Design a Search Autocomplete System
4 min readAlso called "design top k" or "design top k most searched queries."
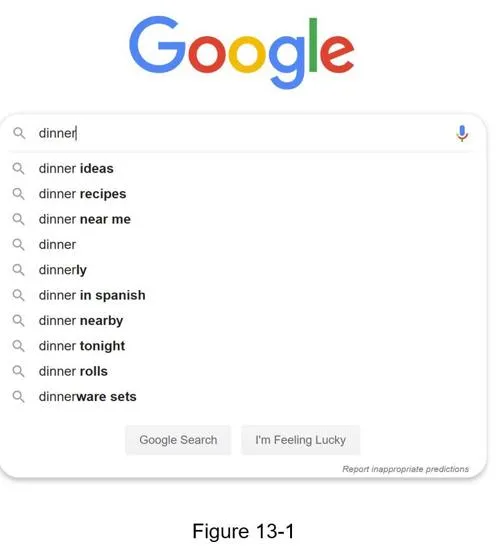
Step 1 - Understand the problem and establish design scope
Requirements:
- Matching only at the beginning of a search query (not middle)
- Return 5 autocomplete suggestions
- Ranked by historical query frequency (popularity)
- No spell check/autocorrect
- English only, lowercase alphabetic characters
- 10 million DAU
Non-functional requirements:
- Fast response: < 100ms (otherwise UI stutters — per Facebook engineering)
- Relevant, sorted, scalable, highly available
Back of the envelope estimation:
- 10M DAU × 10 searches/day = 100M queries/day
- 20 bytes/query (4 words × 5 chars, ASCII)
- 20 requests per search (one per character typed)
- QPS: 10M × 10 × 20 / 86400 = ~24,000 QPS
- Peak QPS: ~48,000
- New data/day: 10M × 10 × 20B × 20% (new queries) = 0.4 GB
Step 2 - Propose high-level design and get buy-in
Two parts: Data gathering service (aggregate queries) + Query service (return top 5).
Data gathering service
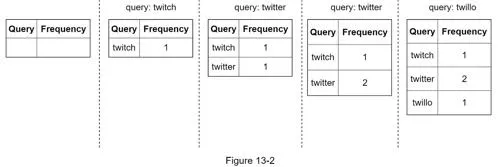
Frequency table: (query, frequency). Updated in real-time as users search.
Query service
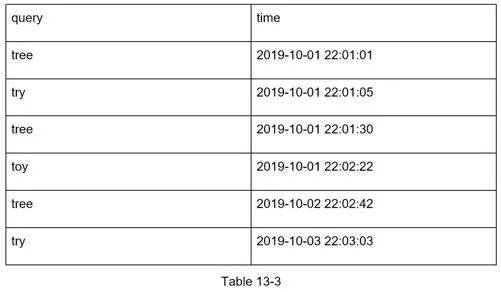
When user types "tw", SQL: SELECT * FROM frequency_table WHERE query LIKE 'prefix%' ORDER BY frequency DESC LIMIT 5


Works for small data, but DB becomes bottleneck at scale.
Step 3 - Design deep dive
Trie data structure
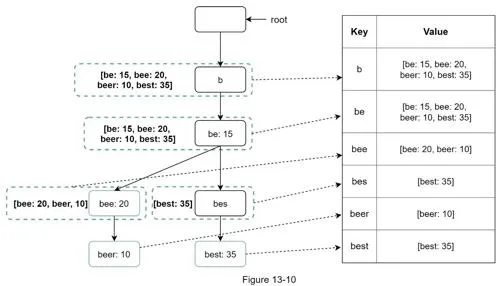
Core data structure: trie (prefix tree).
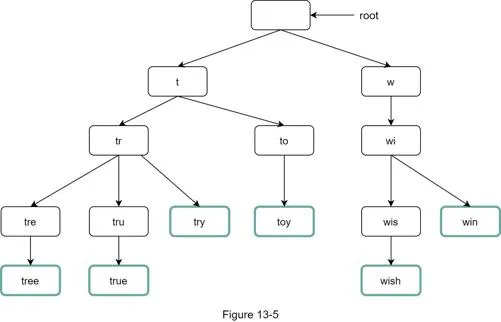
- Root = empty string
- Each node: 26 children (a-z); stores a character
- Frequency info added to nodes to support sorting
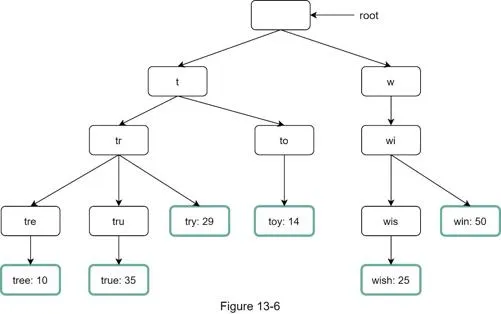
Basic trie algorithm (O(p) + O(c) + O(c log c)):
- Find prefix node: O(p)
- Traverse subtree to get all valid children: O(c)
- Sort children by frequency, get top k: O(c log c)
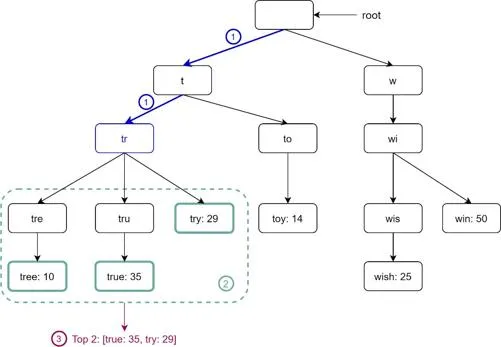
Two optimizations:
- Limit max prefix length: Users rarely type > 50 chars → O(p) → O(1)
- Cache top k queries at each node: Store top 5 at every node. Trades space for time.
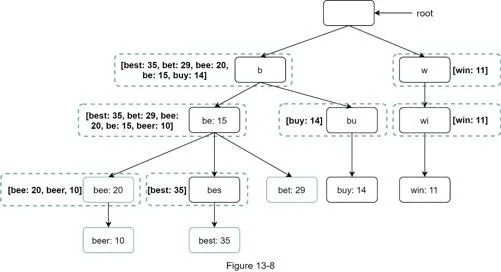
Optimized time complexity: O(1) for finding prefix + returning top k.
Data gathering service (redesigned)
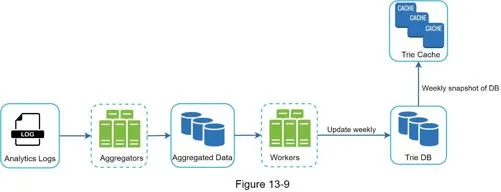
Real-time updates impractical: billions of queries/day would slow query service; top suggestions don't change frequently.
Components:
- Analytics Logs: Append-only raw query data
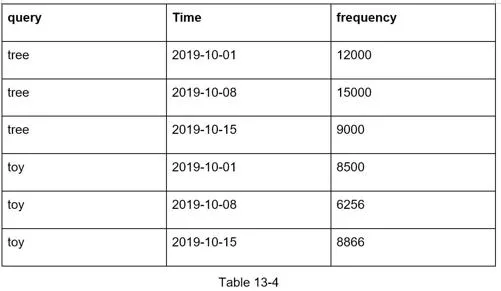
- Aggregators: Aggregate data for processing. For real-time (Twitter): short intervals. For many cases: weekly is sufficient.
- Workers: Async jobs at regular intervals; build trie, store in Trie DB
- Trie Cache: Distributed in-memory cache; weekly snapshot of DB
- Trie DB: Persistent storage options:
- Document store (MongoDB): Serialized trie snapshot
- Key-value store: Map each prefix to a hash table key, node data to value
Query service (improved)
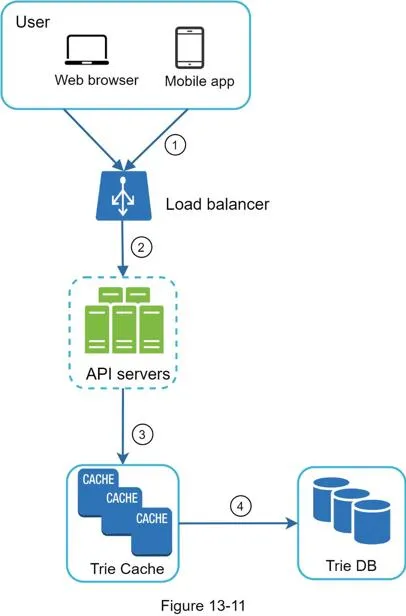
- Query → Load balancer → API servers
- API servers get trie data from Trie Cache → construct suggestions
- Cache miss → replenish from Trie DB
Optimizations:
- AJAX: No full page refresh on autocomplete
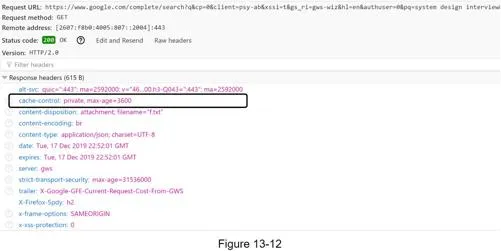
- Browser caching: Cache results; Google caches for 1 hour (
max-age=3600,private)
- Data sampling: Log only 1 out of every N requests
Trie operations
Create: Workers build from aggregated data.
Update:
- Option 1: Rebuild weekly; replace old trie
- Option 2: Update individual node directly (slow; cascade-update ancestors since they cache children's top queries)
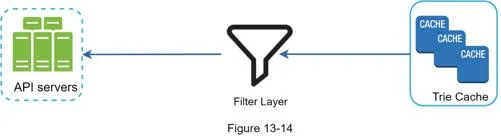
Delete: Filter layer in front of Trie Cache removes unwanted suggestions (hateful, violent, explicit). Async physical removal from DB for next build cycle.
Scale the storage
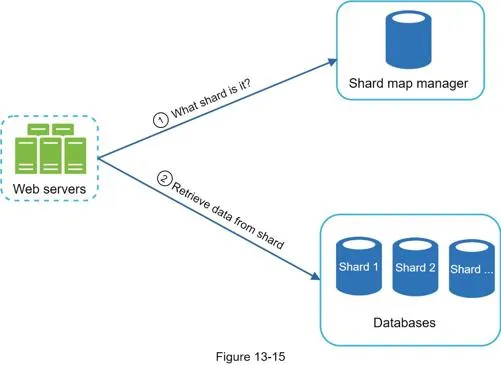
Sharding by first character (a–m, n–z) → up to 26 shards. Beyond 26: shard on second/third character. Problem: uneven distribution ('c' has more words than 'x').
Solution: Analyze historical data distribution. Shard map manager maintains lookup DB. Example: 's' alone on one shard; 'u' through 'z' combined on another.
Step 4 - Wrap up
Follow-up Q&A:
Multi-language support: Store Unicode characters in trie nodes.
Country-specific top queries: Build different tries per country; store in CDNs.
Trending (real-time) search queries: Original weekly rebuild doesn't work. Ideas:
- Reduce working set by sharding
- Assign more weight to recent queries in ranking model
- Use stream processing: Hadoop MapReduce, Spark Streaming, Storm, Kafka
Reference materials [1] The Life of a Typeahead Query (Facebook) [2] How We Built Prefixy [3] Prefix Hash Tree (Berkeley) [4] MongoDB wikipedia [5] Unicode FAQ [6] Apache Hadoop [7] Spark Streaming [8] Apache Storm [9] Apache Kafka