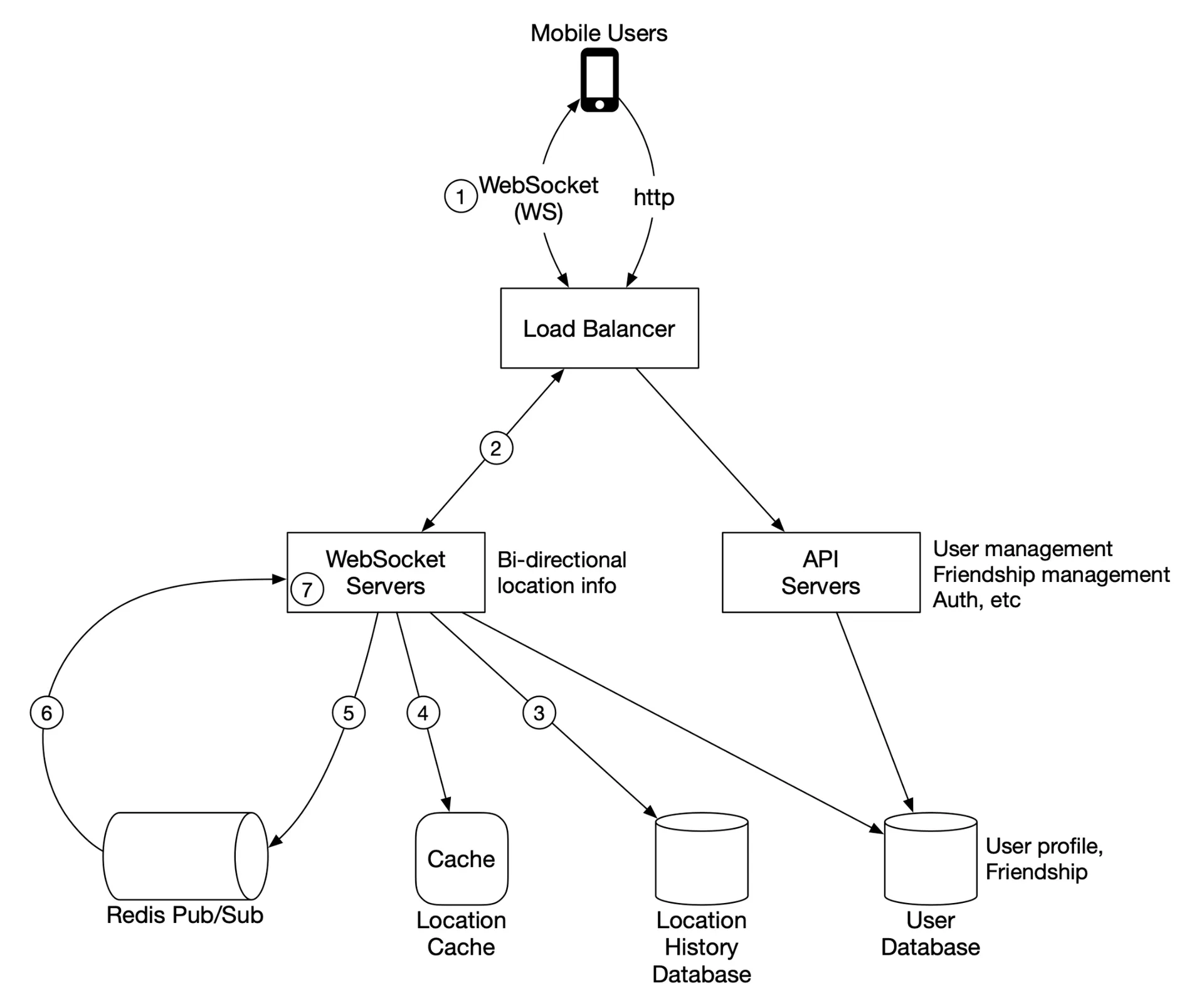
Figure 7 Periodic location update
- Mobile client sends location update via persistent WebSocket connection.
- Load balancer forwards to the WebSocket server for that client.
- WebSocket server saves to location history database.
- WebSocket server updates location cache (refreshes TTL) and stores in connection handler variable.
- WebSocket server publishes to user's Redis pub/sub channel. (Steps 3–5 in parallel.)
- Redis pub/sub broadcasts to all subscribers (online friends' WebSocket handlers).
- Each subscriber's WebSocket handler computes distance between updating user and subscriber.
- If distance ≤ search radius → forward to subscriber's client. Otherwise drop.
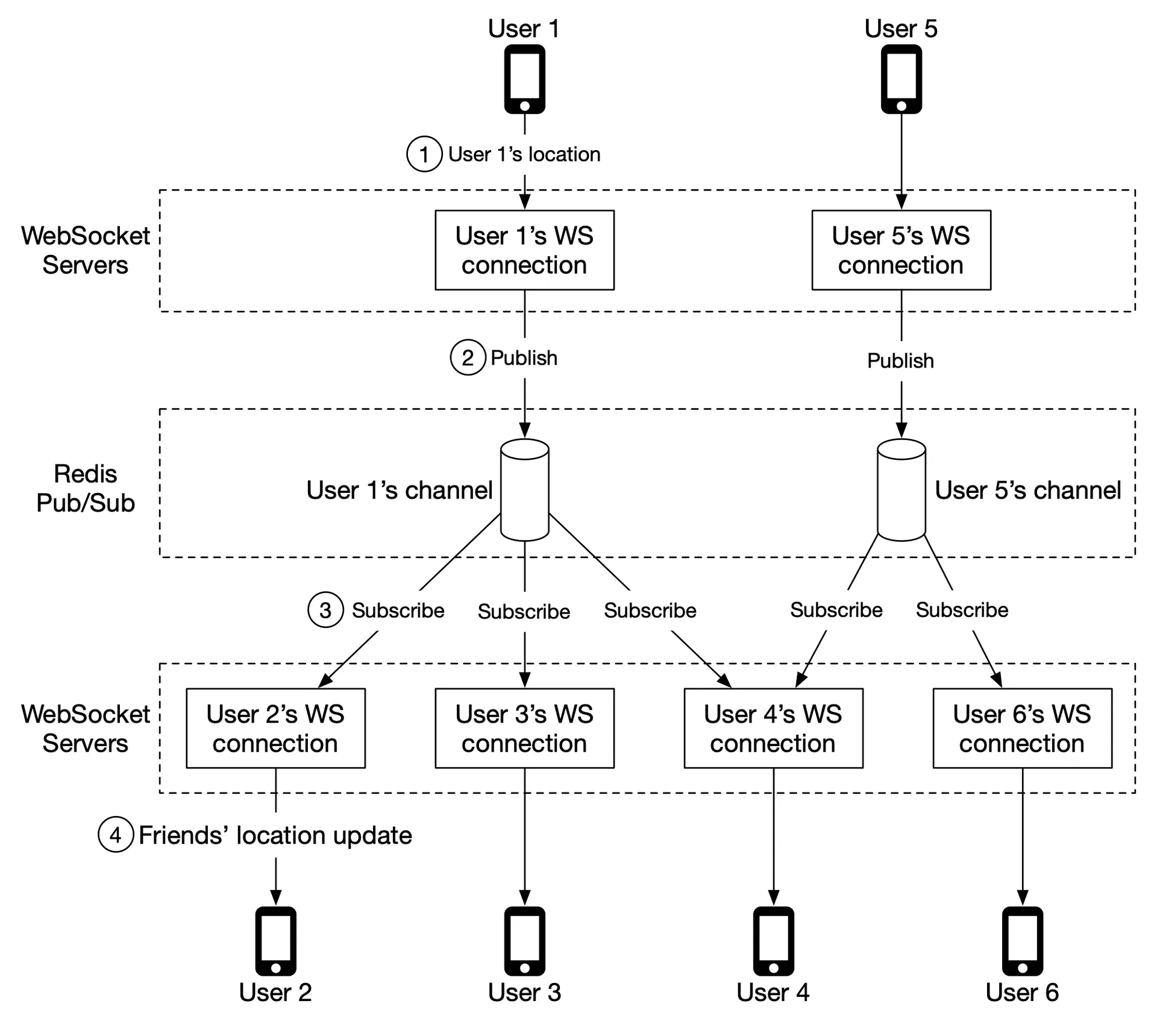
Figure 8 Example: User 1's friends = {2,3,4}. Update published to User 1's channel → broadcast to handlers for users 2,3,4 → distance check → forward.
API design
WebSocket APIs:
- Periodic location update: client sends (lat, lng, timestamp). No response.
- Client receives location updates: friend's (lat, lng, timestamp).
- WebSocket initialization: client sends (lat, lng, timestamp); receives all nearby friends' locations.
- Subscribe to new friend: server sends friend ID; receives friend's (lat, lng, timestamp).
- Unsubscribe friend: server sends friend ID. No response.
HTTP: Friends CRUD, user profiles — standard.
Data model
Redis location cache:
| Key | Value |
|---|---|
| user_id | {latitude, longitude, timestamp} |
Why Redis? Only need current location (one per user); TTL auto-purges inactive users; no durability needed (cache can be rebuilt from new updates). Super-fast reads/writes.
Location history database (Cassandra):
| user_id | latitude | longitude | timestamp |
|---|
Handles heavy-write workload; horizontally scalable. Alternative: relational DB sharded by user_id.
Step 3 - Design Deep Dive
Scaling each component
API servers: Stateless → standard auto-scaling by CPU/load/I/O.
WebSocket servers: Stateful but auto-scalable. Before removing a node, mark as "draining" — no new connections; wait for existing connections to close.
Client initialization (on WebSocket connect):
- Update user's location in cache.
- Save location in connection handler variable.
- Load all friends from user DB.
- Batch-fetch friends' locations from location cache (TTL = inactivity timeout, so inactive friends won't be in cache).
- For each located friend, compute distance; if within radius, return profile + location + timestamp.
- Subscribe to each friend's Redis pub/sub channel (all friends, active or inactive — inactive channels consume tiny memory, zero CPU).
- Send user's location to their own pub/sub channel.
User database: Shard by user_id for horizontal scaling. At scale, likely managed by a dedicated team via internal API.
Location cache (Redis):
- 10M active users peak × ~100 bytes/location → fits single Redis server with GBs of memory.
- But 334K writes/sec likely too high for one server → shard by user_id across multiple Redis instances.
- Each shard replicated to standby for HA (promote on primary failure).
Redis pub/sub scaling
Each of 100M users gets a channel. Subscribers ≈ active friends using feature (avg 100).
Memory: 100M channels × 100 subscribers × 20 bytes ≈ 200 GB → ~2 Redis servers (modern 100GB servers).
CPU: 13M subscriber pushes/sec. Conservative estimate: ~100K pushes/sec/server → ~130 Redis pub/sub servers needed. CPU is the bottleneck, not memory.
Distributed Redis pub/sub cluster
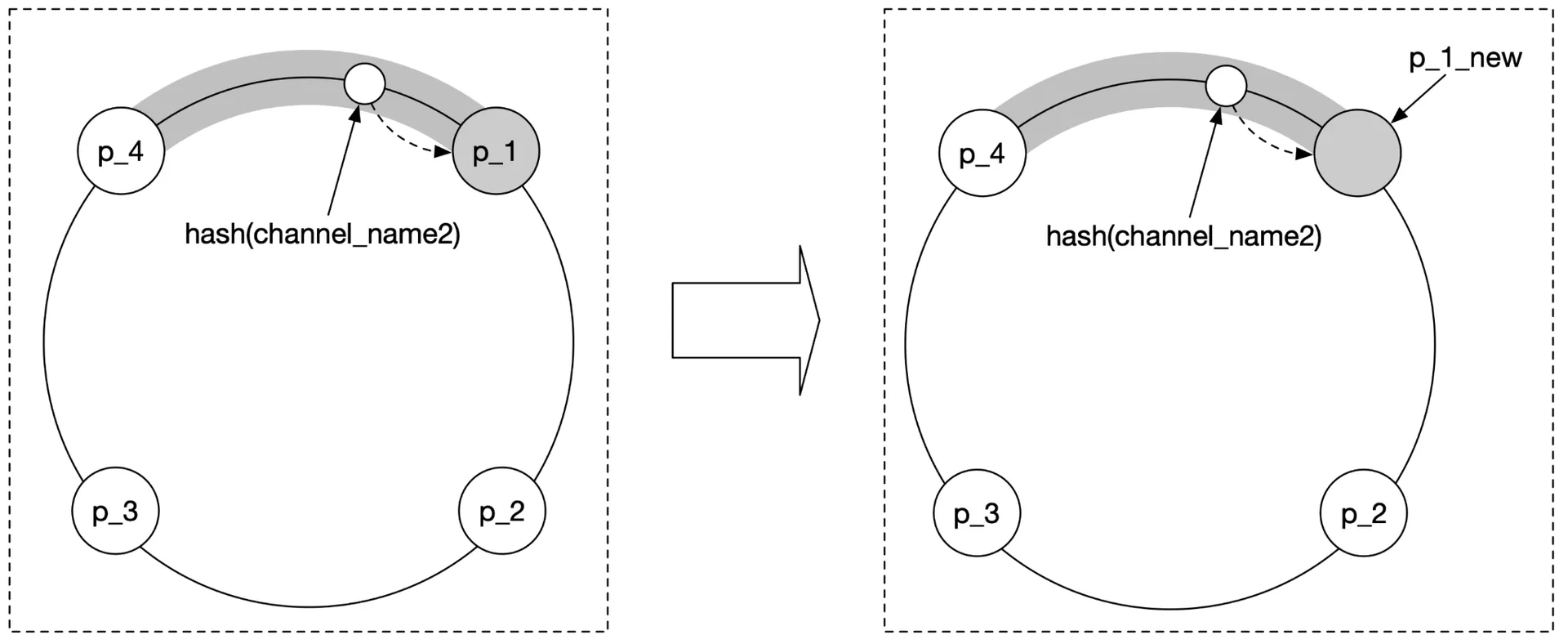
Shard channels across servers via consistent hashing on publisher's user_id. Use service discovery (etcd/Zookeeper) storing a hash ring:
Key: /config/pub_sub_ring
Value: ["p_1", "p_2", "p_3", "p_4"]
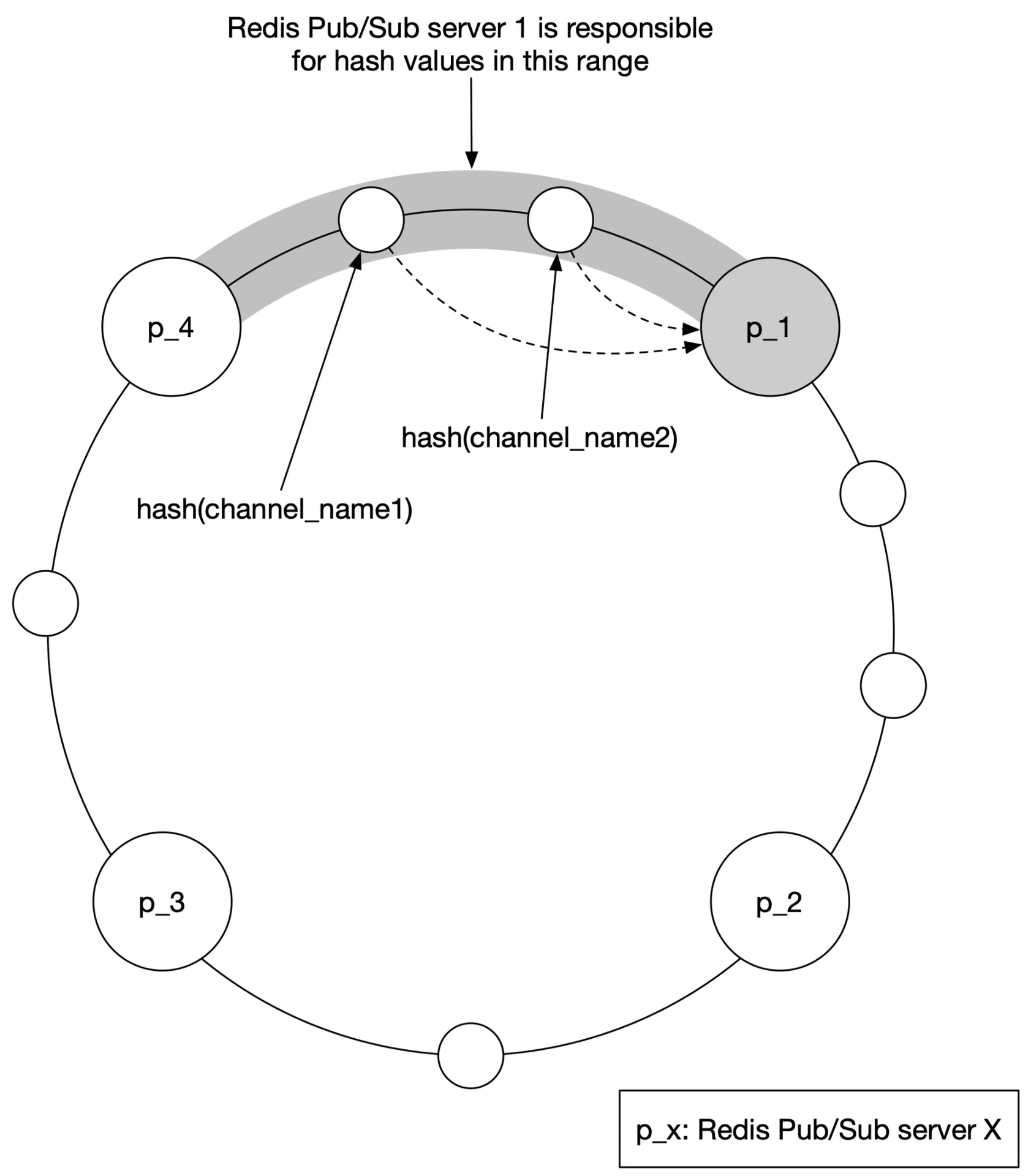
Figure 9 Consistent hashing
Publishing flow:
- WebSocket server consults hash ring → determines target Redis pub/sub server.
- Publishes to that server.
Subscribing: Same mechanism.
Scaling considerations:
- Messages are stateless (not persisted; dropped if no subscribers). But subscriber lists ARE stateful.
- Moving channels (resizing cluster) → mass resubscription events → potential missed updates. Resize during low-traffic hours. Over-provision for headroom.
- Replacing a single failed server causes fewer channel moves than resizing.
Node replacement:
- On-call updates hash ring to replace dead node with standby.
- WebSocket servers notified → each handler checks subscribed channels → re-subscribes if channel moved.
Adding/removing friends
Register callbacks in the mobile app. On friend add → WebSocket subscribes to new friend's channel + returns friend's latest location. On friend remove → unsubscribe. Same for opt-in/opt-out changes.
Users with many friends
Hard cap on friends (e.g., Facebook's 5,000). Subscribers scattered across WebSocket cluster → no hotspots. "Whale" users spread across pub/sub servers.
Nearby random person (extra credit)
Add pub/sub channels by geohash. Users in same geohash subscribe to same channel. To handle border cases, subscribe to own geohash + 8 surrounding grids (9 total).
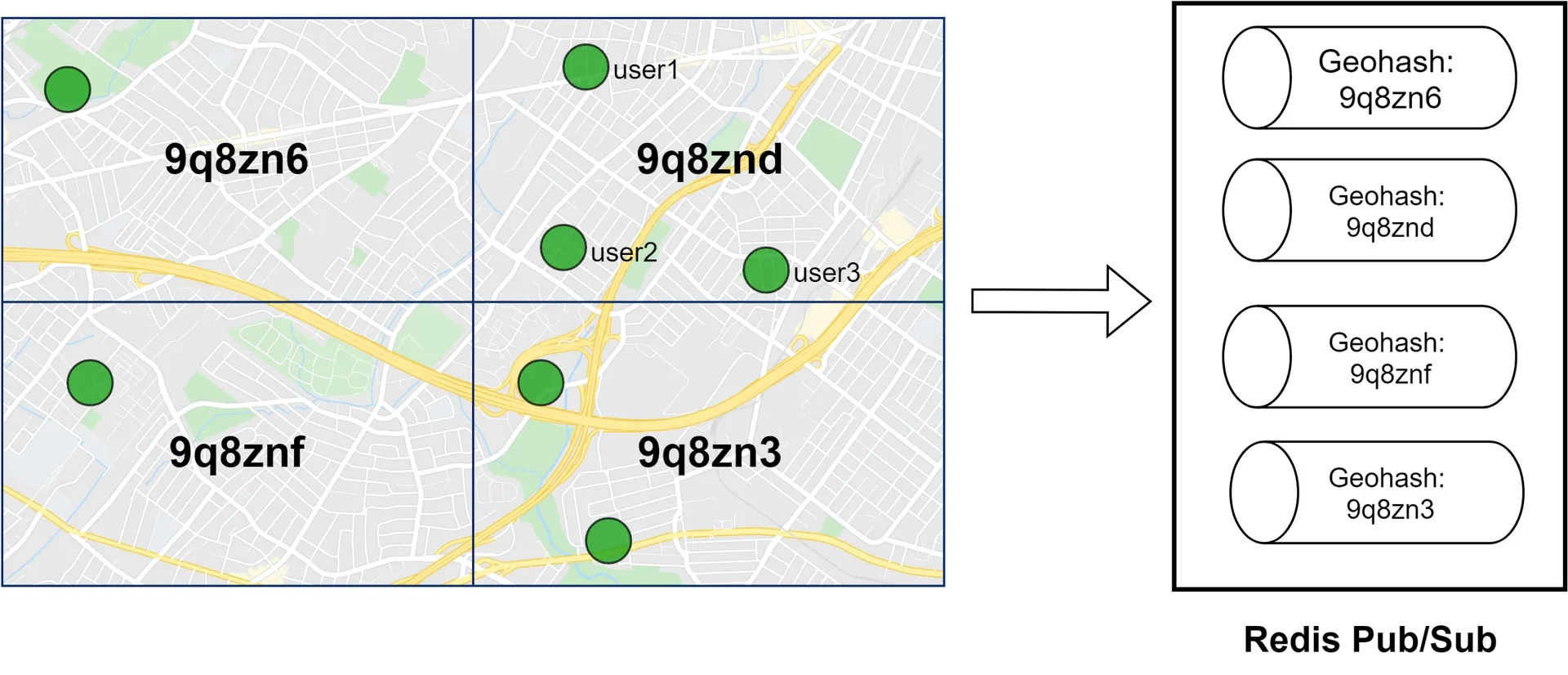
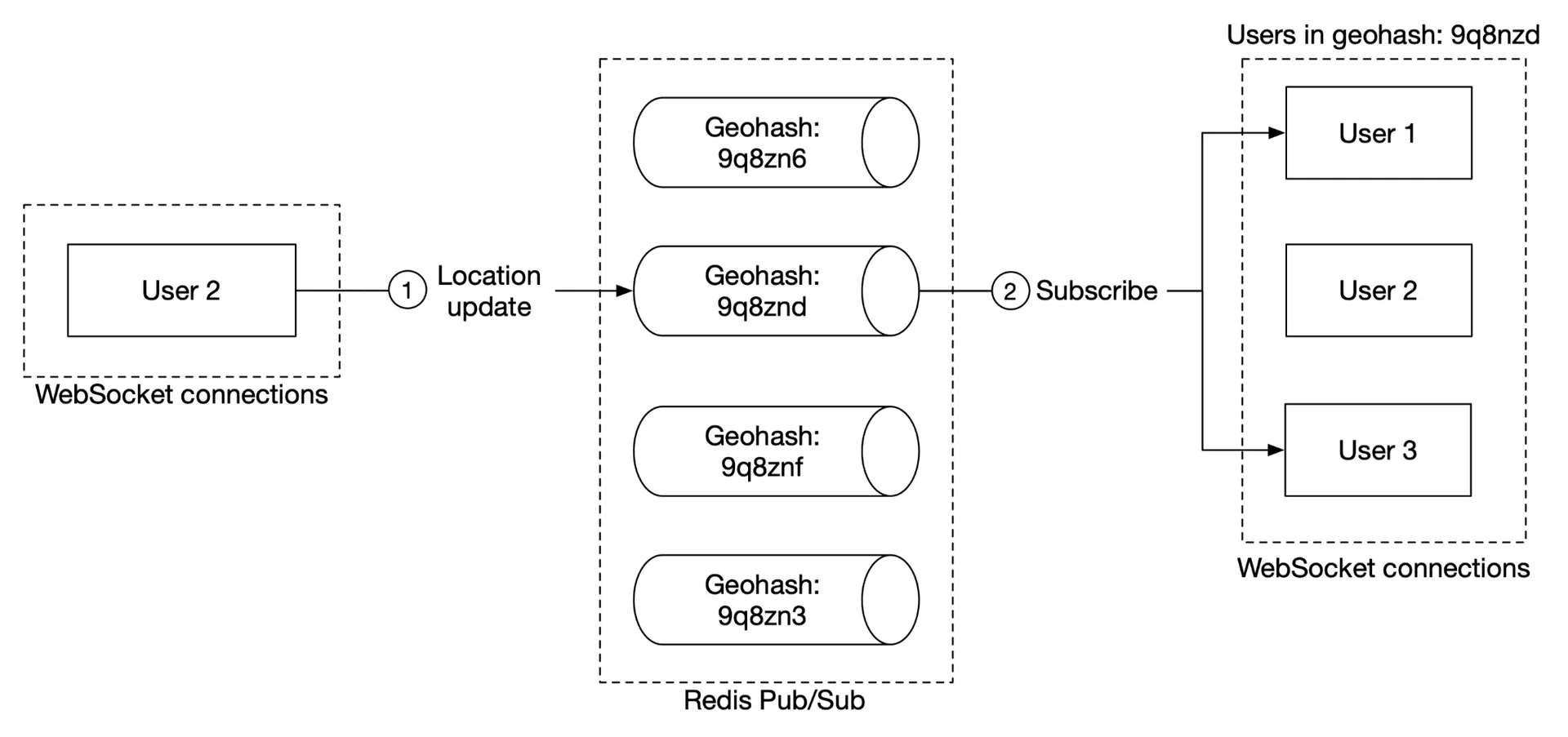
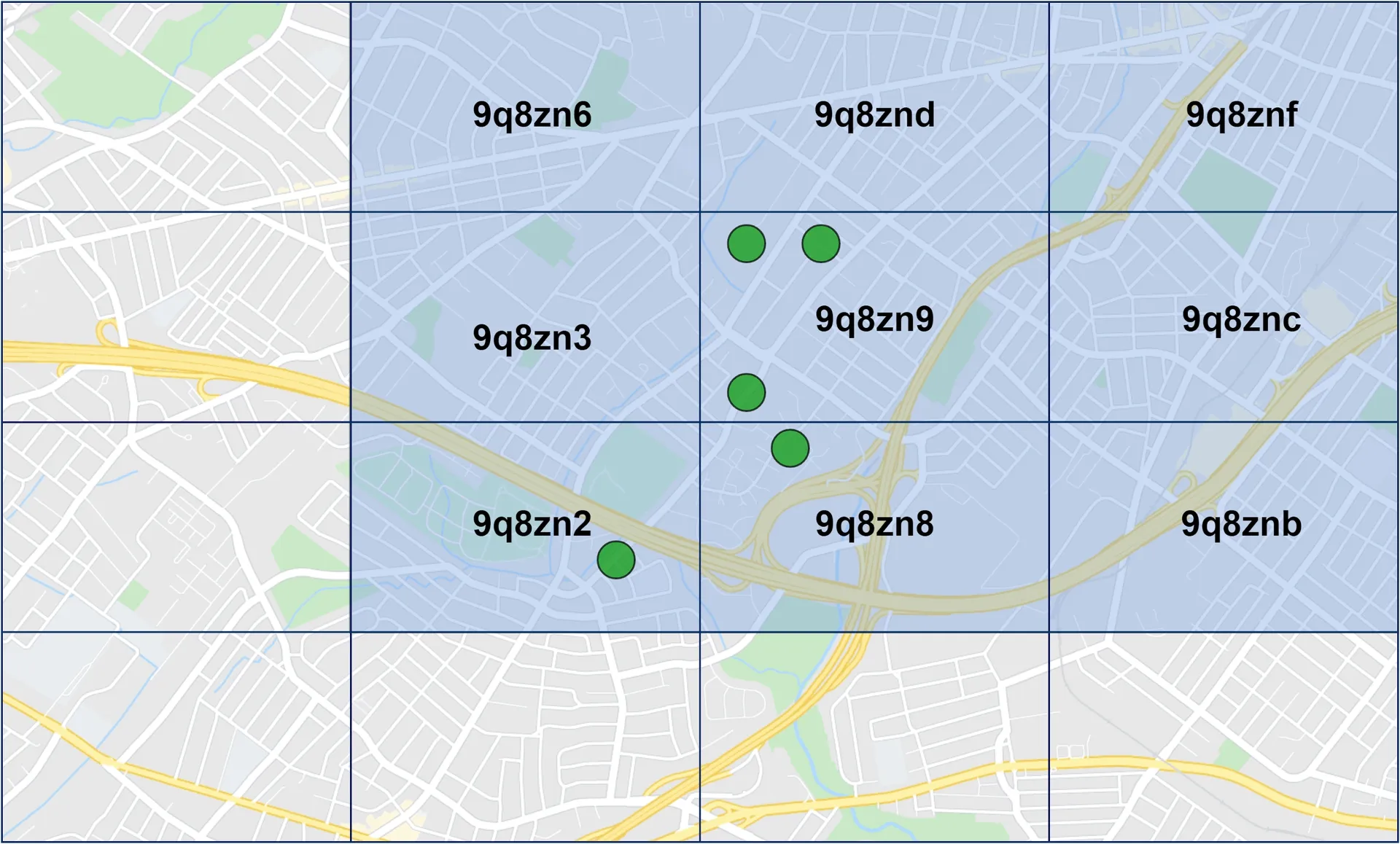
Alternative: Erlang
Erlang/Elixir on BEAM VM: lightweight processes (~300 bytes each, millions per server). Model each active user as an Erlang process with native pub/sub. Eliminates Redis pub/sub cluster entirely. Operational tools are excellent. Downside: niche skill, hard to hire.
Step 4 - Wrap Up
Core components: WebSocket (real-time comm), Redis (fast location read/write), Redis pub/sub (routing layer). Scaled via consistent hashing for pub/sub, sharding for location cache and user DB. Addressed friend add/remove, whale users, and nearby random person extension. Erlang as alternative routing layer.