Design a URL Shortener
3 min readStep 1 - Understand the problem and establish design scope
Requirements:
- Given a long URL, return a much shorter URL; clicking the short URL redirects to the original
- 100 million URLs generated per day
- Short URL should use [0-9, a-z, A-Z] characters — 62 possible chars
- No deletion or update of shortened URLs
- High availability, scalability, fault tolerance
Back of the envelope estimation:
- Write QPS: 100M / 24 / 3600 = 1,160 writes/s
- Read QPS (10:1 ratio): 11,600 reads/s
- 10-year records: 100M × 365 × 10 = 365 billion URLs
- Storage (avg URL length 100 bytes): 365B × 100 bytes × 10 years = 365 TB
Step 2 - Propose high-level design and get buy-in
API Endpoints:
POST api/v1/data/shorten— body:{longUrl: longURLString}, returns shortURLGET api/v1/shortUrl— returns longURL for HTTP redirection
URL redirecting:
- 301 redirect: Permanent. Browser caches response; subsequent requests skip the shortener → reduces server load, but loses analytics
- 302 redirect: Temporary. All requests hit the shortener → enables click tracking and analytics
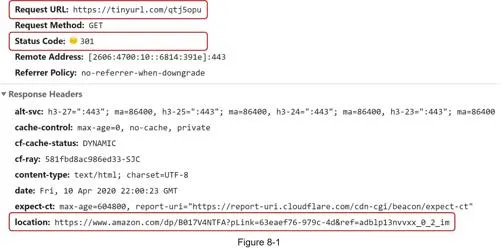
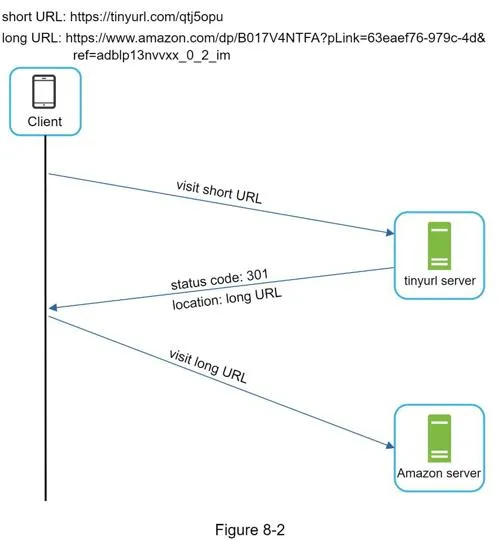
URL shortening flow:
www.tinyurl.com/{hashValue}— a hash function maps long URL → hashValue- Requirements: each longURL maps to one hashValue; hashValue must map back to longURL
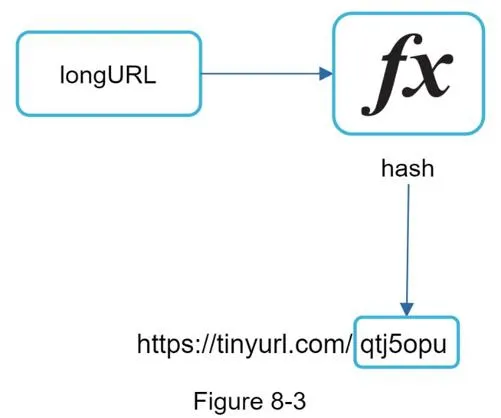
Step 3 - Design deep dive
Data model
Store <shortURL, longURL> mapping in a relational database (hash tables in memory aren't feasible at scale). Simplified schema: id, shortURL, longURL.
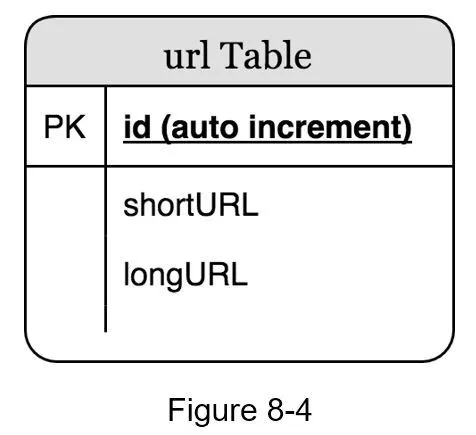
Hash function
Hash value length: 62^n ≥ 365B. At n=7, 62^7 = ~3.5 trillion → 7-character hash values.
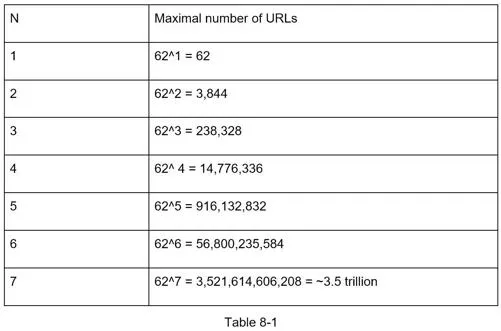
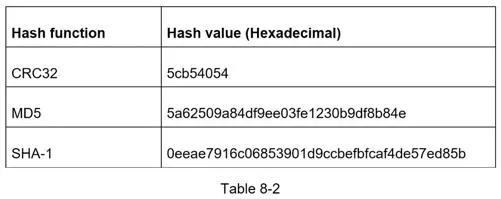
Option A: Hash + collision resolution
- Use CRC32, MD5, or SHA-1, then take first 7 characters
- On collision, recursively append a predefined string until unique
- Expensive: DB lookup on every request. Bloom filters can speed up collision checking
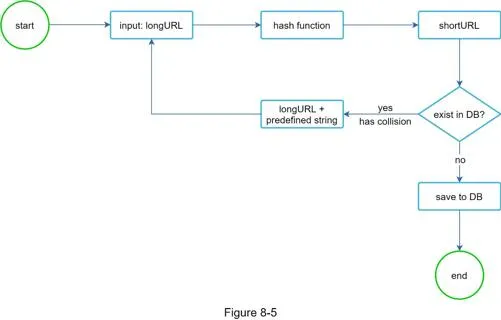
Option B: Base 62 conversion
- Convert a unique numeric ID to base 62 (0-9 → 0-9, 10-35 → a-z, 36-61 → A-Z)
- Example: 11157₁₀ = 2×62² + 55×62¹ + 59×62⁰ = [2, T, X] →
https://tinyurl.com/2TX

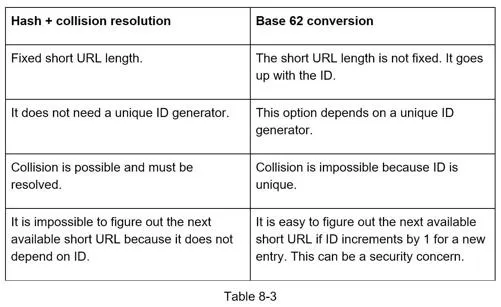
Comparison:
URL shortening deep dive (Base 62 approach)
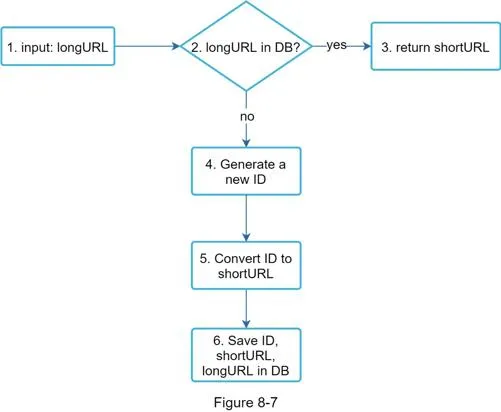
- longURL input → check if already in DB → return existing shortURL if found
- If new: generate unique ID (from distributed ID generator, see Ch.7) → convert to base 62 → store (id, shortURL, longURL) in DB
- Example: ID 2009215674938 → base 62 → "zn9edcu"

URL redirecting deep dive

- User clicks
https://tinyurl.com/zn9edcu - Load balancer → web servers → check cache for shortURL
- Cache hit: return longURL. Cache miss: fetch from DB → cache it → return
- Invalid shortURL if not in DB
<shortURL, longURL> mapping is cached since reads >> writes.
Step 4 - Wrap up
Additional talking points:
- Rate limiter (Ch.4): Protect against malicious bulk URL creation
- Web server scaling: Stateless tier, easy horizontal scaling
- Database scaling: Replication and sharding
- Analytics: Track click rates, sources, timing
- Availability, consistency, reliability (Ch.1)
Reference materials
[1] A RESTful Tutorial: https://www.restapitutorial.com/index.html [2] Bloom filter: https://en.wikipedia.org/wiki/Bloom_filter