Design a Unique ID Generator in Distributed Systems
3 min readTraditional auto_increment doesn't work in distributed environments — a single DB server can't handle the scale, and generating unique IDs across multiple DBs with minimal delay is challenging.
Step 1 — Understand the problem and establish design scope
Requirements:
- IDs must be unique
- IDs must be sortable (increment by time, not necessarily by 1)
- IDs are numerical values only
- IDs fit into 64-bit
- IDs ordered by date (evening IDs > morning IDs from same day)
- Generate over 10,000 unique IDs per second
Step 2 — Propose high-level design and get buy-in
Multi-master replication
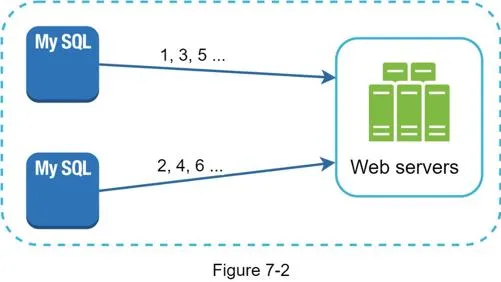
Uses database auto_increment but increments by k (number of DB servers) instead of 1. Server 1: 1, 3, 5, ...; Server 2: 2, 4, 6, ...
Pros: Some scalability. Cons: Hard to scale with multiple data centers. IDs don't increase with time across servers. Doesn't scale well when servers added/removed.
UUID
128-bit number, collision probability extremely low (1 billion UUIDs/sec for ~100 years → 50% chance of single duplicate). Example: 09c93e62-50b4-468d-bf8a-c07e1040bfb2
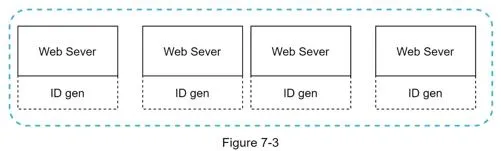
Each web server generates IDs independently — no coordination needed.
Pros: Simple, no synchronization issues, easy to scale. Cons: 128 bits (requirement is 64 bits). IDs don't go up with time. IDs could be non-numeric.
Ticket Server
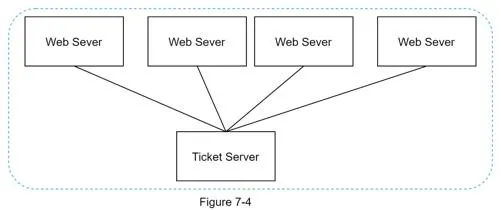
Centralized auto_increment in a single DB server (Flicker approach).
Pros: Numeric IDs, easy to implement, works for small/medium-scale. Cons: Single point of failure. Multiple ticket servers introduce data synchronization challenges.
Twitter snowflake approach
Divide a 64-bit ID into sections:

| Section | Bits | Details |
|---|---|---|
| Sign bit | 1 | Always 0 (reserved for future) |
| Timestamp | 41 | Milliseconds since custom epoch (Nov 04, 2010, 01:42:54 UTC) |
| Datacenter ID | 5 | 2^5 = 32 datacenters |
| Machine ID | 5 | 2^5 = 32 machines per datacenter |
| Sequence number | 12 | Incremented per ID on same machine, resets to 0 each millisecond |
Step 3 — Design deep dive


Timestamp: 41 bits → max timestamp = 2^41 − 1 = 2,199,023,255,551 ms ≈ 69 years from custom epoch. After 69 years, new epoch time or migration needed.
Sequence number: 12 bits = 2^12 = 4,096 combinations. Max 4,096 new IDs per millisecond per machine. Field is 0 unless >1 ID generated in same millisecond on same server.
Datacenter IDs and machine IDs: chosen at startup, fixed while running. Changes require careful review to avoid ID conflicts.
Step 4 — Wrap up
Approaches evaluated: Multi-master replication, UUID, ticket server, Twitter snowflake. Snowflake chosen — supports all requirements and is scalable in distributed environments.
Additional talking points:
- Clock synchronization: ID generators on multiple cores/machines may have different clocks. Network Time Protocol (NTP) is the most popular solution.
- Section length tuning: Fewer sequence bits + more timestamp bits for low-concurrency, long-term applications.
- High availability: ID generator is mission-critical — must be highly available.
Reference materials
[1] Universally unique identifier: https://en.wikipedia.org/wiki/Universally_unique_identifier [2] Ticket Servers: Distributed Unique Primary Keys on the Cheap: https://code.flickr.net/2010/02/08/ticket-servers-distributed-unique-primary-keys-on-the-cheap/ [3] Announcing Snowflake: https://blog.twitter.com/engineering/en_us/a/2010/announcing-snowflake.html [4] Network time protocol: https://en.wikipedia.org/wiki/Network_Time_Protocol