Data pre-processing
Discretization
Binarization
Convert continuous or numerical data into binary values (0, 1) based on some thresholds.
Example
We have listen counts of user and want to determine taste of user. Listen counts is not a robust measure of user taste (Users have different listening habits)
With binarization can transform listen counts into binary values. For example, if listen count >= 10 then map to 1 else map to 0
Binning (Quantization)
Group continuous data into bins (Map continuous data to discrete or categorical one).
- Need to decide bins size (width of each bin)
Here are some interesting methods of binning
Fixed-width binning
Each bin has specific numeric range, it can be any scale (custom designed, automatically segment, linear, exponential)
- Simple
- It may be good on uniformly distributed (fairly even spread)
Example
Custom Designed : Binning age of people with Stage of life
0 - 12 years old 12 - 17 years old 18 - 24 years old …
Exponential-width binning (Relate to Log Transform) : When data has a wide range of values
0 - 9 10 - 99 100 - 999 …
Fixed-frequency binning
Each interval contains approximately the same number of data points
- When data is not uniformly distributed, we can ensure that each bin contains approximately the same number of data points
Example
Data = [0, 4, 12, 16, 16, 18, 24, 26, 28] Range = (-, 14] [14, 21] [21, +)
Bin 1 : [0, 4, 12] Bin 2 : [16, 16, 18] Bin 3 : [24, 26, 28]
Quantile Binning
Binning base on quantiles (values that divide the data into equal portions)
4-Quantile = Quartiles (Divide data into quarters) 10-Quantile = Deciles (Divide data into tenths)
Steps In K - Quantile = [] To find position of value of boundary between quantile, find
- K = Number of quantile
- n = Number of data in dataset
- i = Number of Quantile
Example
A lot of empty bins when do fixed width-binning so quantile binning come to help
Data = [1, 1, 1, 2, 2, 3, 4, 4, 10, 10, 10, 500, 1000] Let divide data into Quartiles (4-Quantile) so n = 13 and K = 4
Quantile-1 has [1, 1, 1, 2, 2, 3] Quantile-2 has [4, 4] Quantile-3 has [10, 10, 10] Quantile-4 has [500, 1000]
Imbalanced Techniques - Sampling and SMOTE
Imbalanced occur when one class in dataset has more samples than another class. It can be caused by
- Bias while sampling
- Error from measurement
- Natural of that data
Majority Class = Many samples class Minority Class = few samples class
It harder for a model to learn characteristic of Minority Class + some models are assume an equal distribution of class so imbalance can cause problem.
Note
We focus on target variable class
Sampling
Random Under-sampling
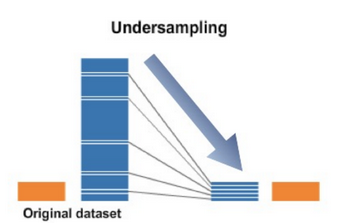
Randomly eliminate samples from majority class until classes distribution balance
When training data is not that small, we can afford under-sampling
Advantages
- Reduce model training time: fewer data points
Disadvantages
- Reduced dataset not represent population or true distribution
- May loss useful data
Random Over-sampling
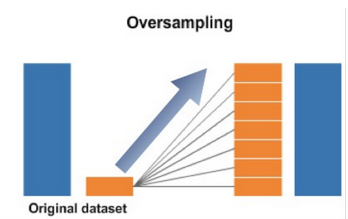
Randomly copy samples in minority class to get more balance distribution
When training data is less, over-sampling would be better than under-sampling
Advantages
- No information loss
Disadvantages
- Overfitting
Synthetic over-sampling: SMOTE
Take subsets of minority class then generate synthetic data points from those subsets and add those new data points to dataset.
It solve overfitting problem of over-sampling
Advantages
- Help with overfitting problem
- No data loss
Disadvantages
- No consideration of majority class
- Addition noise to dataset
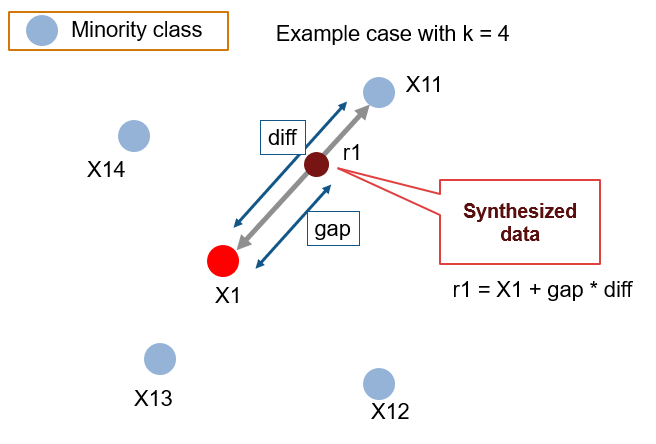
How does SMOTE generate new data points
- Finding Nearest Neighbors
- Creating Synthetic Data Points: Do Interpolation
- For each feature dimension, SMOTE calculates a difference value between the selected data point and one of its neighbors.
- It then multiplies this difference by a random value between 0 and 1.
- Finally, it adds this scaled difference to the feature value of the selected data point to create a new synthetic data point.
- Repeat
Dimensional Reduction - PCA
PCA reduces a large number of variables into a set of Principle Component axes.
Why we need to do dimension reduction
Most of the time, we have dataset which has high dimension (many columns or features), we can’t visualize those datasets so dimension reduction lend a hand to help with this problem.
Dimension Reduction algorithm will try to preserve all information in higher dimension data and reduce those data into 2-3D where we can visualize and understand(in other word, extract feature out of those high-dimensional data) them.
It can apply prior to applying some models which get affected a lot by Curse of Dimensionality
How to perform PCA
Ref: https://www.youtube.com/watch?v=MLaJbA82nzk
| Feature | ||||
|---|---|---|---|---|
| x | 4 | 8 | 13 | 7 |
| y | 11 | 4 | 5 | 14 |
| Number of features = n = 2 | ||||
| Number of samples = N = 4 |
Features Mean Calculation
Covariance Matrix Let Ordered Pairs are (x, x) (x, y) (y, x) (y, y)
- Find covariance of all ordered pairs
Calculate Eigen value and Eigen Vector then Normalized eigen vector
- Eigen value
where
- Eigen Vector of
- Normalize the eigen vector get unit eigen vector
Derive new dataset
| P11 | P12 | P13 | P14 | |
|---|---|---|---|---|
| PC1 | -4.3052 | 3.7561 | 5.6928 | -5.1238 |
Tip
Before apply PCA, Standardizing is important step!
- PCA seeks to maximize the variance of each component and Standardizing is a variance maximizing exercise
Model Evaluation
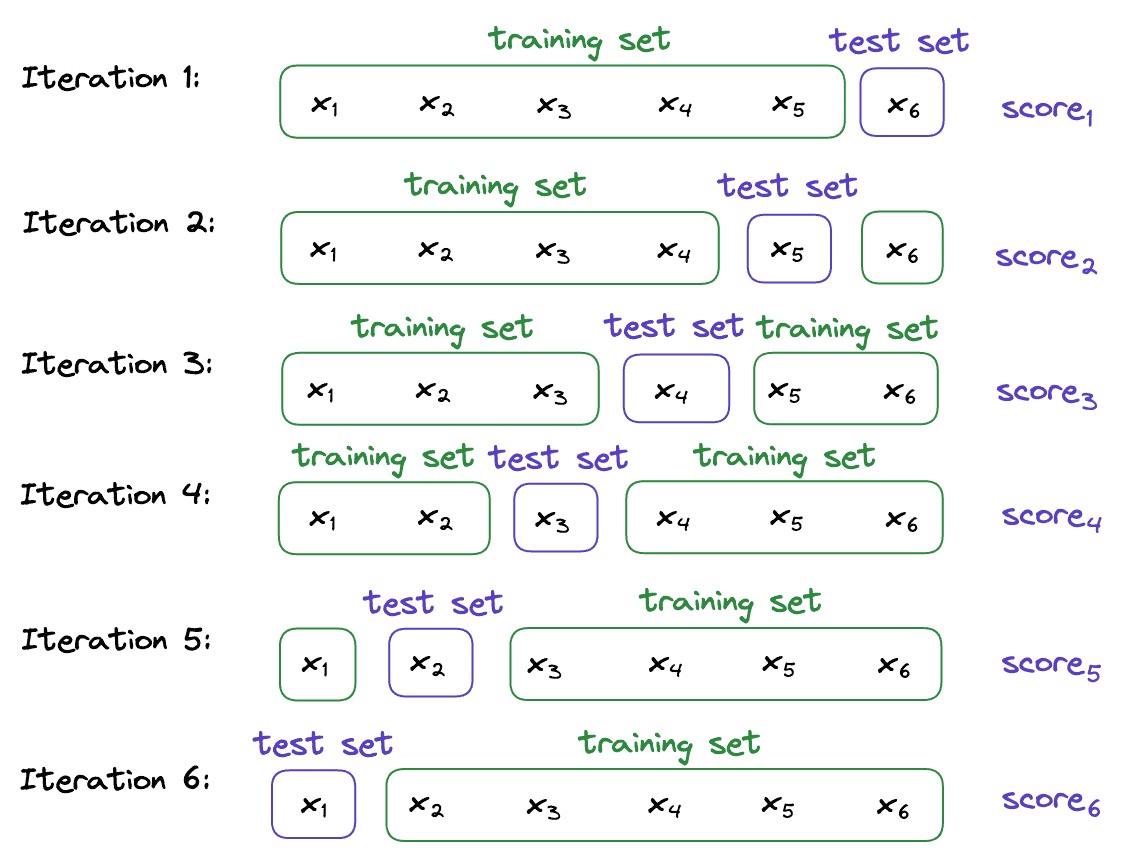
Cross-Validation
Technique to evaluate predictive models by partitioning the original sample into a training set to train the model and a test set to evaluate it.
There are many interesting methods those use cross-validation technique.
We can also use the cross validation set to tune model hyperparameters and test with test set later.
Holdout method
Separate dataset into two sets training set and testing set
- Use training set to train only and then predict testing set and validate the model on it
K-fold cross validation
Randomly divide dataset into K equal-size parts, , use K-1 part as training set and the left one is Validation set
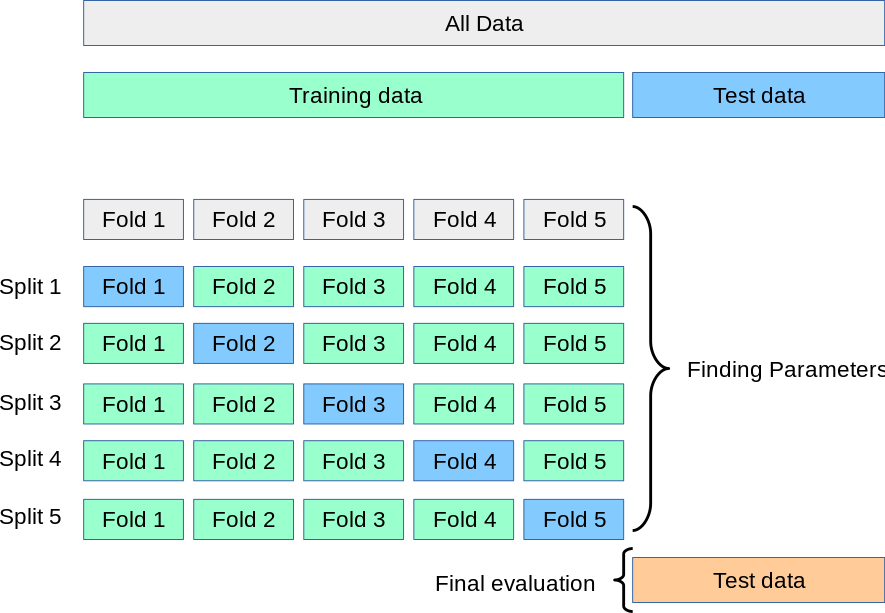
Advantage
- Good to use when don’t have a large enough dataset (When a single, random sample of the data is not representative sample of the underlying distribution)
**Disadvantage
- K have effect, larger K larger training sets that overlap more, leading to a stronger dependence between the results in the K folds
- Expensive computational time
Leave-one-out cross validation
Extreme case of K-fold cross validation, only one sample is used as a Validation set while the rest are used to train our model
Partitioning Clustering
Data clustering concept
- Grouping similar data points together based on certain criteria
- Unsupervised Learning
- Use Distance/Similarity Metric
The goal of clustering is to discover natural groupings or clusters in the data without any prior knowledge of the groupings.
Pre-processing for clustering
- Normalize the data
- Remove noises or outliers
- Approach few numbers of dimensions (dimensional reduction)
K-means
How to perform K-means
Let
\begin{document}
\begin{tikzpicture}[scale=0.7]
\coordinate (A1) at (3,8);
\coordinate (A2) at (9,4);
\coordinate (A3) at (4,9);
\coordinate (A4) at (2,2);
\coordinate (A5) at (10,5);
\coordinate (A6) at (2,4);
\coordinate (A7) at (6,8);
\coordinate (A8) at (4,3);
\coordinate (A9) at (4,7);
\foreach \point in {A1, A2, A3, A4, A5, A6, A7, A8, A9}
\fill (\point) circle (3pt);
\foreach \point/\label in {A1/A1, A2/A2, A3/A3, A4/A4, A5/A5, A6/A6, A7/A7, A8/A8, A9/A9}
\node[above right] at (\point) {\label};
\draw[help lines,gray!30] (0,0) grid (12,10);
\foreach \x in {1,2,...,12}
\node[below] at (\x,0) {\x};
\foreach \y in {1,2,...,10}
\node[left] at (0,\y) {\y};
\draw[->] (0,0) -- (12,0) node[right] {$x$};
\draw[->] (0,0) -- (0,10) node[above] {$y$};
\end{tikzpicture}
\end{document}In this problem we will use
Goal: Find member and centroid of each cluster
Step
- Choose K-centroid randomly (It can be any points)
- Find the nearest centroid for each point and assign each point to those centroid
In this problem we use Euclidean Distance
Let assume that we have assigned each point to its nearest centroid using Euclidean distance as a matric distance and get this result.
- j1 has [A1, A3, A7, A9]
- j2 has [A4, A6, A8]
- j3 has [A2, A5]
- Find new centroid and see if cluster member change or not
- If cluster member remain the same : Finish!
- If cluster member change : Find new centroid again!
from j = 1 to K
where
Example
| j | centroid | ||
|---|---|---|---|
| 1 | |||
| 2 | |||
| 3 |
- j1 has [A1, A3, A7, A9]
- j2 has [A4, A6, A8]
- j3 has [A2, A5]
Member of cluster is not changed so FINISH!
Result
\begin{document}
\begin{tikzpicture}[scale=0.7]
\coordinate (A1) at (3,8);
\coordinate (A2) at (9,4);
\coordinate (A3) at (4,9);
\coordinate (A4) at (2,2);
\coordinate (A5) at (10,5);
\coordinate (A6) at (2,4);
\coordinate (A7) at (6,8);
\coordinate (A8) at (4,3);
\coordinate (A9) at (4,7);
\foreach \point/\label/\color in {A1/A1/blue, A2/A2/yellow, A3/A3/blue, A4/A4/green, A5/A5/yellow, A6/A6/green, A7/A7/blue, A8/A8/green, A9/A9/blue}
\fill[\color] (\point) circle (3pt) node[above right, \color] {\label};
\coordinate (C1) at (4.25,8);
\coordinate (C2) at (2.667,3);
\coordinate (C3) at (9.5,4.5);
\foreach \centroid/\label in {C1/c1, C2/c2, C3/c3}
\fill[red] (\centroid) circle (5pt) node[below right] {\label};
\foreach \point/\centroid/\color in {A1/C1/blue, A3/C1/blue, A7/C1/blue, A9/C1/blue, A4/C2/green, A6/C2/green, A8/C2/green, A2/C3/yellow, A5/C3/yellow}
\fill[\color] (\point) circle (3pt);
\draw[help lines,gray!30] (0,0) grid (12,10);
\foreach \x in {1,2,...,12}
\node[below] at (\x,0) {\x};
\foreach \y in {1,2,...,10}
\node[left] at (0,\y) {\y};
\draw[->] (0,0) -- (12,0) node[right] {$x$};
\draw[->] (0,0) -- (0,10) node[above] {$y$};
\end{tikzpicture}
\end{document}Clustering Evaluation
Elbow Method
Help choose the right number of clusters for your clustering algorithm by plot graph between the number of clusters and the sum of squared distances
Within Cluster Sum of Squares - WCSS
then plot on graph where y is WCSS and x is Number of clusters
Association Rule
Apriori Algorithm
Ref: https://www.youtube.com/watch?v=rgN5eSEYbnY
Goal : get frequent itemset which is a set of data that tend to happen together.
Step
| Customer ID | Transaction ID | Item Bought |
|---|---|---|
| 1 | 0001 | {a, d, e, f} |
| 1 | 0024 | {a, b, c, e} |
| 2 | 0012 | {a, b, d, e} |
| 2 | 0031 | {a, c, d, e} |
| 3 | 0015 | {b, c, e} |
| 3 | 0022 | {b, d, e} |
| 4 | 0029 | {c, d} |
| 4 | 0040 | {a, b, c} |
| 5 | 0033 | {a, d, e} |
| 5 | 0038 | {a, b, e} |
| Let minimum support 40% |
- Filter item with minimum support
Filter out the item which Support < Minimum support
| Transaction ID | a | b | c | d | e | f |
|---|---|---|---|---|---|---|
| 0001 | 1 | 1 | 1 | 1 | ||
| 0024 | 1 | 1 | 1 | 1 | ||
| 0012 | 1 | 1 | 1 | 1 | ||
| 0031 | 1 | 1 | 1 | 1 | ||
| 0015 | 1 | 1 | 1 | |||
| 0022 | 1 | 1 | 1 | |||
| 0029 | 1 | 1 | ||||
| 0040 | 1 | 1 | 1 | |||
| 0033 | 1 | 1 | 1 | |||
| 0038 | 1 | 1 | 1 | |||
| Count | 7 | 6 | 5 | 6 | 8 | 1 |
| 10 | 10 | 10 | 10 | 10 | 10 | |
| Support | 70% | 60% | 50% | 60% | 80% | 10% |
| Pass? | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
- Create itemset
To create itemset
2-Itemset
| Product | Support | Pass? | ||
|---|---|---|---|---|
| {a, b} | 4 | 10 | 40% | ✅ |
| {a, c} | 3 | 10 | 30% | ❌ |
| {a, d} | 4 | 10 | 40% | ✅ |
| {a, e} | 6 | 10 | 60% | ✅ |
| {b, c} | 3 | 10 | 30% | ❌ |
| {b, d} | 2 | 10 | 20% | ❌ |
| {b, e} | 5 | 10 | 50% | ✅ |
| {c, d} | 2 | 10 | 20% | ❌ |
| {c, e} | 3 | 10 | 30% | ❌ |
| {d, e} | 5 | 10 | 50% | ✅ |
3-Itemset
| Product | Support | Pass? | ||
|---|---|---|---|---|
| {a, b ,c} | 4 | 10 | 40% | ✅ |
| {a, c, d} | 1 | 10 | 10% | ❌ |
| {a, d, e} | 4 | 10 | 40% | ✅ |
| {b, c, e} | 2 | 10 | 20% | ❌ |
| … | … | … | … | … |
4-Itemset
| Product | Support | Pass? | ||
|---|---|---|---|---|
| {a, b ,c, e} | 1 | 10 | 10% | ❌ |
| {a, b, d, e} | 1 | 10 | 10% | ❌ |
| {a, c, d, e} | 1 | 10 | 10% | ❌ |
| … | … | … | … | … |
- Get Association Rule and Calculate Confidence and Lift
Association define as
If A exist in transaction then B tend to exist too. For example, If Customer 1 buy A then he tend to buy B too.
We usually call
| Antecedent | Consequent | Association Rule |
|---|---|---|
| {b} | {a, d, e} | |
| {a, d, e} | {b} | |
| … | … | … |
Confidence
Measures how often a rule is true
- if A occurs, B is likely to occur
Minimum Confidence set a minimum line for confidence
Let say, minimum confidence = 0.2
| Association Rule | Support(A, B) | Support(A) | Confifence(A B) | Pass Minimum Confidence |
|---|---|---|---|---|
| ❌ | ||||
| ✅ | ||||
| … | … | … | … | … |
Lift
Measure of the strength of the association between two items
- Lift greater than 1 indicates that the presence of item A has a positive effect on the presence of item B
Decision Trees and Random Forest
Terminology
Node Impurity
Node is like a dataset or subset of data in decision tree. Pure Node is a subset where all samples are in the same class
| A | B | Class |
|---|---|---|
| 1 | 22 | + |
| 22 | 3213 | + |
| 12 | 32 | + |
Impure Node is a subset where samples has same portion of classes (#Class + = Class -)
Entropy
Entropy of a random variable is the average level of “information”, “surprise”, or “uncertainty” inherent to the variable’s possible outcomes
When we measure entropy of something, it like we measure how much information we need to describe that thing or measure randomness in the system
In decision tree algorithm, entropy measure impurity in the Node
- Pure Node: entropy = 0 (no impurity + need only few information to describe that node) low randomness
Example
Find entropy of this Node S where class label are + and -.
| Height | Race | Sex | Class |
|---|---|---|---|
| 160 | Asian | F | + |
| 170 | Hispanic | F | + |
| 180 | White | M | - |
| 170 | White | M | + |
| 180 | Asian | M | - |
| Probability that person will be + is 3/5 = 0.6 | |||
| Probability that person will be - is 2/5 = 0.4 |
NOTE: when , entropy = 0 ()
Information Gain
In decision tree, information gain measure how much entropy will be reduced after each split
- Compute the difference between entropy before split and average of entropy after the split
- Less reduction of entropy More Information Gain
Information gain help us select best feature to use to split the data at each internal node of the decision tree
- Feature with the highest information gain is chosen as the split feature
Example
Let use the previous example where
| Height | Race | Sex | Class |
|---|---|---|---|
| 160 | Asian | F | + |
| 170 | Hispanic | F | + |
| 180 | White | M | - |
| 170 | White | M | + |
| 180 | Asian | M | - |
| Find Information Gain of Sex or GAIN(S, Sex) | |||
| {F, M} | |||
| 2 {2+, 0-} | |||
| 3 {1+, 2-} | |||
| = 5 {3+, 2-} | |||
| 0.970951 | |||
GINI Index
GINI index also measure the impurity, it is like information gain but compute differently (GINI faster to compute)
| Height | Race | Sex | Class |
|---|---|---|---|
| 160 | Asian | F | + |
| 170 | Hispanic | F | + |
| 180 | White | M | - |
| 170 | White | M | + |
| 180 | Asian | M | - |
Example
Find GINI index of Sex
2 {2+, 0-} 3 {1+, 2-} = 5 {3+, 2-}
Note
For continuous values, we need to apply discretization first.
Decision Trees
Decision Trees construction
Too lazy laew, doo this one https://www.youtube.com/watch?v=_L39rN6gz7Y
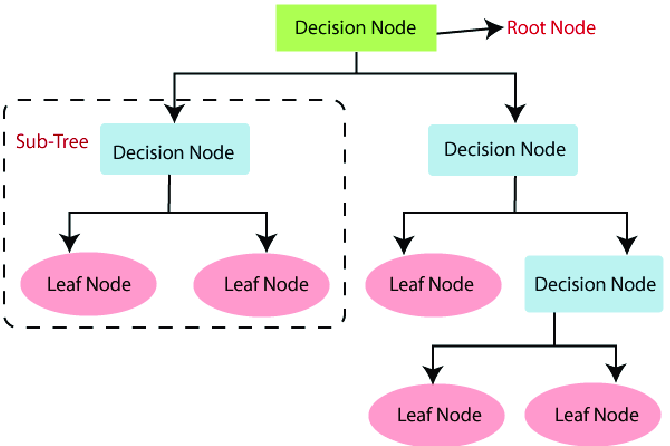
Steps
Parameters
- Max Depth: Maximum depth of the tree
- Higher depth: Lead to overfit
- Min Sample Split: Minimum sample require to split an internal node
- Prevent splitting with too few sample
- Min Sample Leaf: Minimum sample require to be leaf node
- Prevent overfitting
- Max Features: Maximum number of features to consider when splitting a node
- Criterion: GINI, Entropy
Random Forest
Pick a random subset S, of training samples
- For each subset ⇒ grow a full tree
- Given, a new data point X
- Classify X using each of the trees
- For example, use majority vote: class predicted most often
Evaluation
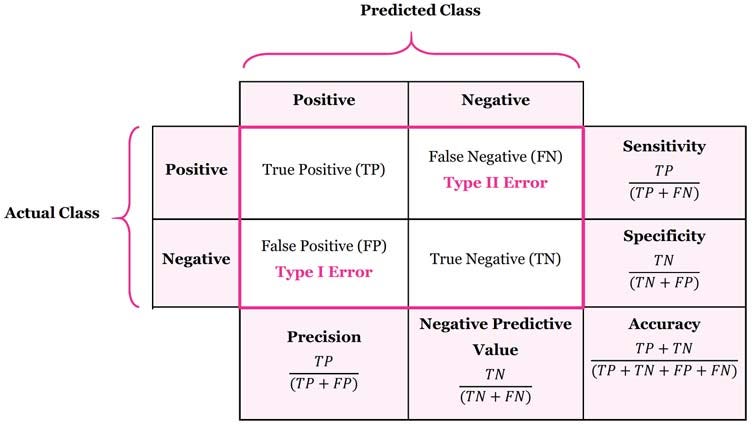
Decision Tree is mainly use as classifier so we can use Evaluate with Precision/Recall, F-Score and Confusion Matrix
Recommenders Systems
Information filtering system that implicitly or explicitly capture a user’s preference and generate a ranked list of items that might be of interest to the user.