Design a Key-Value Store
6 min readA key-value store (non-relational DB) stores unique identifier keys with associated values. Keys: plain text ("last_logged_in_at") or hashed (253DDEC4). Values: strings, lists, objects (treated as opaque). Examples: Dynamo, Memcached, Redis.
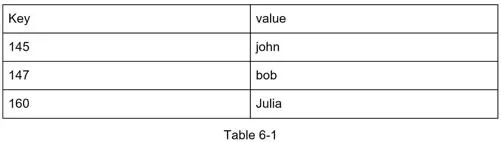
Operations: put(key, value), get(key)
Understand the problem and establish design scope
Requirements:
- Small key-value pairs: < 10 KB
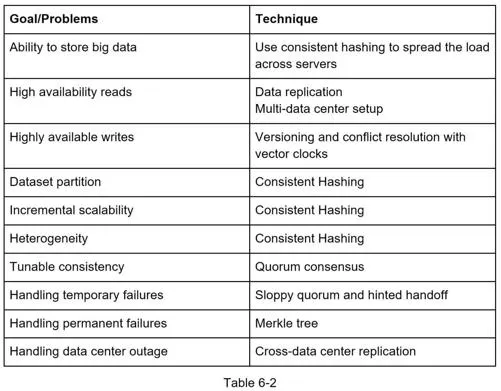
- Ability to store big data
- High availability (responds quickly during failures)
- High scalability (supports large datasets)
- Automatic scaling (add/remove servers based on traffic)
- Tunable consistency
- Low latency
Single server key-value store
Store in hash table in memory. Optimizations: data compression, keep hot data in memory + rest on disk. Single server reaches capacity quickly → need distributed key-value store.
Distributed key-value store
CAP theorem
A distributed system can simultaneously provide only two of three guarantees:
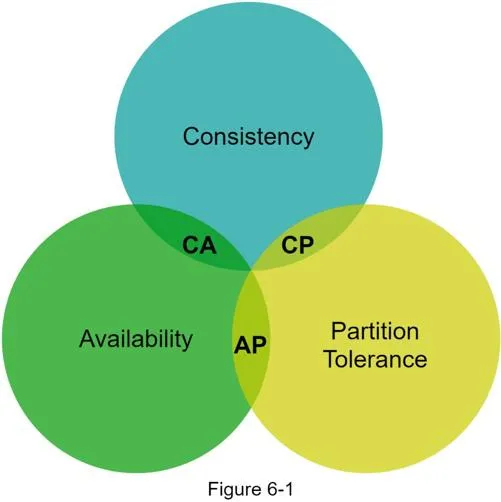
- Consistency (C): All clients see same data at same time regardless of node.
- Availability (A): Any client gets a response even if some nodes are down.
- Partition Tolerance (P): System continues operating despite network partitions.
System classifications:
- CP: Consistency + Partition Tolerance, sacrifice availability (bank systems — error if inconsistency)
- AP: Availability + Partition Tolerance, sacrifice consistency (may return stale data)
- CA: Cannot exist in real-world — network failure is unavoidable
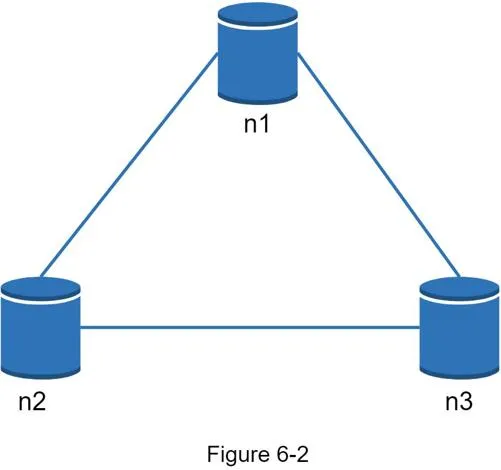
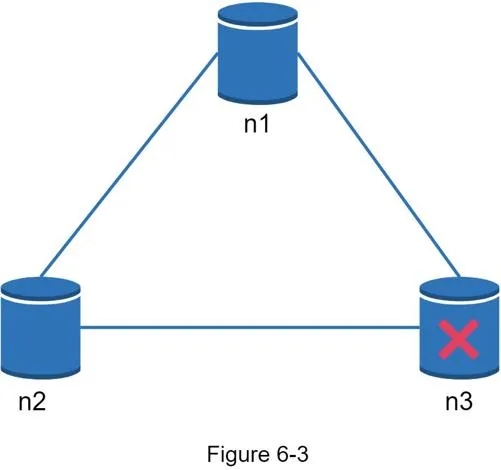
Real-world: partitions cannot be avoided. When partition occurs (n3 down), must choose CP (block writes to n1/n2) or AP (accept reads/writes, sync later).
Data partition
Use consistent hashing (Chapter 5):
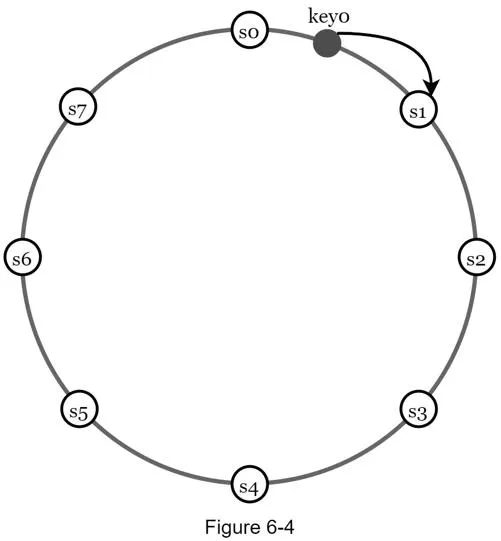
- Servers placed on hash ring (s0–s7)
- Key hashed onto same ring, stored on first server clockwise
- Automatic scaling: Servers added/removed based on load
- Heterogeneity: Virtual nodes proportional to server capacity
Data replication
Data replicated asynchronously over N servers. After mapping key to ring position, walk clockwise and choose first N unique servers.
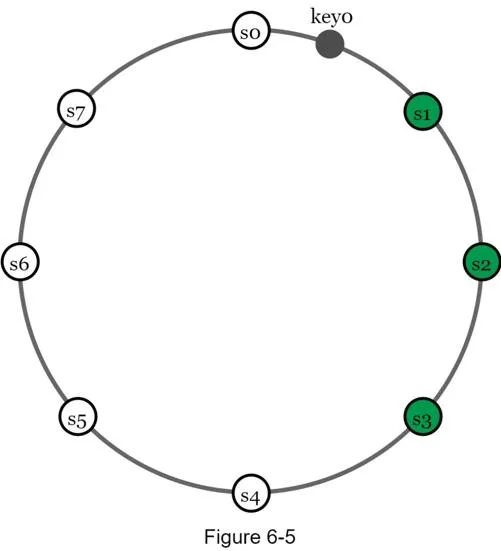
N = 3 example: key0 replicated at s1, s2, s3.
With virtual nodes, ensure physical uniqueness (first N on ring may map to < N physical servers). Place replicas in distinct data centers for reliability.
Consistency
Quorum consensus
- N = number of replicas
- W = write quorum size (writes acknowledged by W replicas = successful)
- R = read quorum size (reads wait for at least R replicas)
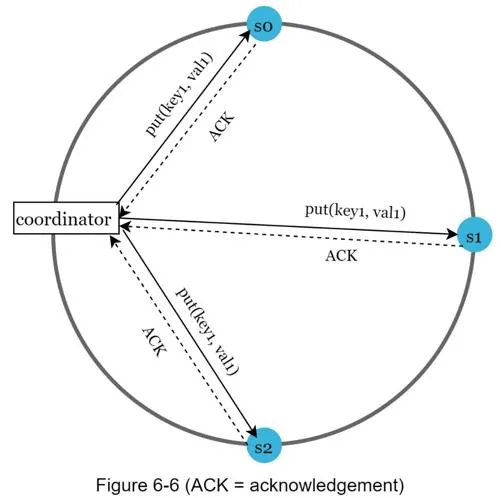
W = 1 doesn't mean data written to 1 server — means coordinator needs only 1 ack. Coordinator acts as proxy between client and nodes.
Configurations:
- R = 1, W = N → optimized for fast read
- W = 1, R = N → optimized for fast write
- W + R > N → strong consistency guaranteed (at least one overlapping node has latest data)
- W + R ≤ N → strong consistency NOT guaranteed
Typical strong consistency: N = 3, W = R = 2.
Consistency models
- Strong consistency: Read returns latest write. Achieved by blocking reads/writes until all replicas agree. Not ideal for high-availability systems.
- Weak consistency: Subsequent reads may not see latest value.
- Eventual consistency: Given enough time, all replicas become consistent. Used by Dynamo and Cassandra. Recommended model for this design.
Inconsistency resolution: versioning
Replication causes inconsistencies among replicas. Versioning treats each modification as new immutable version.
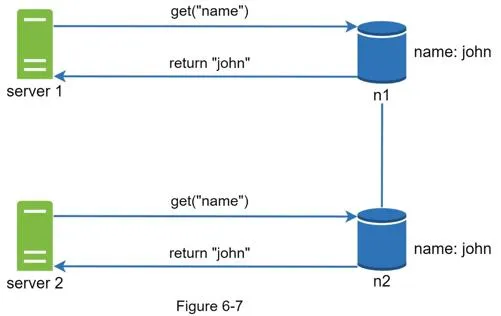
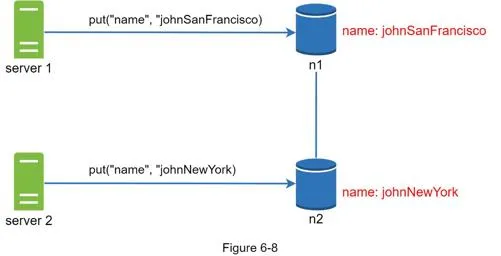
Conflict example: Two servers simultaneously change "name" → "johnSanFrancisco" and "johnNewYork" → conflicting versions v1 and v2.
Vector clocks
A [server, version] pair associated with a data item. Detects whether versions precede, succeed, or conflict.
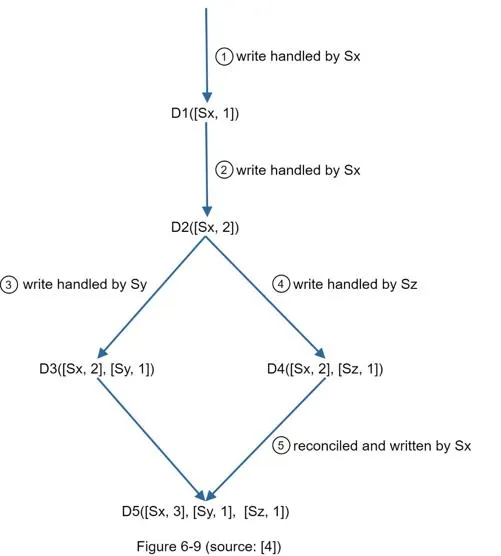
Operations:
- Write to server Si: increment vi if [Si, vi] exists, otherwise create [Si, 1]
- Version X is ancestor of Y (no conflict) if every participant's counter in Y ≥ corresponding in X
- Version X is sibling of Y (conflict) if any participant in Y has counter < corresponding in X
Example: D([s0,1],[s1,2]) and D([s0,2],[s1,1]) → conflict.
Downsides: Complexity added to client (must resolve conflicts). Vector clock size can grow — mitigate with threshold limit (remove oldest pairs). Dynamo paper reports not yet a problem in production.
Handling failures
Failure detection: Gossip protocol
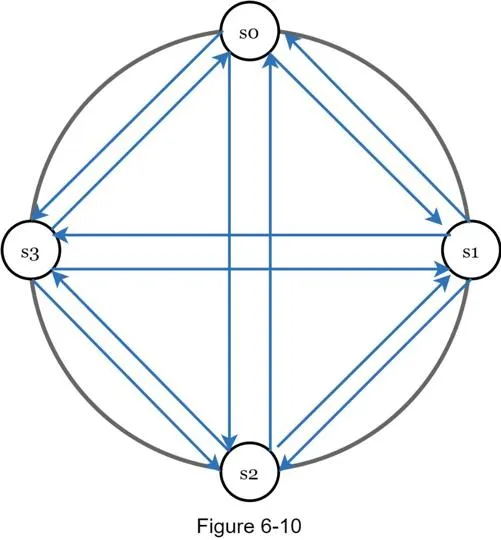
Better than all-to-all multicasting:
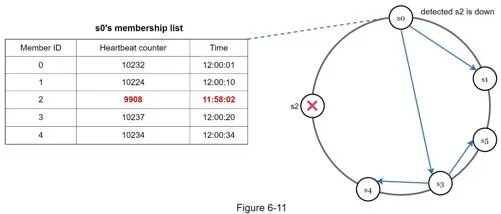
- Each node maintains membership list (member IDs + heartbeat counters)
- Each node periodically increments its heartbeat
- Each node sends heartbeats to random nodes, which propagate further
- Membership lists updated on heartbeat receipt
- If heartbeat hasn't increased for predefined period → member considered offline
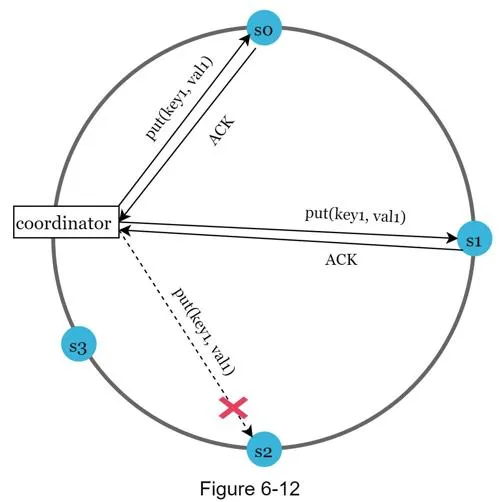
Handling temporary failures: Sloppy quorum + hinted handoff
Instead of strict quorum, choose first W healthy servers for writes, first R healthy servers for reads on hash ring. Offline servers ignored. When down server recovers, changes pushed back (hinted handoff).
Handling permanent failures: Merkle tree (anti-entropy)
Compare data across replicas, sync only differences.
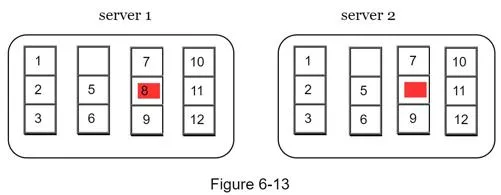
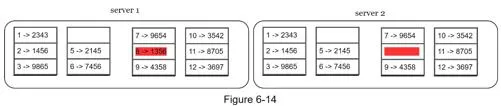
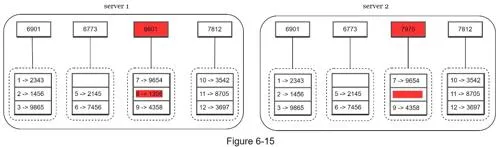
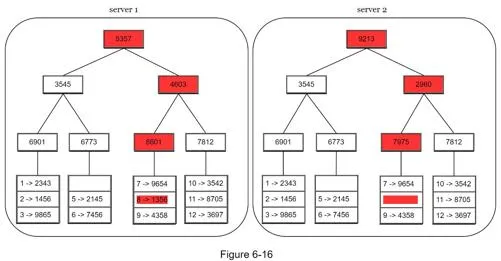
Merkle tree construction:
- Divide key space into buckets (e.g., 4 buckets for keys 1–12)
- Hash each key in bucket using uniform hashing
- Create single hash per bucket
- Build tree upward to root by hashing children
Comparison: Start at root → if hashes match, servers have same data. If not, traverse children to find unsynchronized buckets → sync only those.
Synchronization amount proportional to differences, not total data. Typical config: 1M buckets per 1B keys (1,000 keys/bucket).
Handling data center outage
Replicate data across multiple data centers. Even if one data center offline, users access data through other data centers.
System architecture diagram
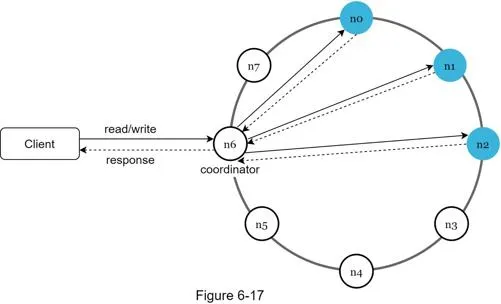
Features:
- Simple APIs:
get(key),put(key, value) - Coordinator acts as proxy between client and store
- Nodes distributed on ring via consistent hashing
- Completely decentralized (add/remove nodes automatically)
- Data replicated at multiple nodes
- No single point of failure (every node has same responsibilities)
Write path (based on Cassandra architecture)
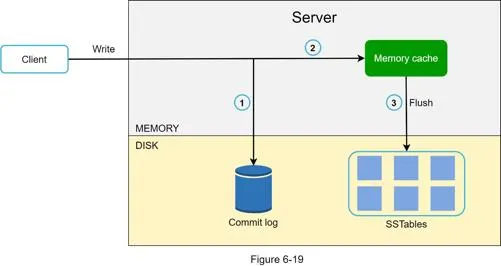
- Write request persisted to commit log file
- Data saved in memory cache
- When memory cache full/reaches threshold → flushed to SSTable on disk (sorted list of
<key, value>pairs)
Read path
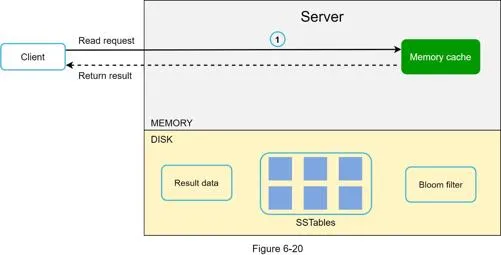
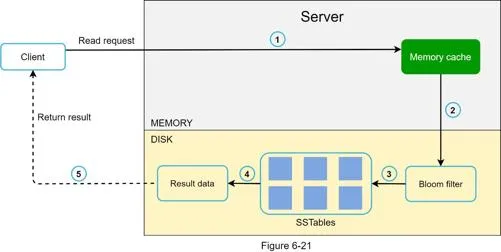
- Check memory cache → if hit, return data
- If miss, check Bloom filter to identify which SSTables might contain the key
- SSTables return result
- Return data to client
Summary
Reference materials
[1] Amazon DynamoDB: https://aws.amazon.com/dynamodb/ [2] memcached: https://memcached.org/ [3] Redis: https://redis.io/ [4] Dynamo: Amazon's Highly Available Key-value Store: https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf [5] Cassandra: https://cassandra.apache.org/ [6] Bigtable: A Distributed Storage System for Structured Data: https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf [7] Merkle tree: https://en.wikipedia.org/wiki/Merkle_tree [8] Cassandra architecture: https://cassandra.apache.org/doc/latest/architecture/ [9] SStable: https://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb/ [10] Bloom filter https://en.wikipedia.org/wiki/Bloom_filter