Digital Wallet
9 min readDesign a digital wallet backend supporting cross-wallet balance transfers. Users store money in wallet and spend/transfer later.

Figures 1-2: Digital wallet, Cross-wallet balance transfer
Step 1 - Understand the Problem and Establish Design Scope
Requirements:
- Balance transfer between two digital wallets only
- 1,000,000 TPS (transactions per second)
- Transactional guarantees sufficient
- Reproducibility required: must be able to reconstruct historical balances by replaying data from the beginning (beyond reconciliation — shows discrepancies but not root cause)
- 99.99% availability
- No foreign exchange
Back-of-the-envelope estimation:
- Each transfer = 2 operations (debit + credit) → 2M actual TPS
- Assume 1,000 TPS per DB node → need 2,000 nodes
| Per-node TPS | Nodes needed |
|---|---|
| 100 | 20,000 |
| 1,000 | 2,000 |
| 10,000 | 200 |
Goal: maximize per-node TPS to reduce hardware cost.
Step 2 - Propose High-Level Design and Get Buy-In
API Design
POST /v1/wallet/balance_transfer
Params: from_account, to_account, amount (string), currency (ISO 4217), transaction_id (UUID for dedup).
In-memory sharding solution (rejected)
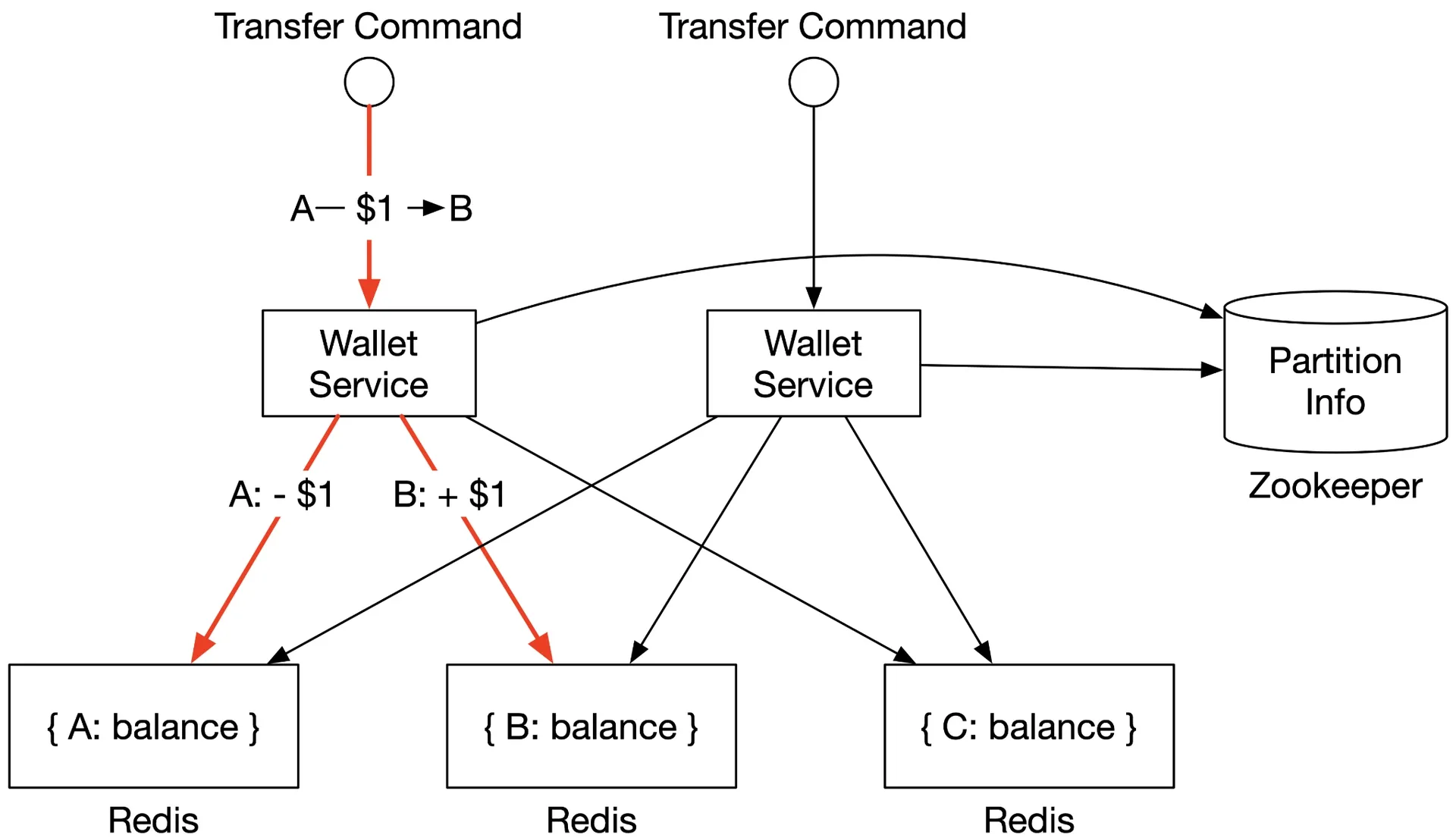
Figure 3: In-memory solution
Redis cluster, sharded by hash(accountID) % partitionNumber. Zookeeper for sharding config. Stateless wallet service handles transfers by updating two Redis nodes.
Problem: Two updates across nodes are not atomic. Wallet service crash between debit and credit → incomplete transfer. Need atomic transactions.
Distributed transactions
Database sharding
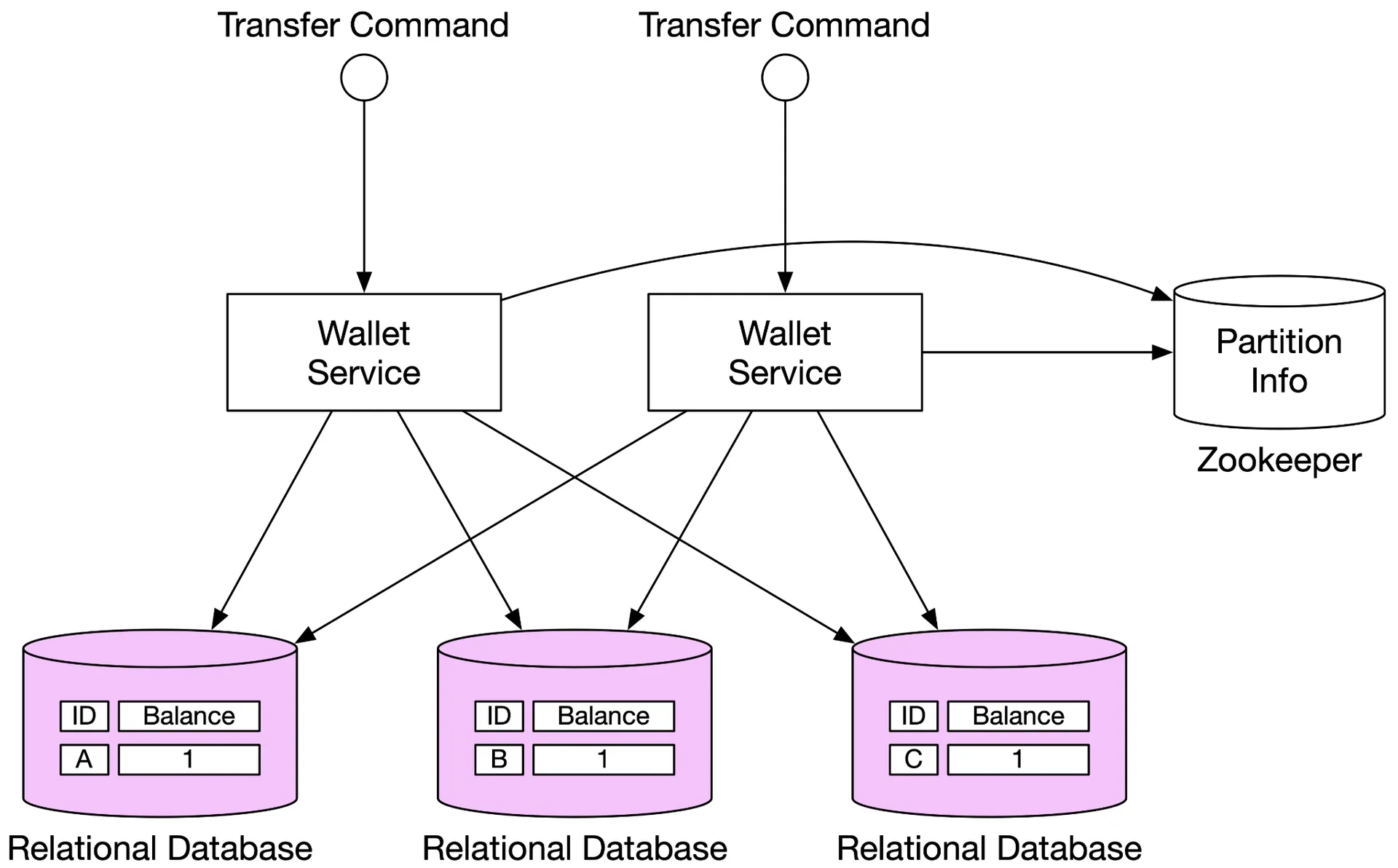
Figure 4: Relational database
Replace Redis nodes with transactional relational DB nodes. Still doesn't guarantee atomicity across two different databases.
Two-phase commit (2PC)
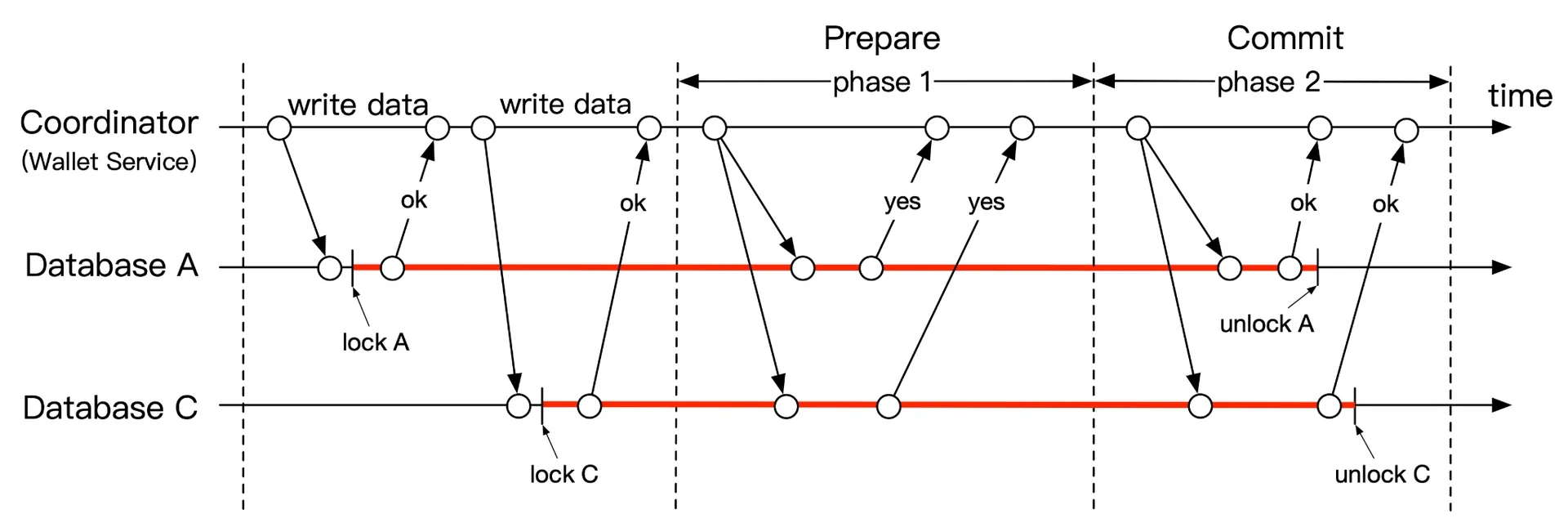
Figure 5: Two-phase commit
- Coordinator (wallet service) reads/writes on multiple DBs (all locked)
- Coordinator asks all DBs to prepare
- All "yes" → commit all. Any "no" → abort all.
Low-level solution: requires special DB transaction modification (X/Open XA standard). Problems: locks held long (low performance), coordinator is single point of failure.
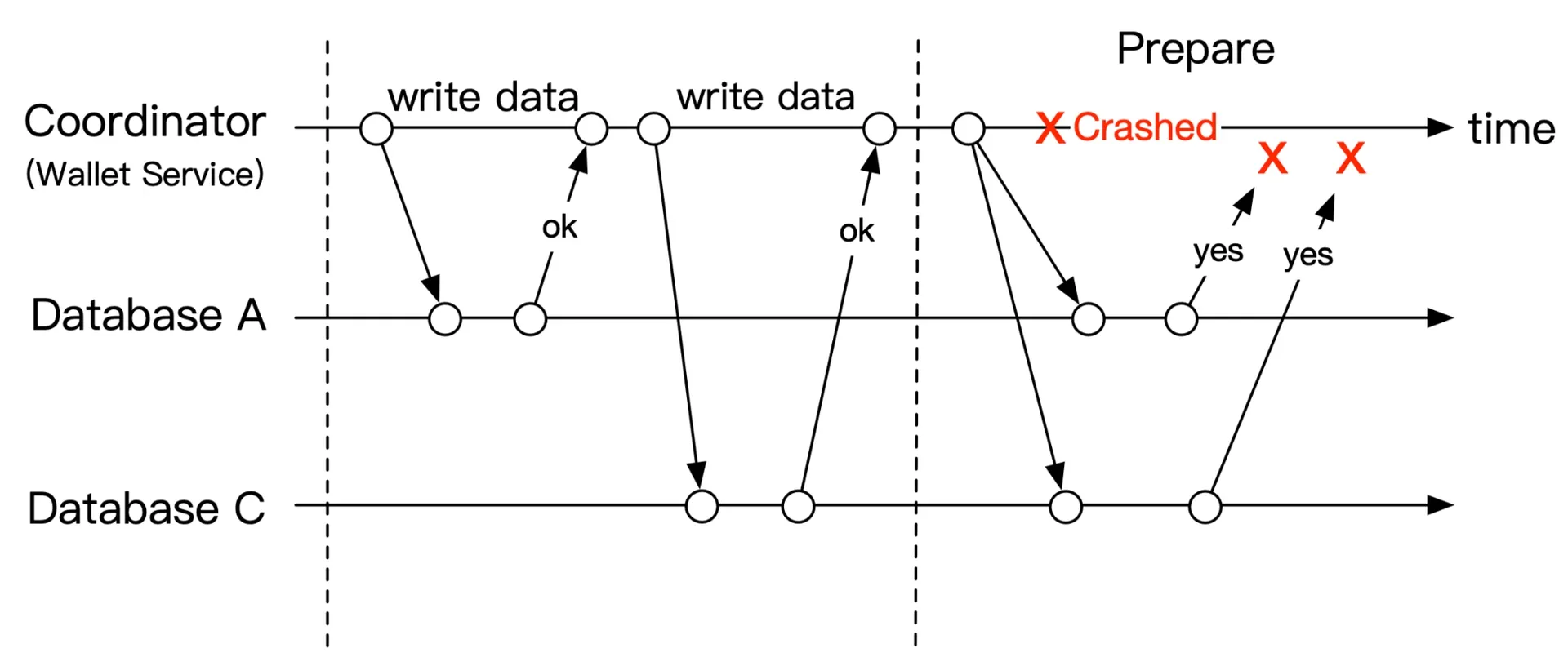
Figure 6: Coordinator crashes
Try-Confirm/Cancel (TC/C)
Compensating transaction approach. Two phases, each a separate independent transaction (unlike 2PC where both phases are in same transaction).
Example: Transfer $1 from A→C:
| Phase | Operation | Account A | Account C |
|---|---|---|---|
| 1 (Try) | Balance change: -$1 | NOP (do nothing) | |
| 2 | Confirm (success) | NOP | Balance change: +$1 |
| 2 | Cancel (failure) | Balance change: +$1 (reverse) | NOP |
Try phase:
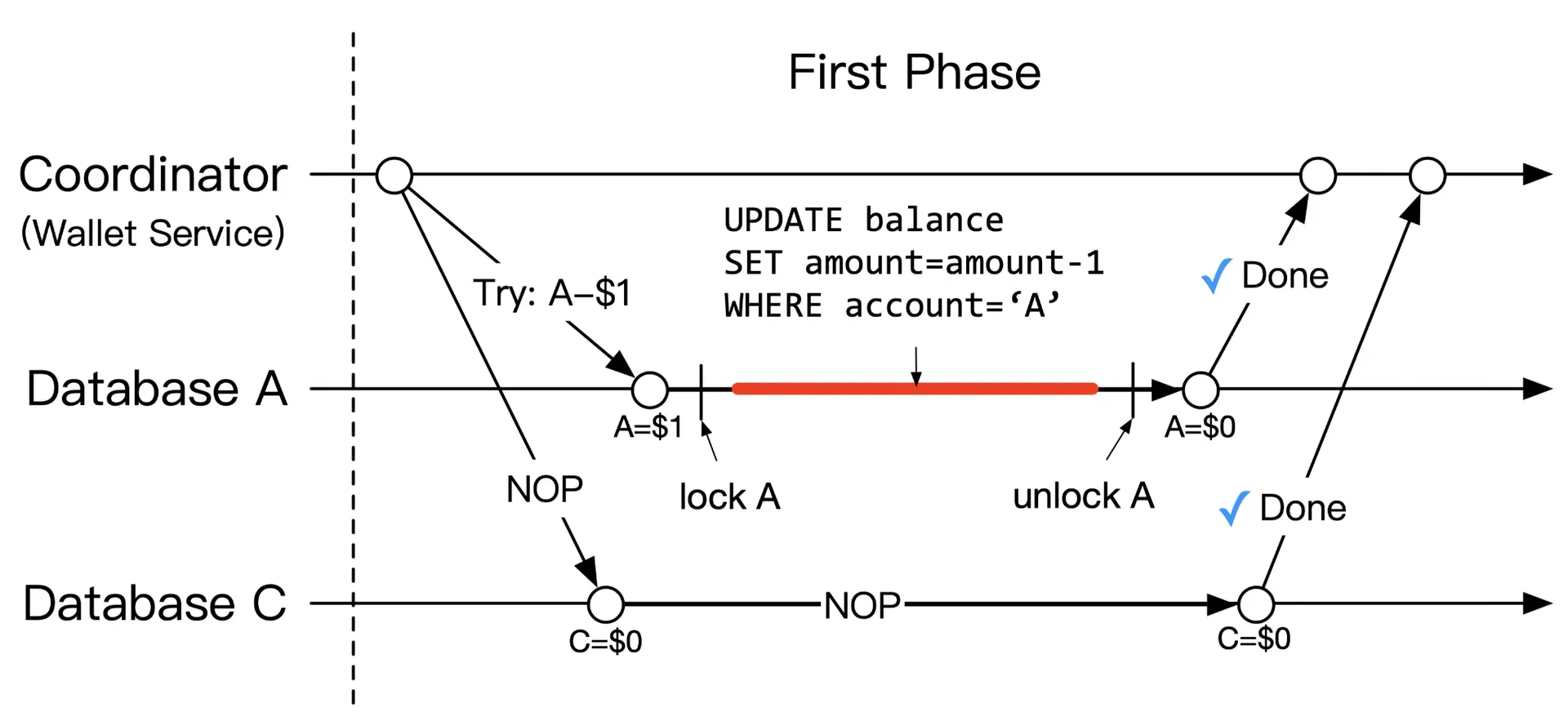
Figure 7: Try phase
Wallet service sends: (1) A: start local transaction, reduce balance -$1. (2) C: NOP (always succeeds).
Confirm phase:
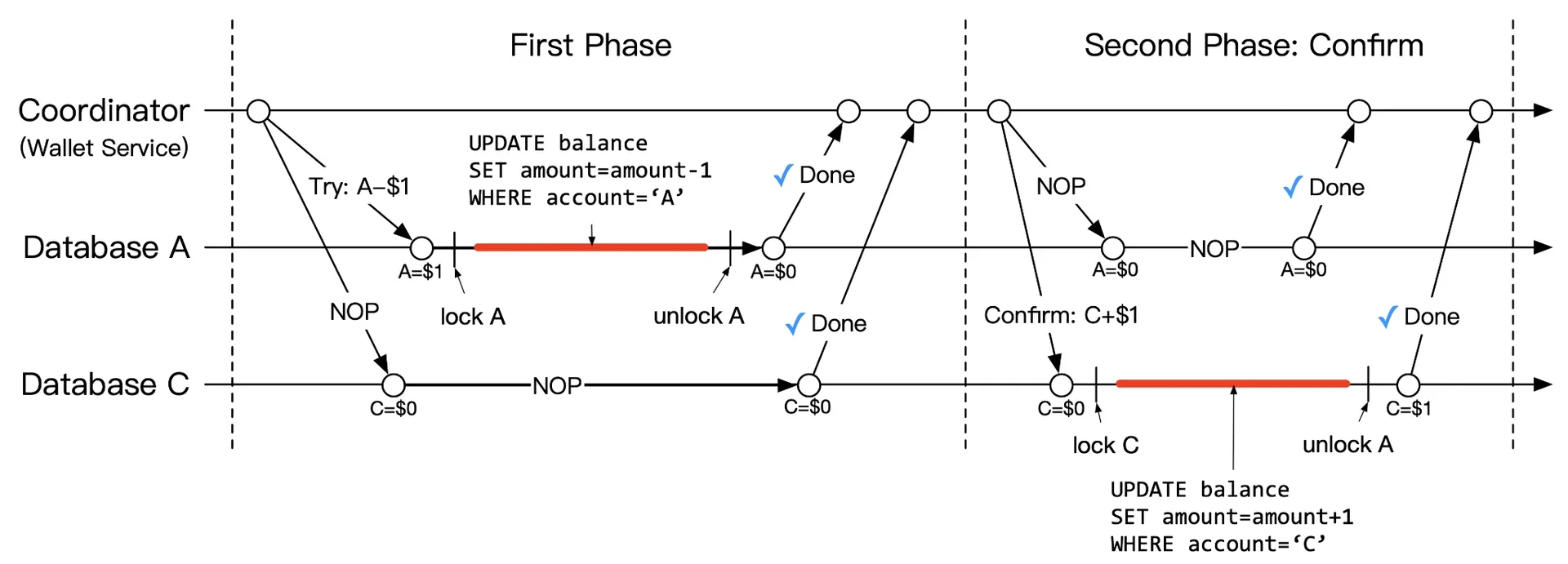
Figure 8: Confirm phase
A already updated. C: add $1.
Cancel phase:
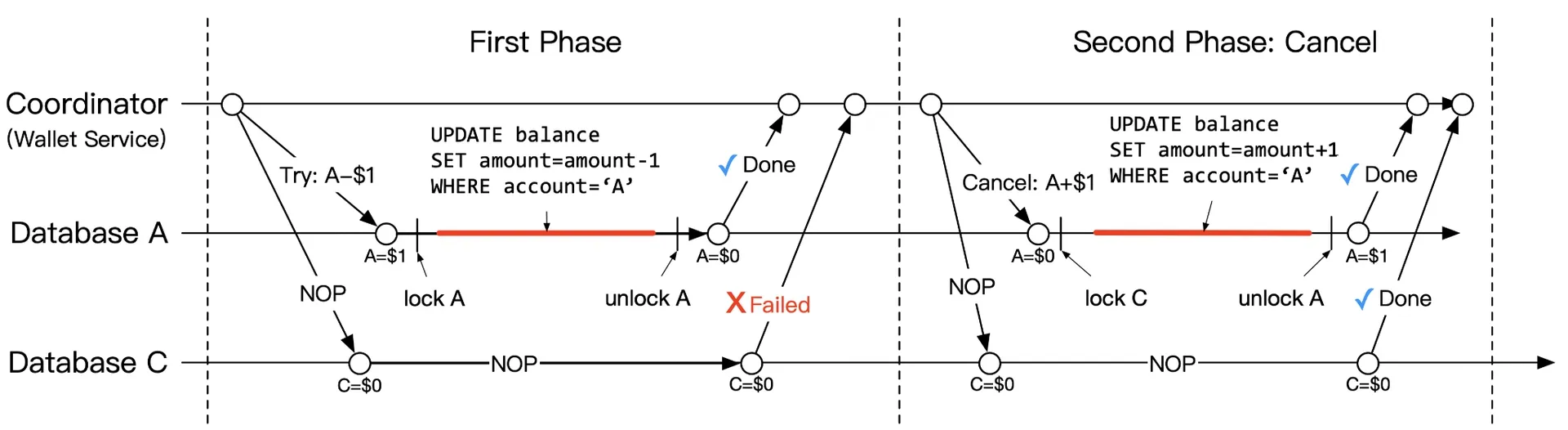
Figure 9: Cancel phase
A's Try already committed → start new transaction to add $1 back (reverse). C: NOP.
| First Phase | Second Phase: Success | Second Phase: Fail | |
|---|---|---|---|
| 2PC | Local transactions NOT done (locked) | Commit all | Cancel all |
| TC/C | All local transactions COMPLETED (committed/canceled) | Execute new transactions if needed | Reverse side effect (undo) |
TC/C = "distributed transaction by compensation." High-level (business logic implements undo). Database-agnostic (any DB with transactions works). Disadvantage: complexity in application layer.
Phase status table
If wallet service crashes mid-TC/C, recovery needs history. Store progress in transactional DB:
- Distributed transaction ID + content
- Try phase status per DB (not sent / sent / response received)
- Second phase name (Confirm or Cancel)
- Second phase status
- Out-of-order flag
Stored in the DB containing the debit account.
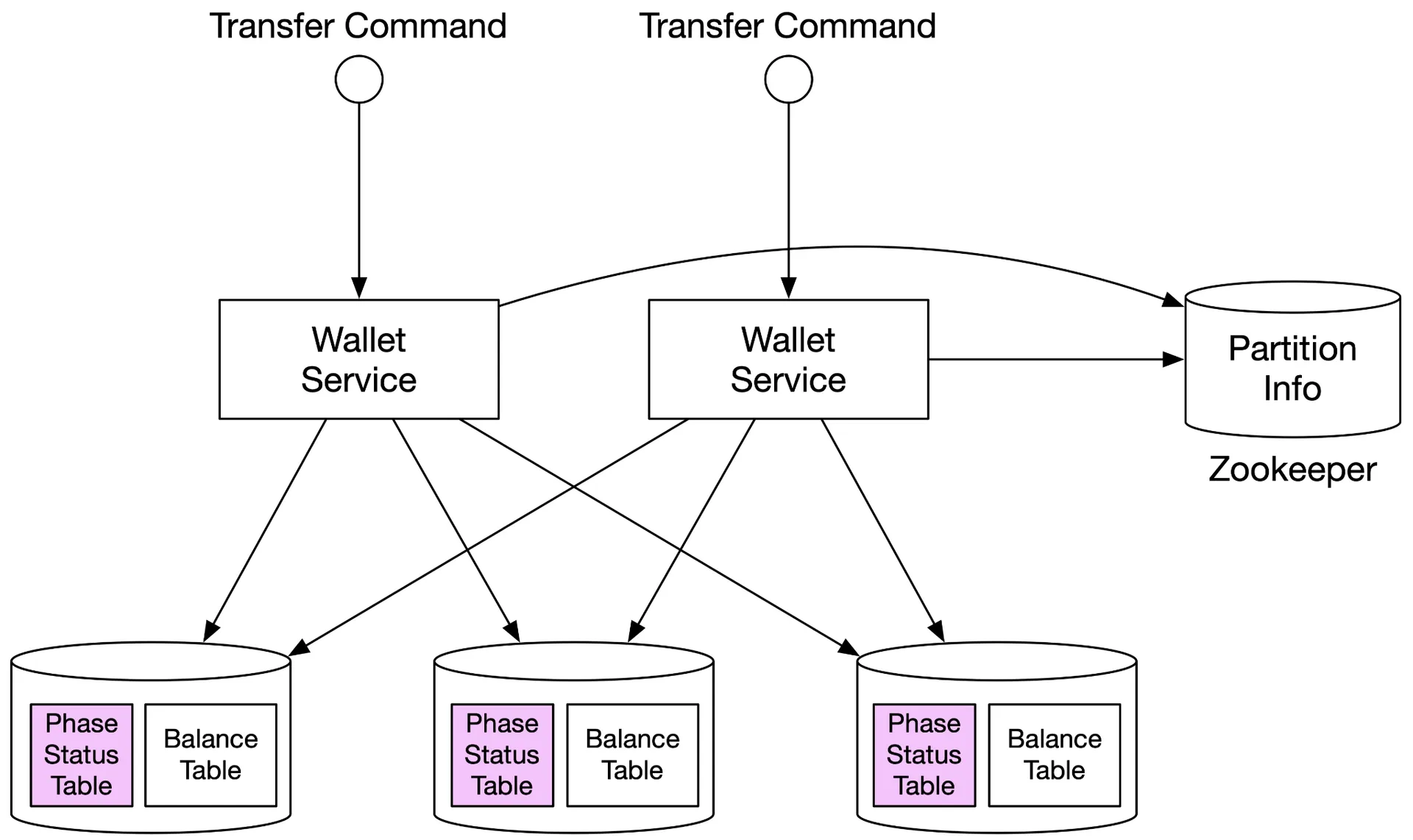
Figure 10: Phase status table
Unbalanced balance
End of Try phase: A = 0,C=0, C = 0 (A had 1,Chad1, C had 0 initially). Sum decreased — violates accounting rule. But transactional guarantee maintained. Intermediate inconsistency is normal during distributed transactions.
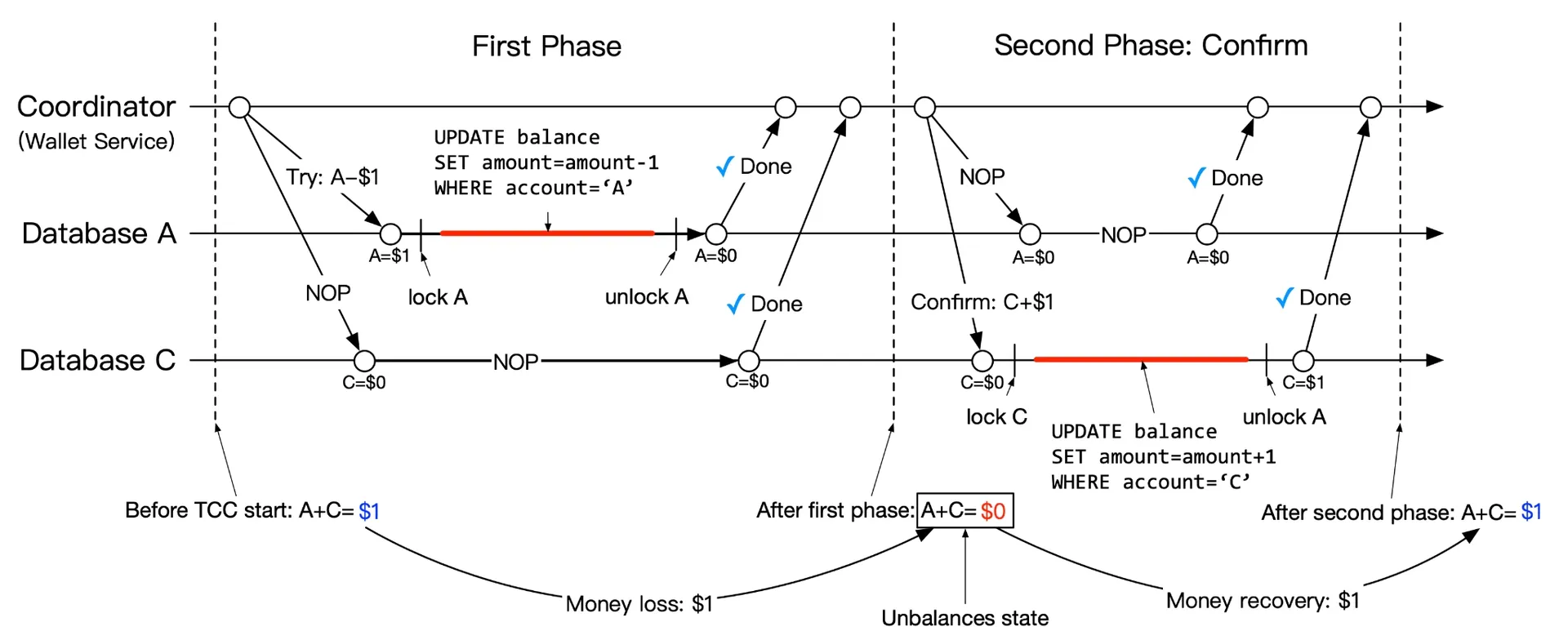
Figure 11: Unbalanced state
Valid operation orders
| Choice | Account A | Account C | Valid? |
|---|---|---|---|
| 1 | -$1 | NOP | ✓ |
| 2 | NOP | +$1 | ✗ (C gets money, then cancel can't deduct if someone else withdrew) |
| 3 | -$1 | +$1 | ✗ (too complex, fails on partial success) |
Only choice 1 is valid. Always debit first, NOP on credit in Try phase.
Out-of-order execution
Network issues → Cancel may arrive before Try. Solution:
- Cancel leaves out-of-order flag: "seen Cancel, not Try yet"
- Try checks flag → if set, return failure
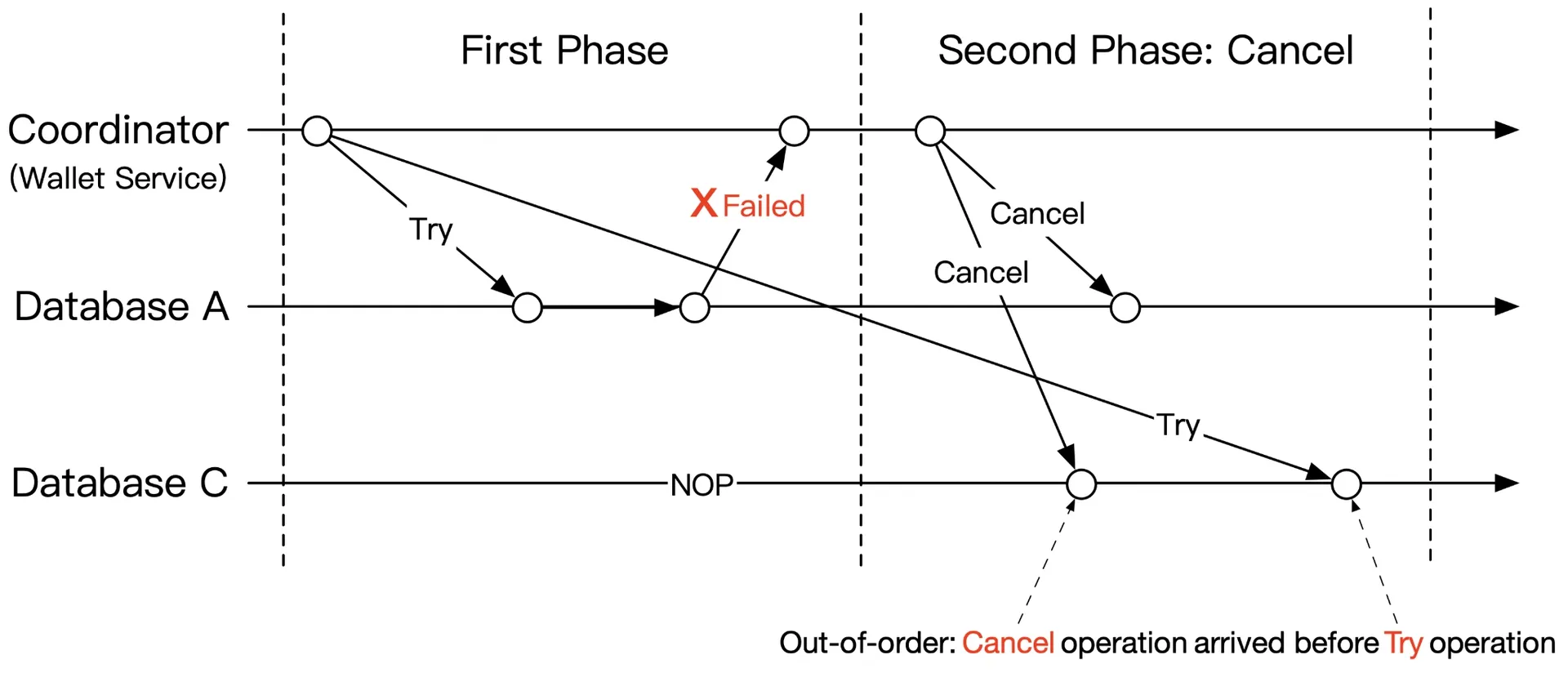
Figure 12: Out-of-order execution
Saga
De-facto standard in microservices. Linear sequence:
- Operations ordered. Each independent transaction on own DB.
- Execute sequentially. When one finishes, next triggered.
- On failure: rollback from current → first in reverse order using compensating transactions. N operations need 2N operations (N normal + N compensating).
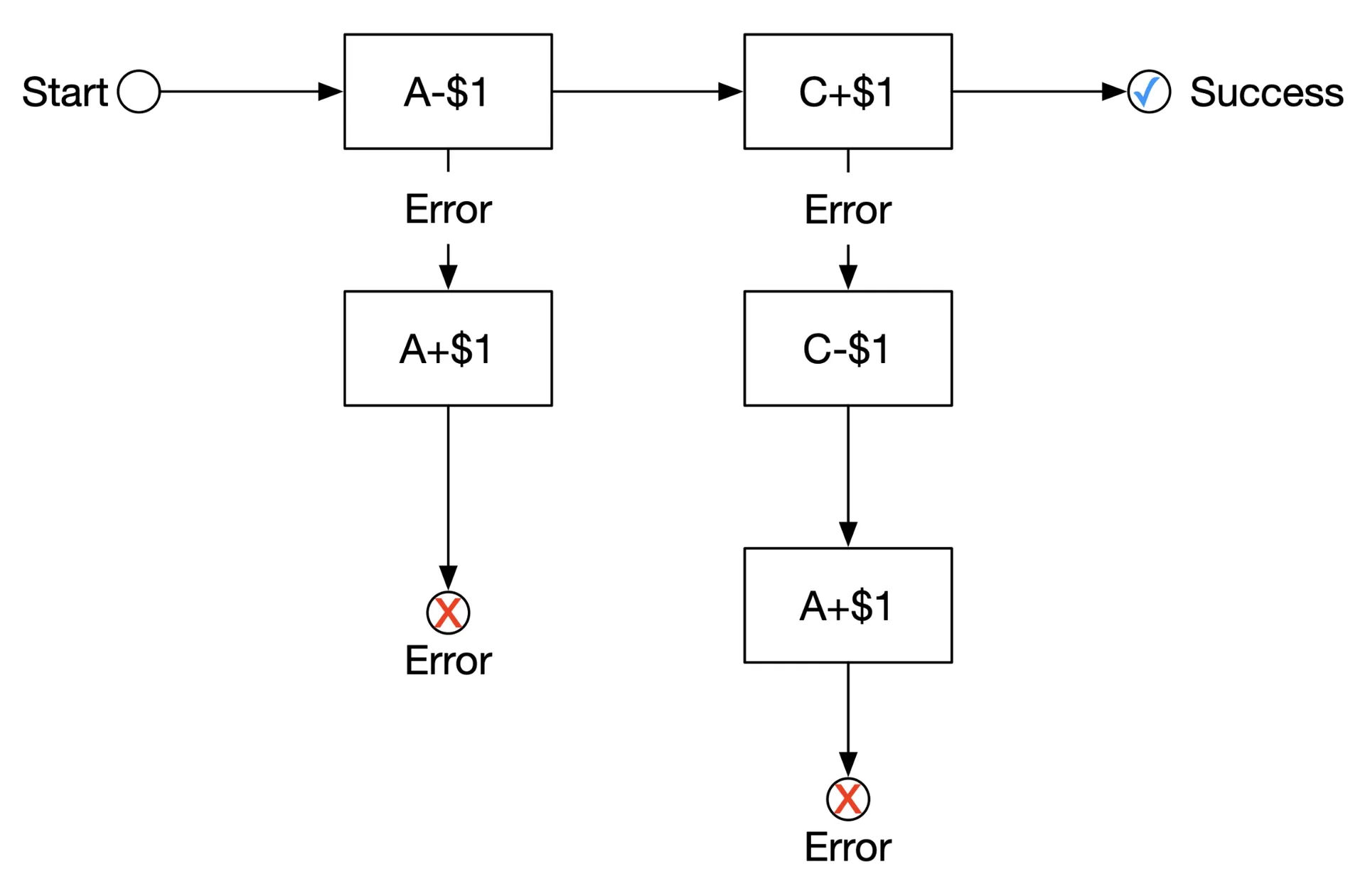
Figure 13: Saga workflow
Coordination:
- Choreography: services subscribe to each other's events (decentralized). Hard to manage with many services.
- Orchestration (preferred): single coordinator instructs services in order.
TC/C vs Saga
| TC/C | Saga | |
|---|---|---|
| Compensating action | In Cancel phase | In rollback phase |
| Central coordination | Yes | Yes (orchestration) |
| Operation order | Any | Linear |
| Parallel execution | Yes | No |
| Sees partial inconsistency | Yes | Yes |
| Logic location | Application | Application |
Choice: If no latency requirement or few services → either works (Saga trending in microservices). If latency-sensitive with many services → TC/C (parallel execution).
Event sourcing
Auditor questions: Do we know balance at any time? How do we know historical/current balances are correct? How to prove correctness after code change?
Event Sourcing (DDD technique) solves all three.
Core concepts
- Command: intended action (e.g. "transfer $1 from A to C"). May be invalid. Put in FIFO queue.
- Event: validated, fulfilled fact (e.g. "transferred $1 from A to C"). Must be deterministic. Uses past tense. One command → 0+ events. Event generation may contain randomness/I/O.
- State: what changes when Event applied (account balances — map of account→balance).
- State Machine: (a) validates Commands → generates Events. (b) applies Events → updates State. Must be deterministic (no random I/O or numbers).
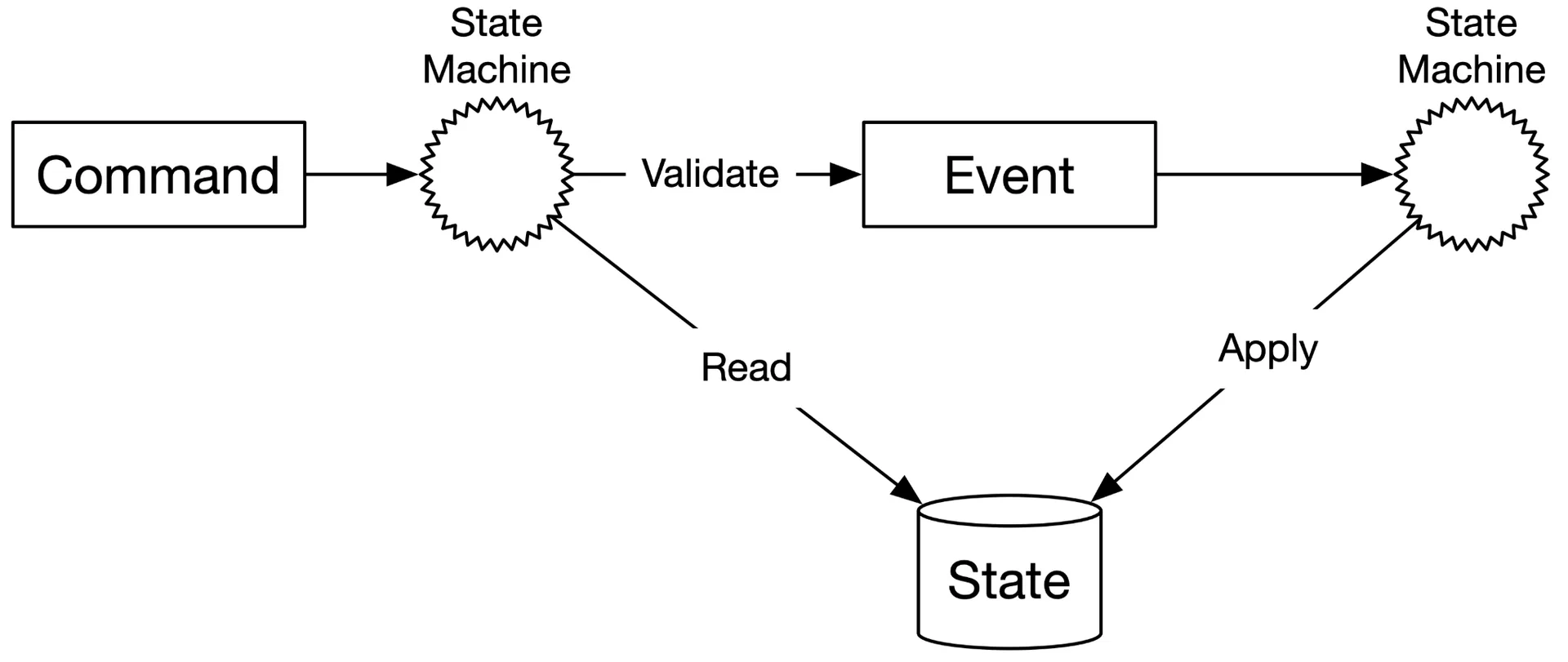
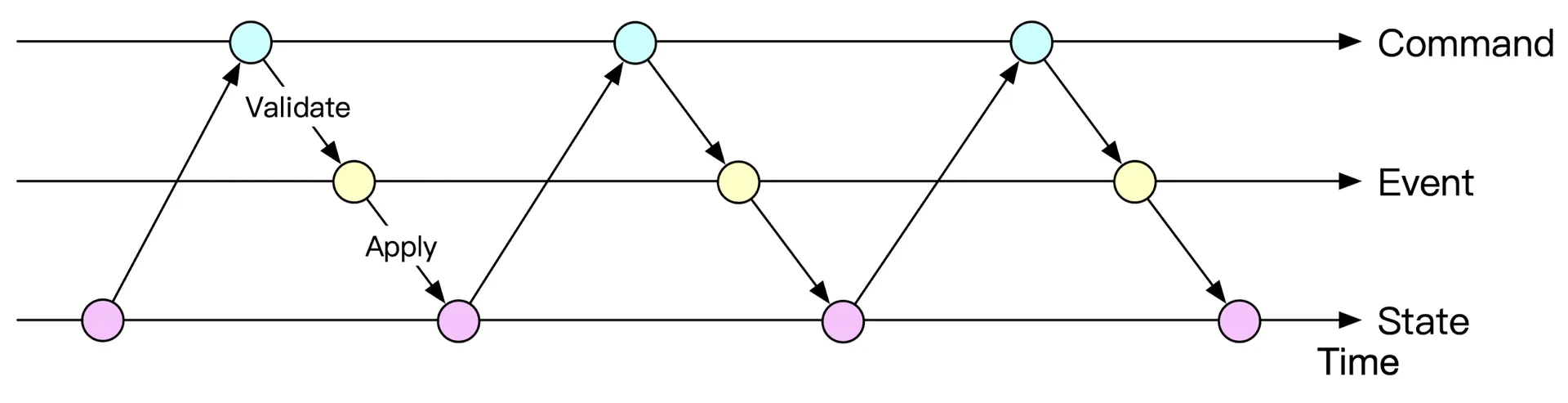
Figures 14-15: Static and dynamic views of Event Sourcing
Wallet service example
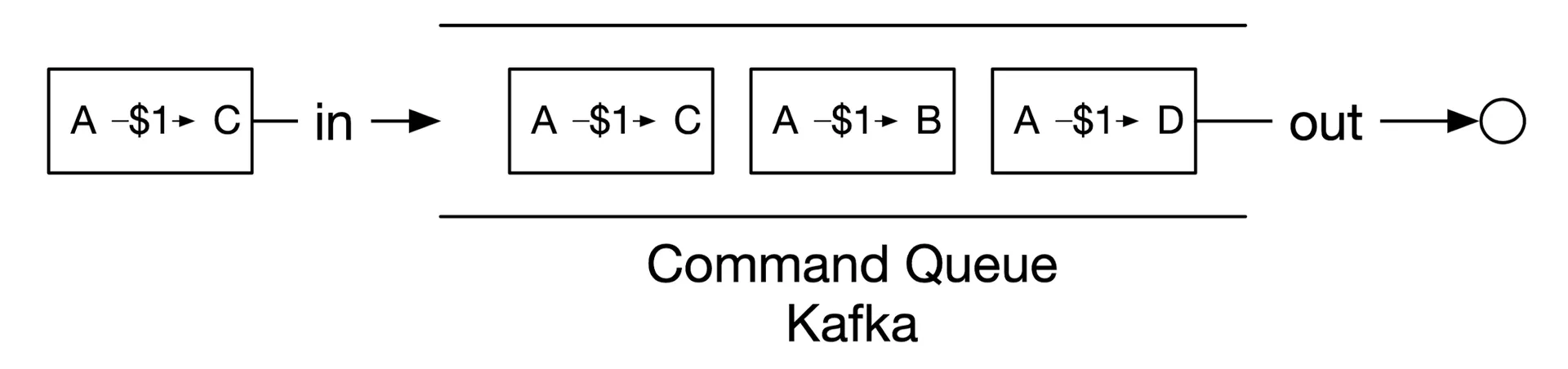
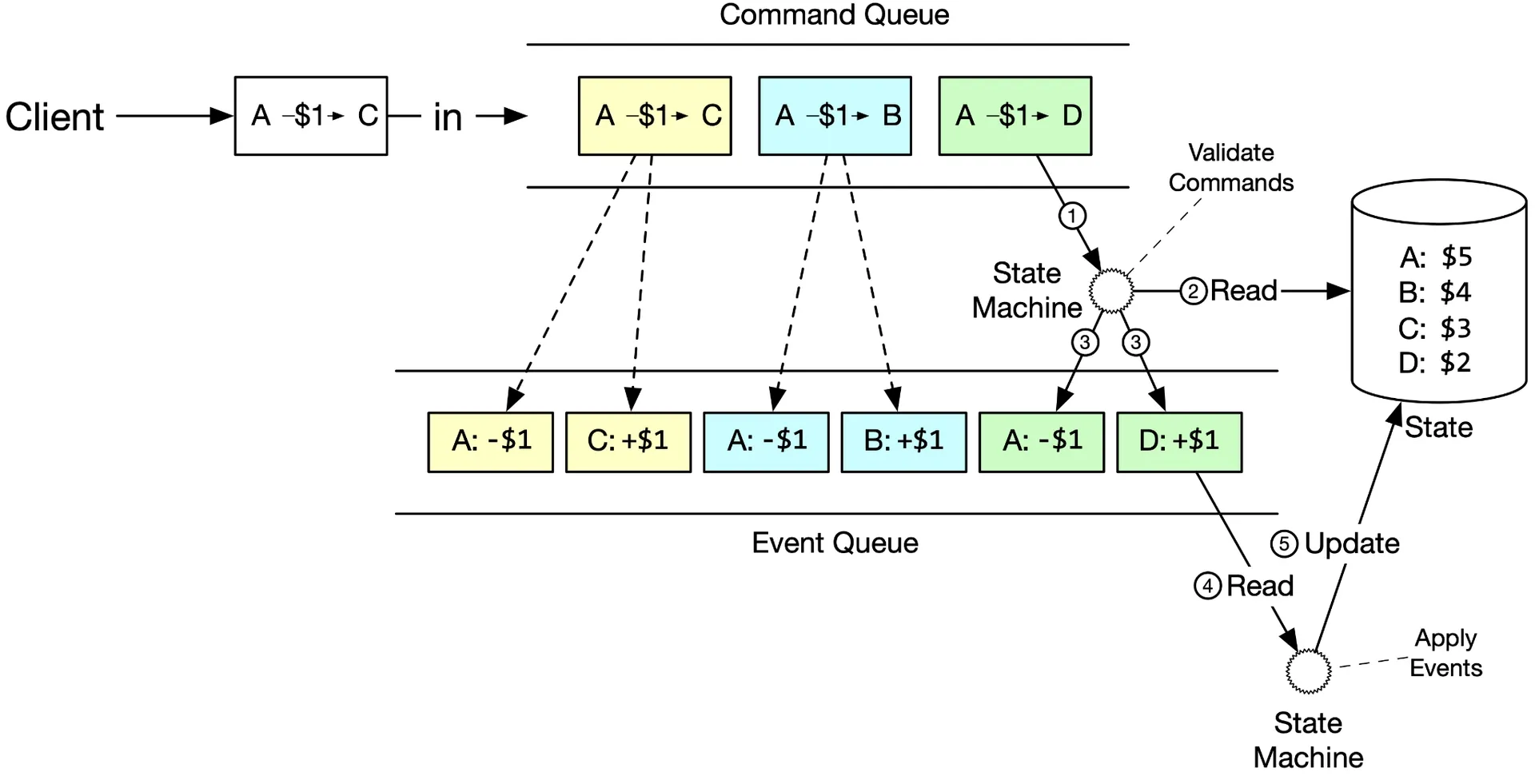
Figures 16-17: Command queue, How state machine works
Commands in Kafka. State Machine:
- Read Command from queue
- Read balance State from DB
- Validate. If valid → generate two Events (A:-1,C:+1, C:+1)
- Read next Event
- Apply Event: update DB balance
Reproducibility
All changes saved as immutable history (Event list). DB is just a view of current State. Replay events from beginning → reconstruct any historical state. Immutable Events + deterministic State Machine = identical results every replay.
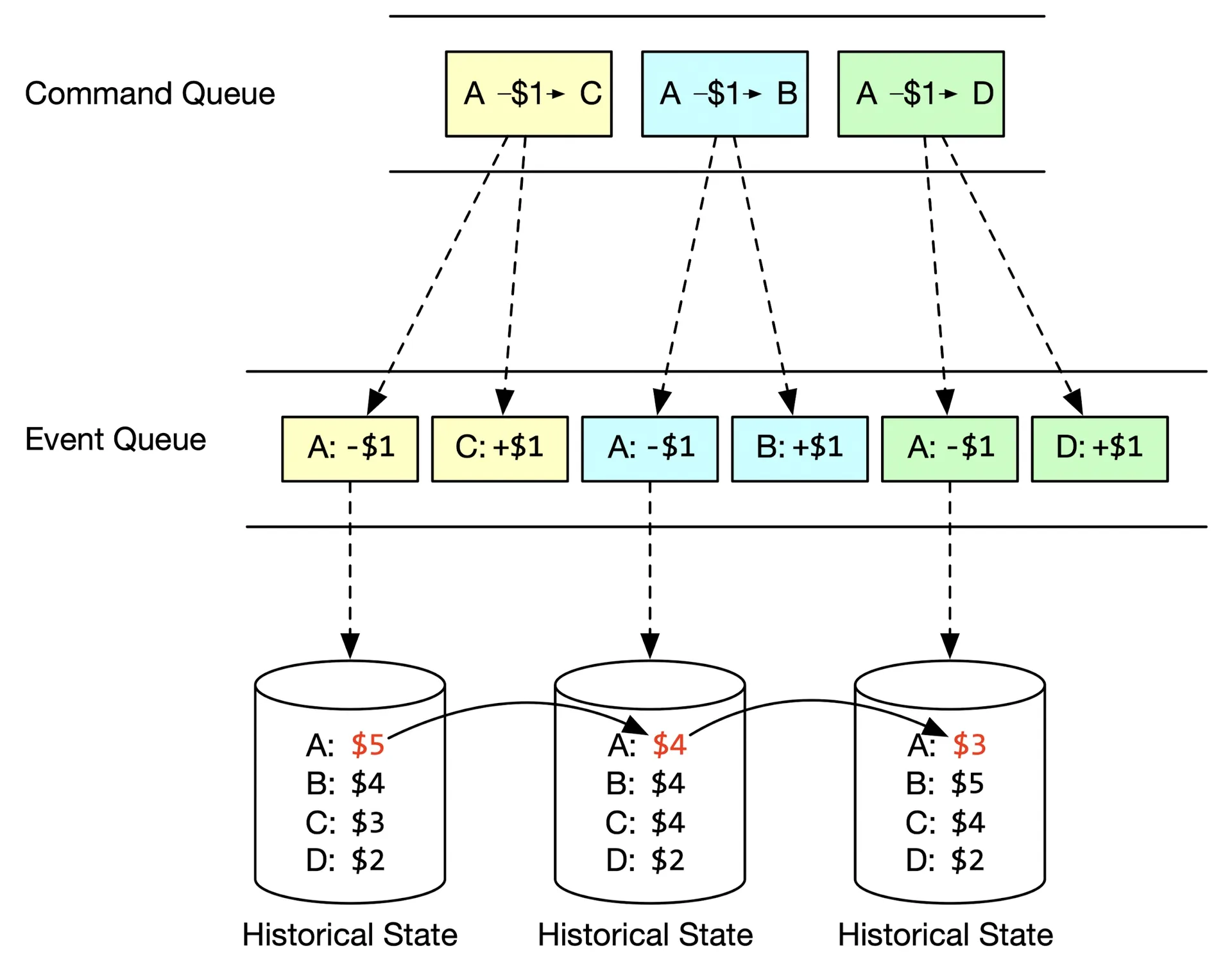
Figure 18: Reproduce states
CQRS (Command-Query Responsibility Segregation)
Rather than publishing State, Event Sourcing publishes Events. External world rebuilds custom States.
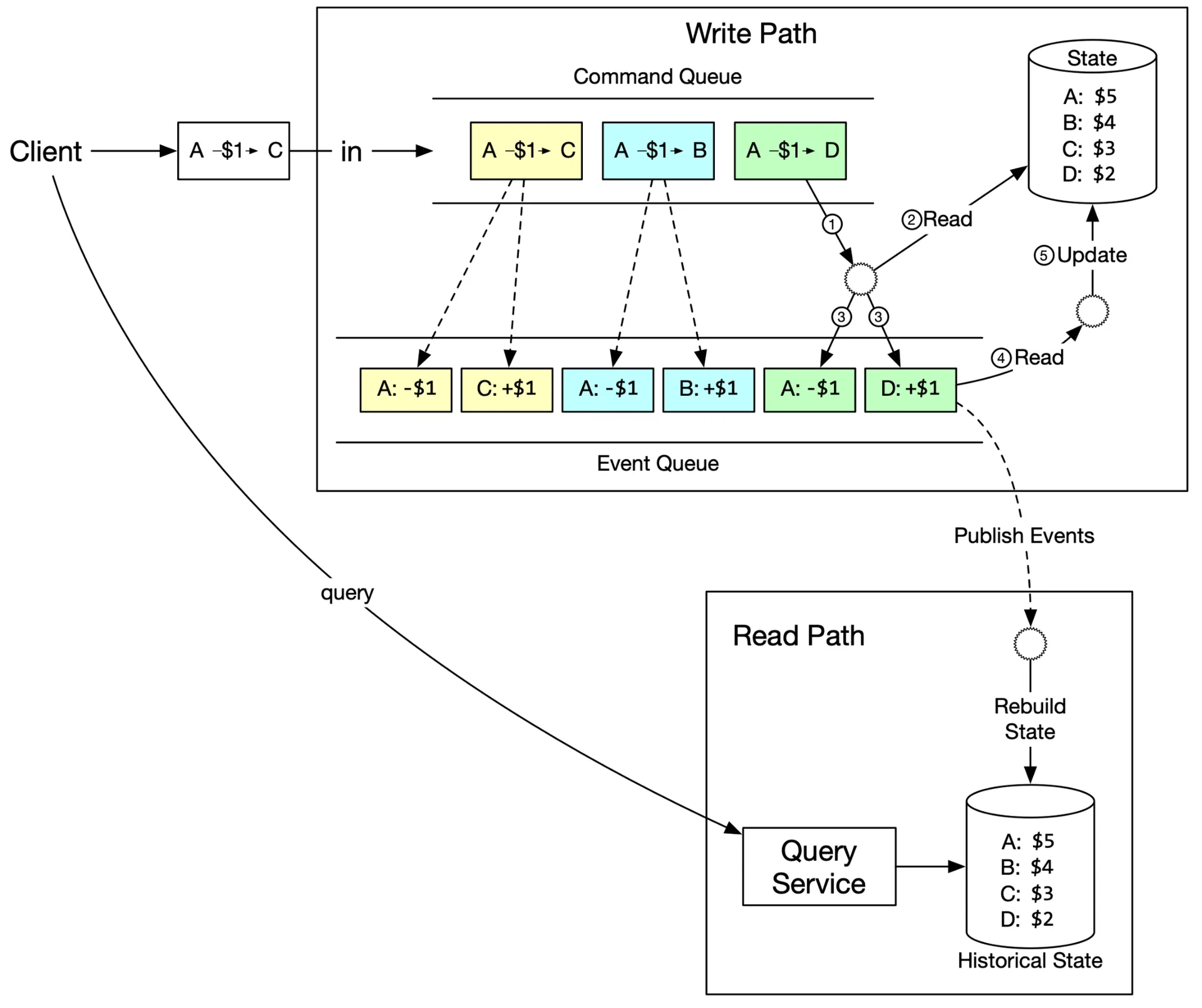
Figure 19: CQRS architecture
- One write State Machine (validates Commands, generates Events)
- Multiple read-only State Machines build different views (balance query, hourly audit trail, etc.)
- Eventually consistent (lag, but catch up)
Step 3 - Design Deep Dive
High-performance event sourcing
File-based Command and Event list
Optimization 1: Save Command/Event to local disk (append-only file) instead of remote Kafka. Sequential writes are fast (faster than random memory access in some cases). Avoids network transit.
Optimization 2: Cache recent Commands/Events in memory. Use mmap — maps disk file to memory array. OS caches file sections in memory. Append-only → nearly all data in memory.
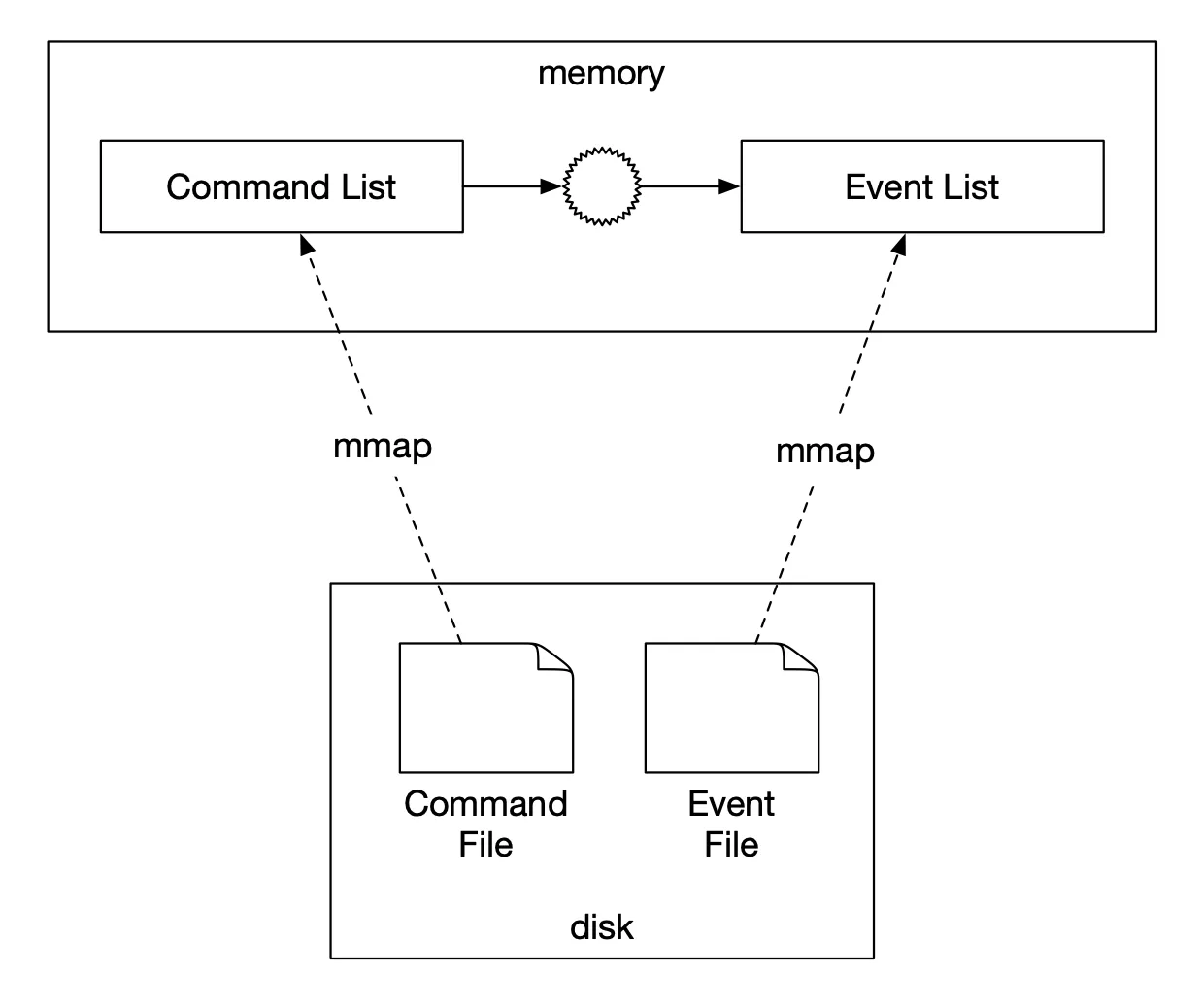
Figure 20: File-based command and event storage
File-based State
Replace remote relational DB with local file-based store: RocksDB (LSM-based, write-optimized, caches recent data for reads). Or SQLite (file-based relational).
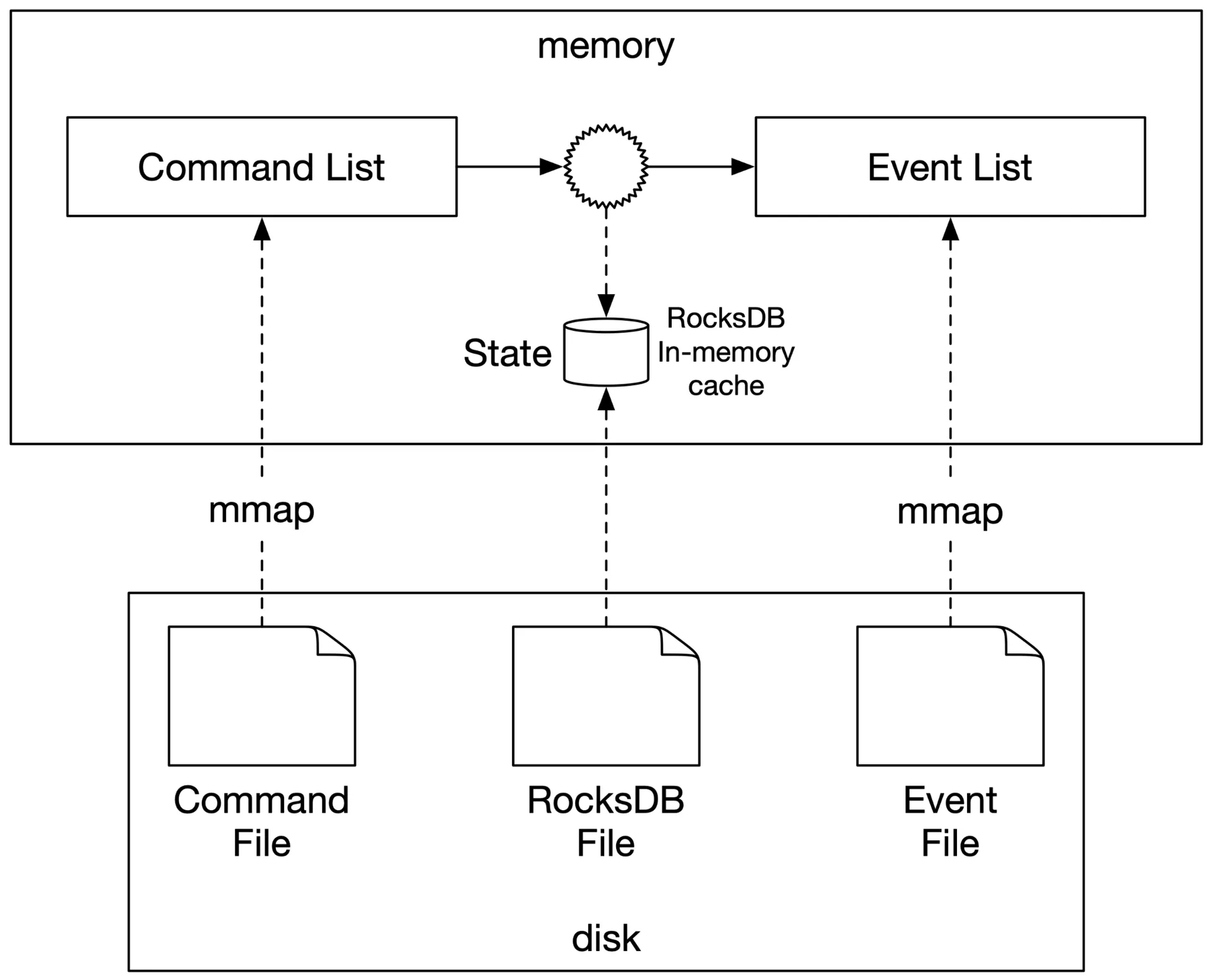
Figure 21: File-based solution
Snapshot
To accelerate reproducibility: periodically save current State to immutable snapshot file. State Machine resumes from snapshot (not from beginning). Common for finance: snapshot at 00:00 for daily verification. Stored in object storage (HDFS).
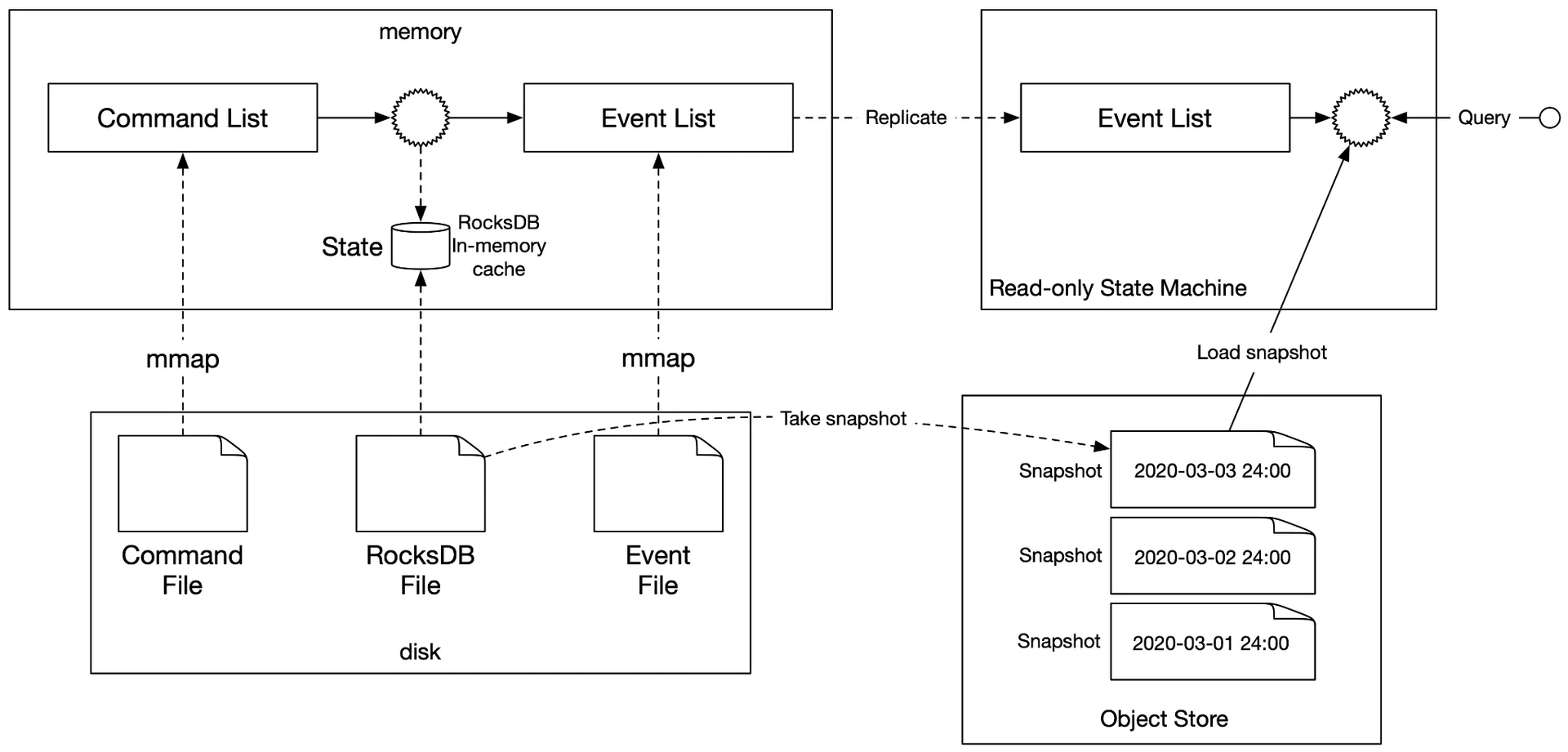
Figure 22: Snapshot
Reliable high-performance event sourcing
Reliability analysis
4 data types: Command, Event, State, Snapshot.
- State + Snapshot: regenerable from Event list.
- Command: Event generation may contain randomness/I/O → not deterministic → can't guarantee reproducibility of Events from Commands.
- Event: immutable, represents historical facts, can rebuild State. Only Event needs high-reliability guarantee.
Raft consensus
Replicate Event list across multiple nodes. Requirements: no data loss, same relative order across nodes.
Raft roles: Leader, Candidate, Follower. Leader receives external commands, replicates data. Majority online = system works. 3 nodes tolerate 1 failure, 5 nodes tolerate 2 failures.
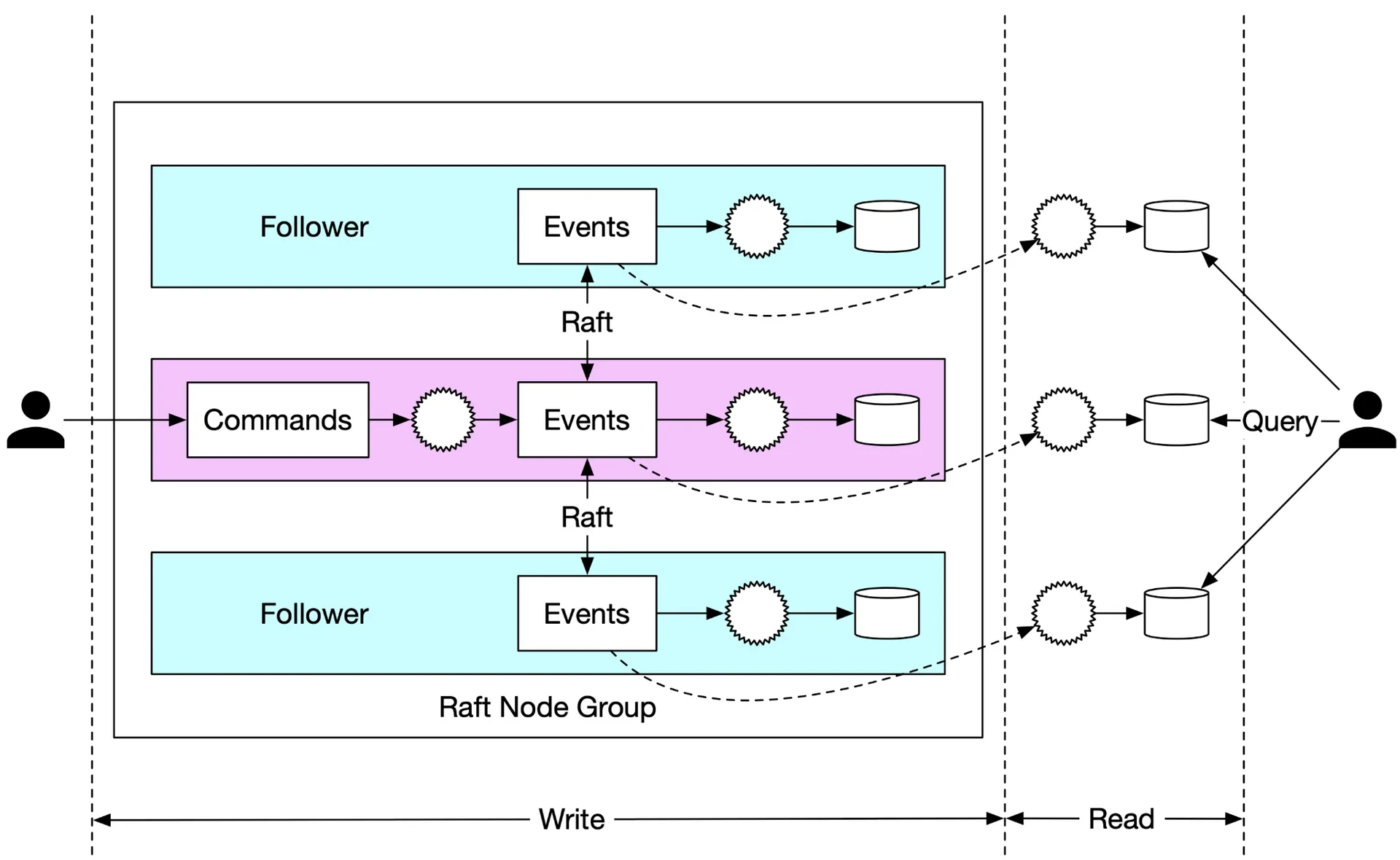
Figures 23-24: Raft, Raft node group
Architecture: 3 Event Sourcing nodes, Raft-synchronized Event lists. Leader accepts Commands → converts to Events → appends to local Event list → Raft replicates to followers. All nodes process Event list → update State. Identical Event lists → identical States.
Failure handling:
- Leader crash: Raft elects new leader from healthy nodes. Client resends Command (timeout/error detected).
- Follower crash: retry until restart or replacement.
Distributed event sourcing
Two limitations:
- CQRS pull model not real-time.
- Single Raft group capacity limited → need sharding + distributed transactions.
Pull vs push
Pull: client periodically polls read-only State Machine. Not real-time, can overload service.
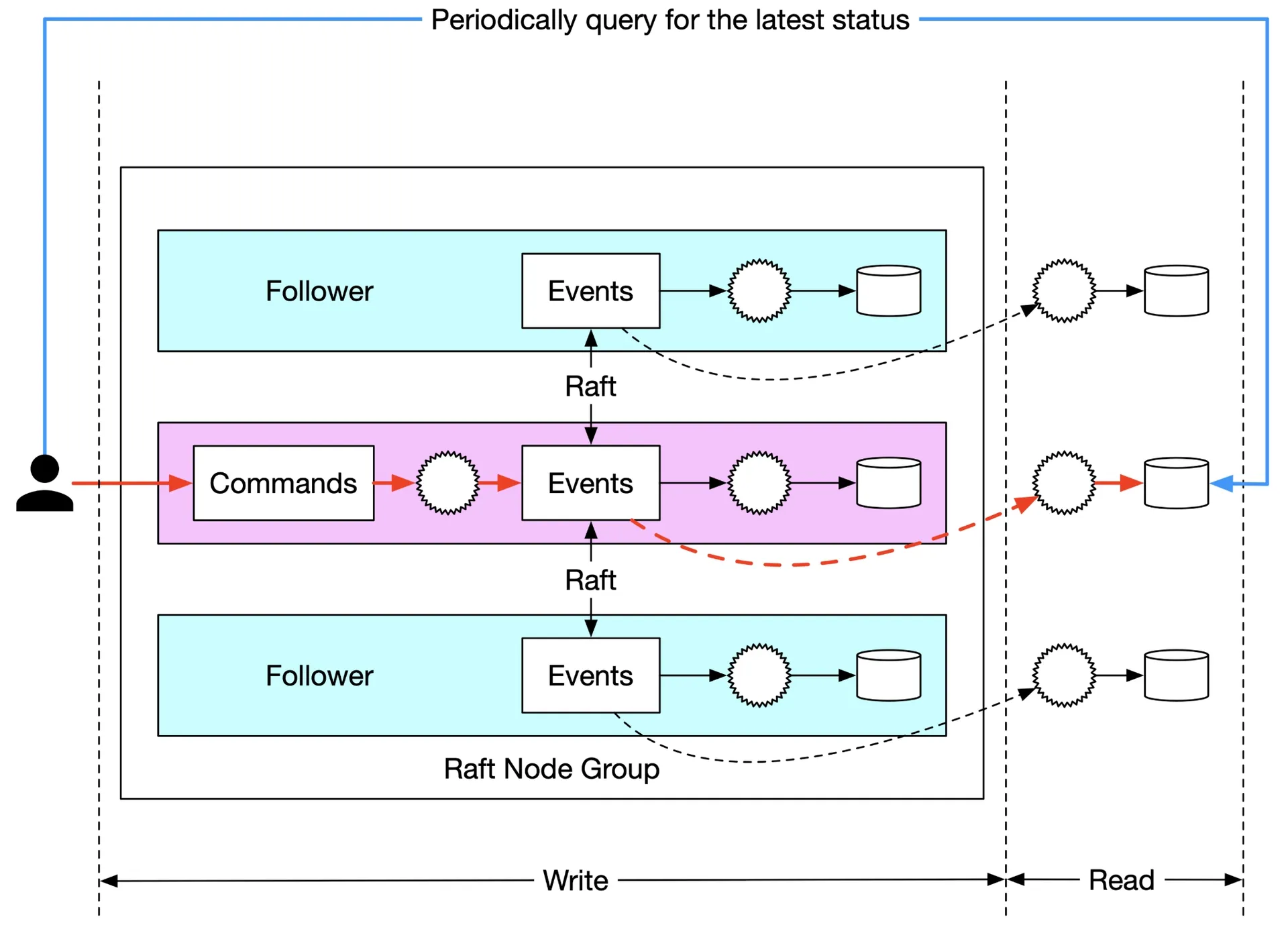
Figure 25: Periodical pulling
Reverse proxy: proxy forwards Command, polls status. Simplifies client, still not real-time.
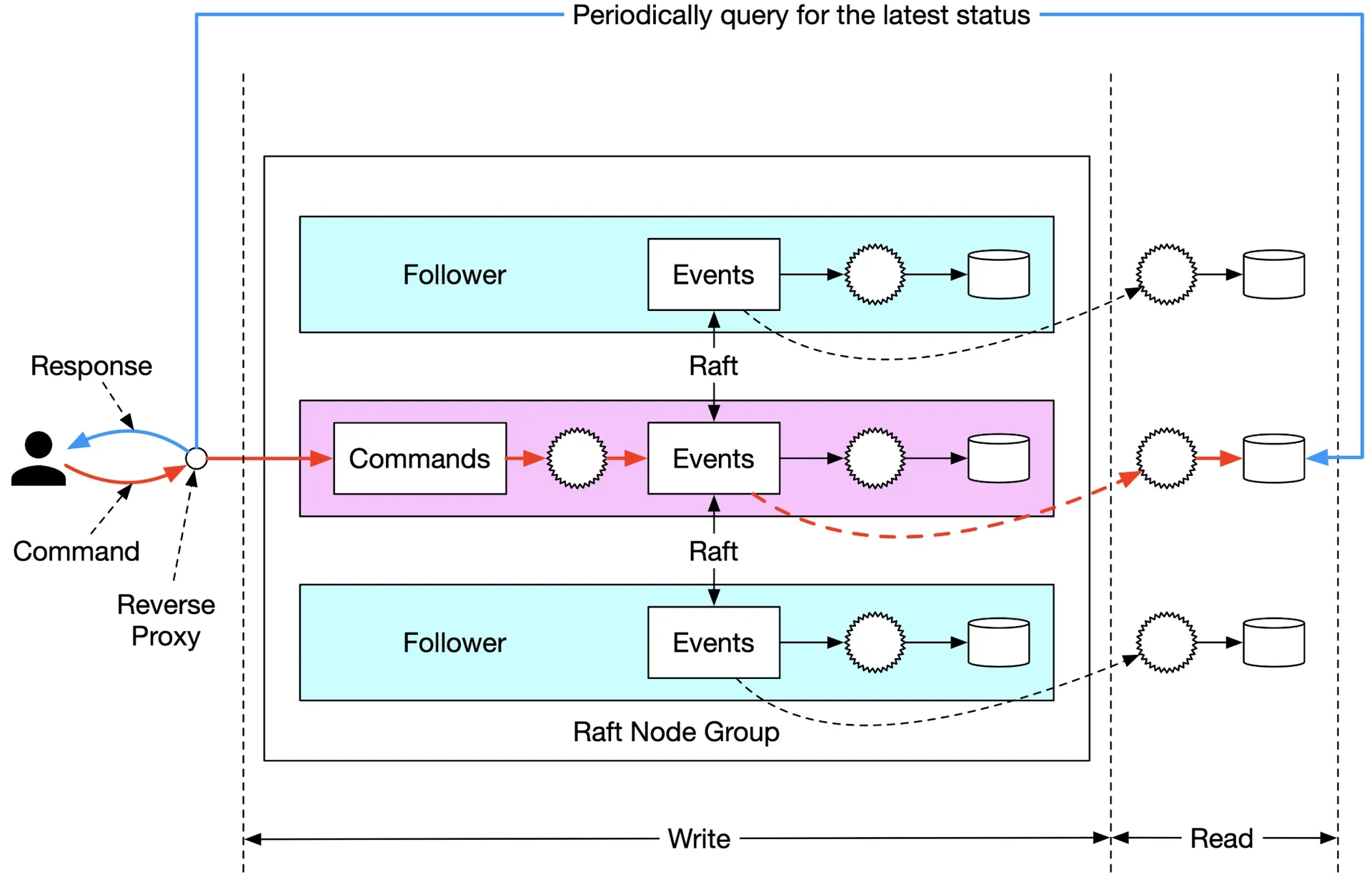
Figure 26: Pull model with reverse proxy
Push model: read-only State Machine pushes execution status to reverse proxy immediately on receiving Event → feels real-time.
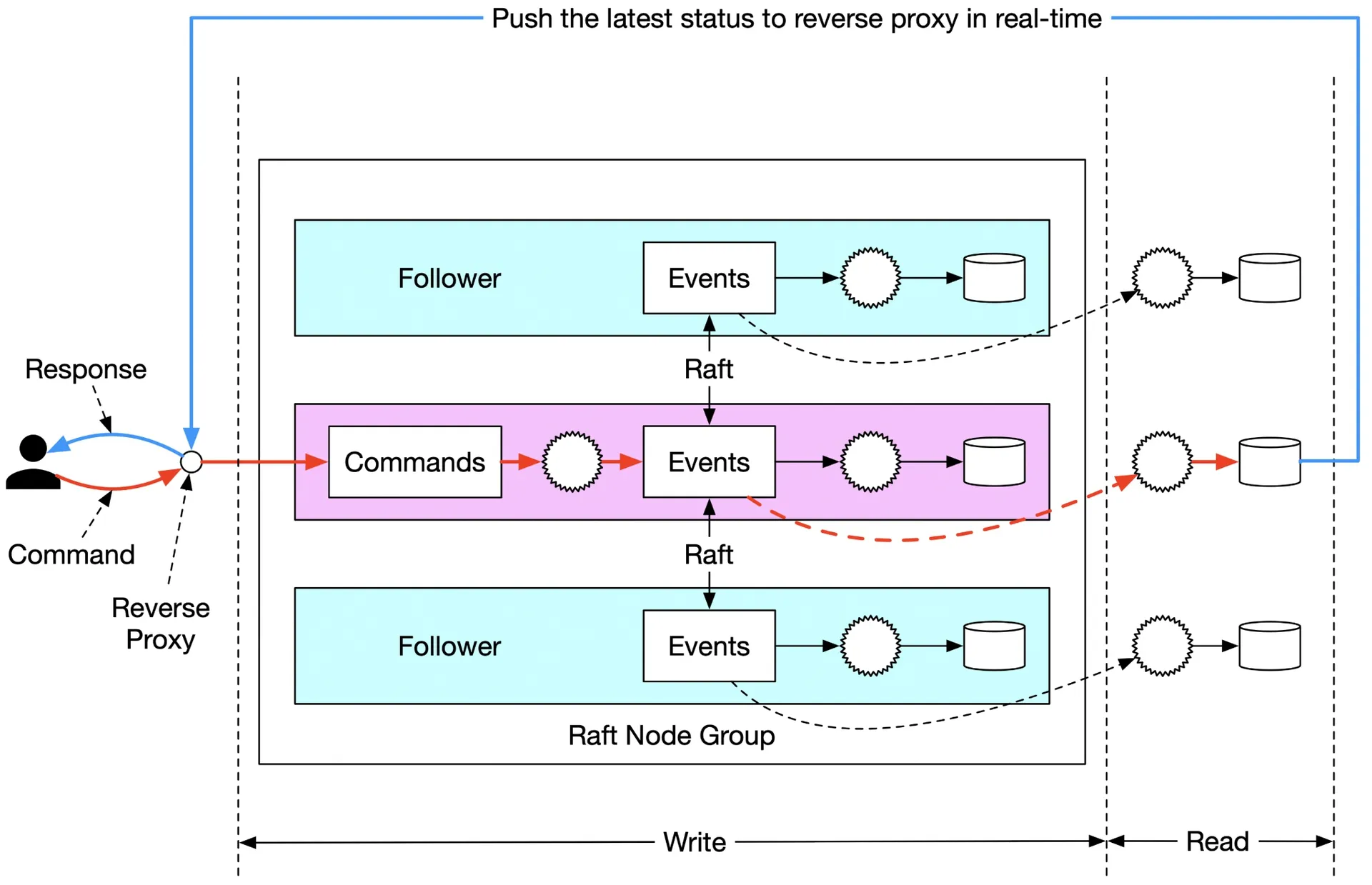
Figure 27: Push model
Distributed transaction (Final design)
Shard by hash(key) % 2. Use Saga coordinator.
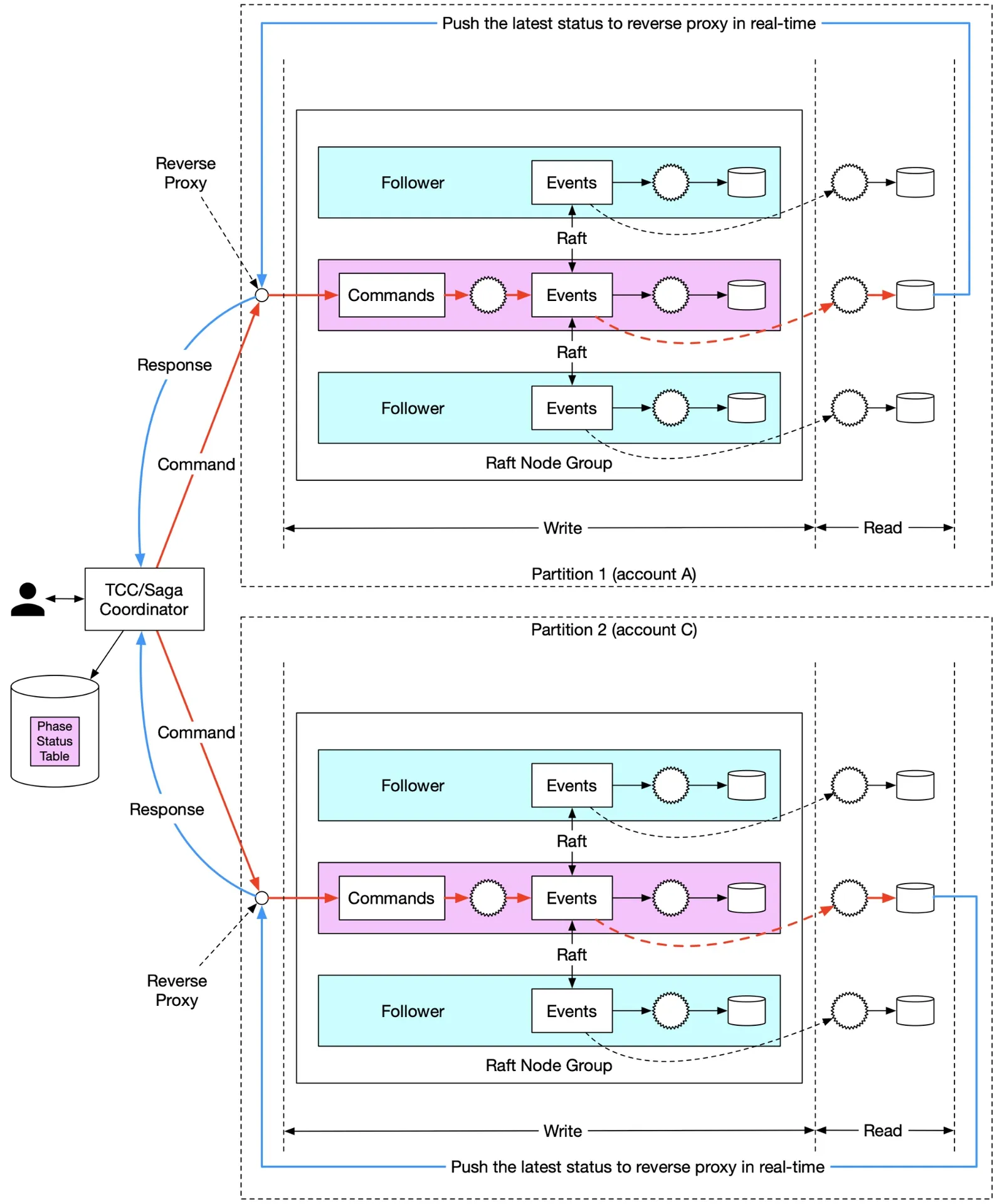
Figure 28: Final design
Happy path (Saga, transfer $1 A→C):
- User A → Saga coordinator: distributed transaction (A:-1,C:+1, C:+1)
- Coordinator creates Phase Status record
- Coordinator sends A:-$1 Command to Partition 1 (account A)
- Partition 1 Raft leader: stores Command → validates → converts to Event → Raft syncs → applies Event (deduct $1)
- Partition 1 CQRS syncs data to read path → rebuilds state + execution status
- Read path pushes status → Saga coordinator 7-8. Coordinator records Partition 1 success in Phase Status table
- Coordinator sends C:+$1 Command to Partition 2 (account C)
- Partition 2 Raft leader: stores → validates → converts → syncs → applies Event (add $1)
- Partition 2 CQRS syncs to read path → rebuilds state + status
- Read path pushes status → Saga coordinator 13-14. Coordinator records Partition 2 success
- All operations succeed → distributed transaction complete → respond to caller