Distributed Message Queue
7 min readDesign a distributed message queue with event-streaming features: long data retention (2 weeks), repeated consumption, message ordering.
Benefits of message queues: Decoupling, improved scalability (scale producers/consumers independently), increased availability, better performance (async communication).
Note: Traditional message queues (RabbitMQ, ActiveMQ) differ from event streaming platforms (Kafka, Pulsar), but features are converging (RabbitMQ added streams; Pulsar works as both). This design targets the richer feature set.
Step 1 - Understand the Problem and Establish Design Scope
Functional requirements
- Producers send messages; consumers consume them.
- Messages can be consumed repeatedly or only once.
- Historical data truncated (retention: 2 weeks).
- Message size: KB range, text only.
- Messages consumed in production order.
- Delivery semantics: at-least-once, at-most-once, exactly-once (configurable).
- High throughput for log aggregation; low latency for traditional queue use cases.
Non-functional requirements
- Configurable throughput vs latency.
- Scalable and distributed; handles traffic surges.
- Persistent and durable: data persisted on disk, replicated across nodes.
Traditional message queue adjustments
Traditional queues: no strong retention, no ordering guarantees, smaller on-disk overflow. These simplifications reduce design complexity (noted where applicable).
Step 2 - Propose High-Level Design and Get Buy-In

Figure 2 Key components
Messaging models
Point-to-point: One message → one consumer. Traditional model. Message removed after ack.
Publish-subscribe: One message → all subscribers of a topic.
This design supports both. Pub/sub via topics; point-to-point via consumer groups (single consumer in group per partition).
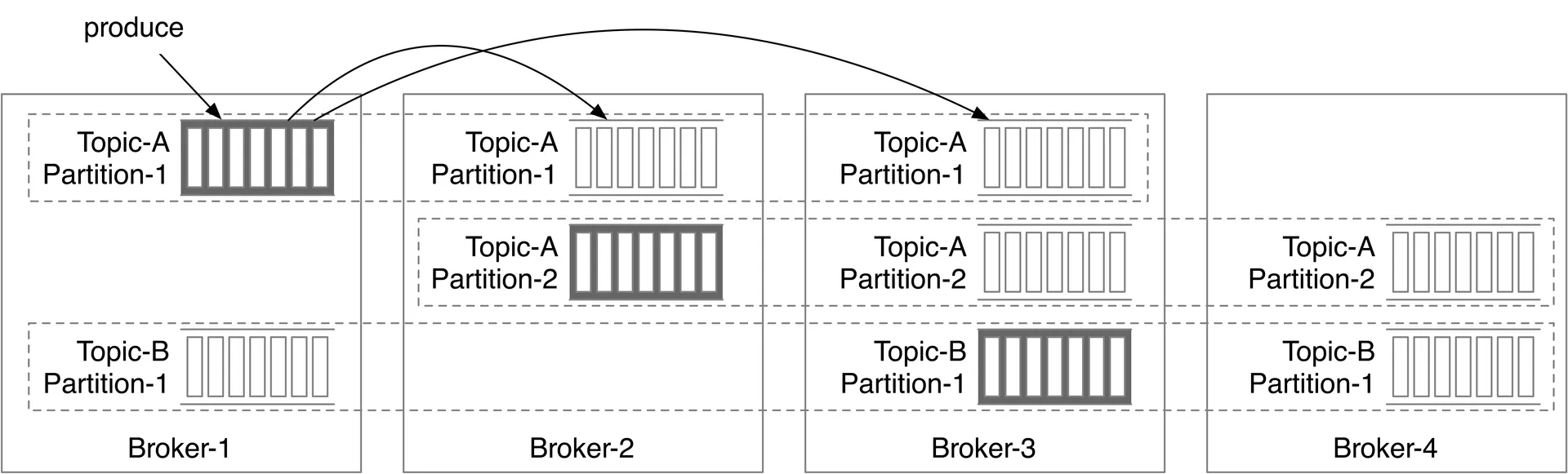
Topics, partitions, and brokers
- Topic: Logical category. Partition: Shard of a topic. Messages distributed across partitions.
- Partition = FIFO queue. Position = offset.
- Message key → hash(key) % numPartitions determines partition. No key → random.
- Broker: Server holding partitions. Partitions distributed across brokers for scalability.
- Consumer: Subscribes to topic, pulls from one or more partitions.


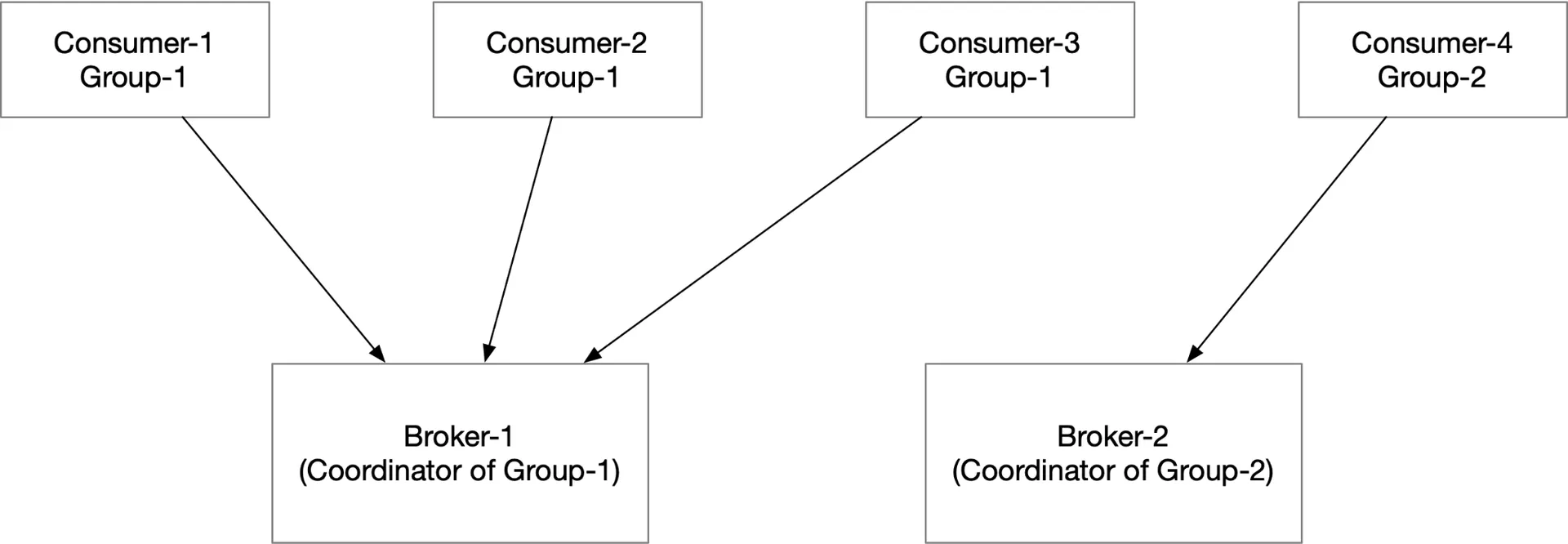
Consumer group
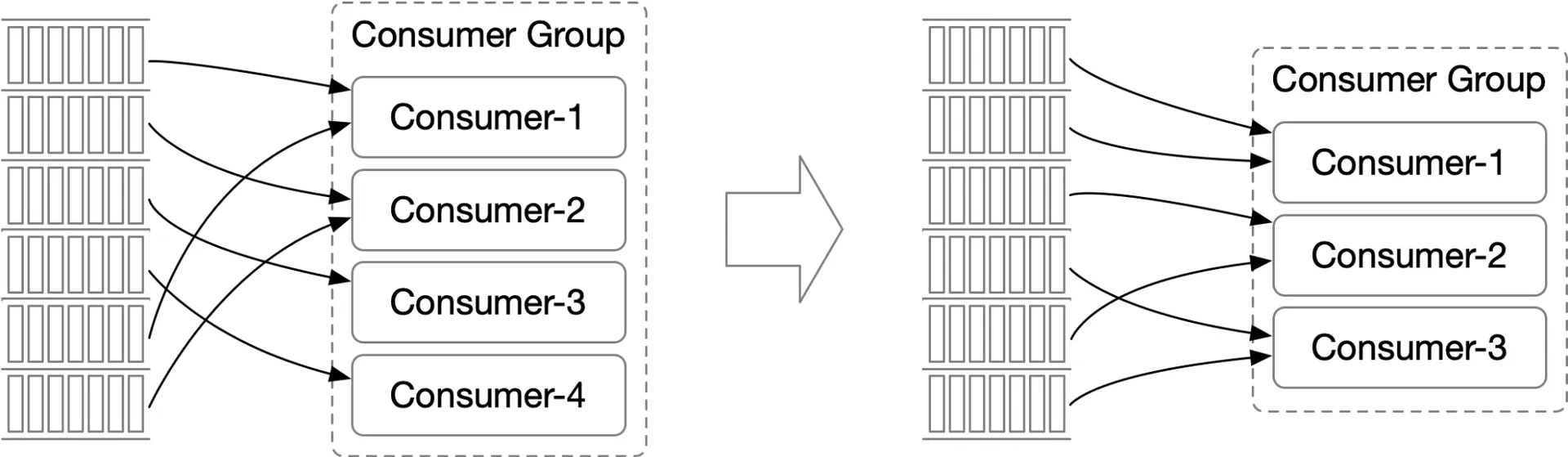
Set of consumers working together. Each group maintains its own consuming offsets. One partition → one consumer per group (constraint for ordering). More partitions than consumers → scale by adding consumers.
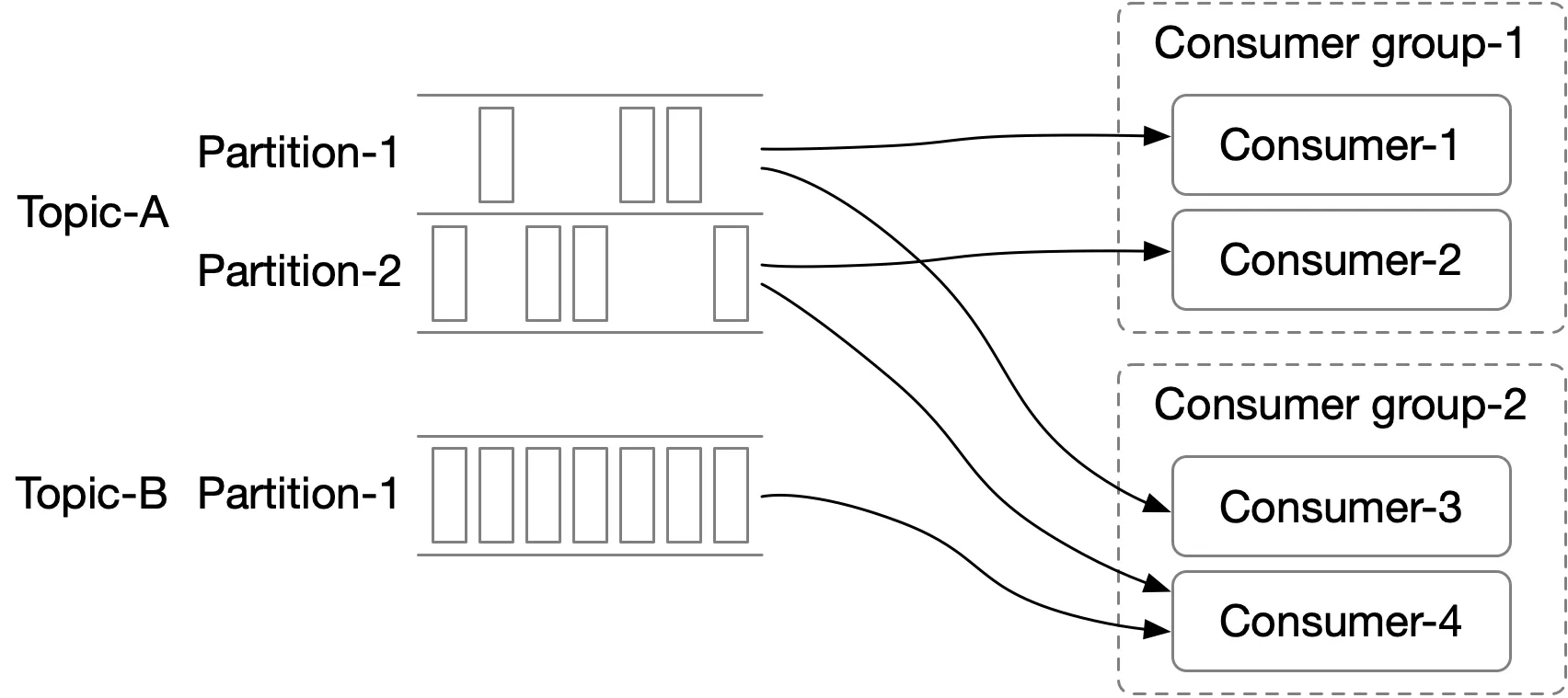
If all consumers in one group → point-to-point model (each partition consumed by exactly one consumer).
High-level architecture
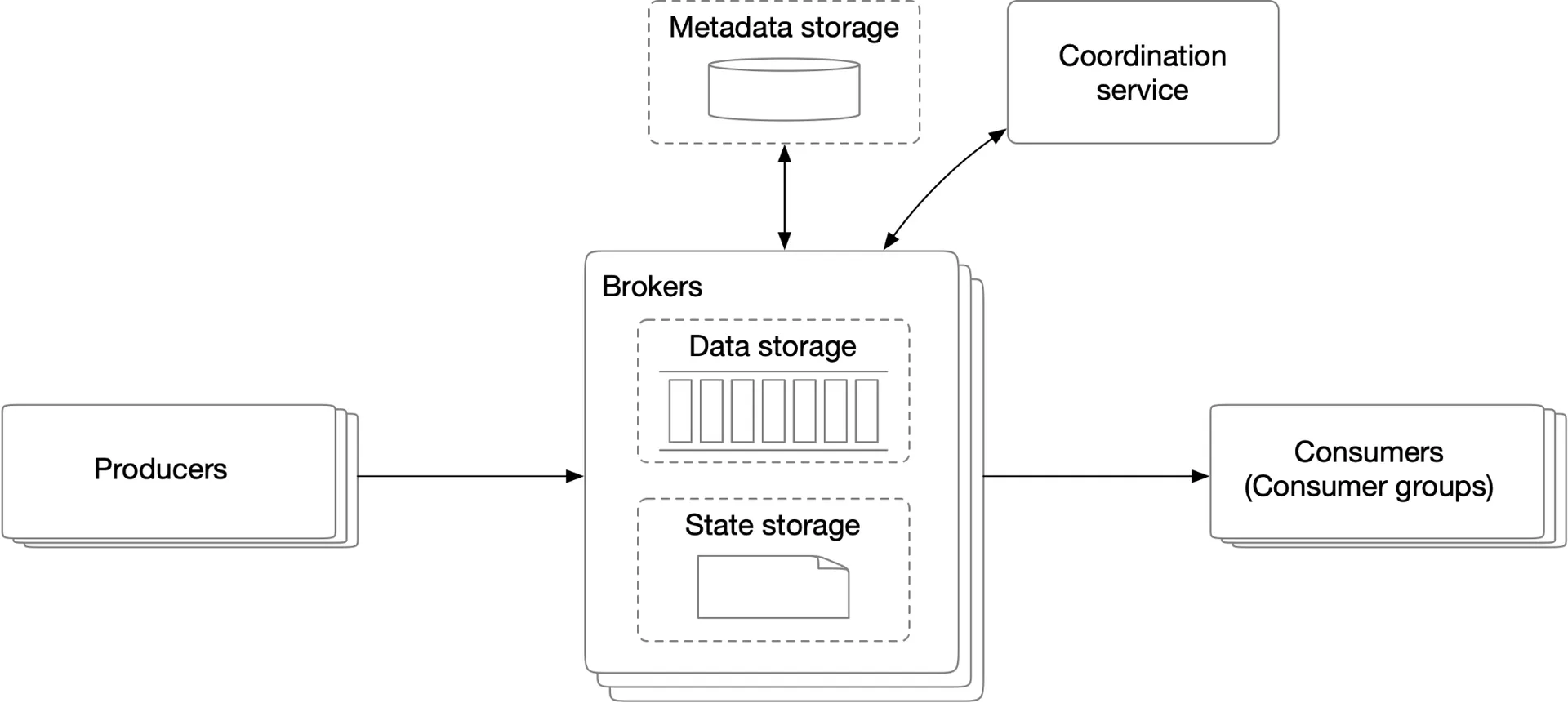
Figure 8 High-level design
- Clients: Producers push to topics; consumer groups subscribe.
- Broker: Holds partitions.
- Storage: Data storage (messages in partitions), state storage (consumer offsets), metadata storage (topic config, partitions, retention, replica distribution).
- Coordination service: Service discovery (alive brokers), leader election (active controller assigns partitions). Uses Zookeeper or etcd.
Step 3 - Design Deep Dive
Three key design choices for high throughput + data retention:
- On-disk data structure optimized for sequential access (rotational disk).
- Message data structure allows zero-copy from producer → queue → consumer.
- Batching everywhere: producers, queue, consumers.
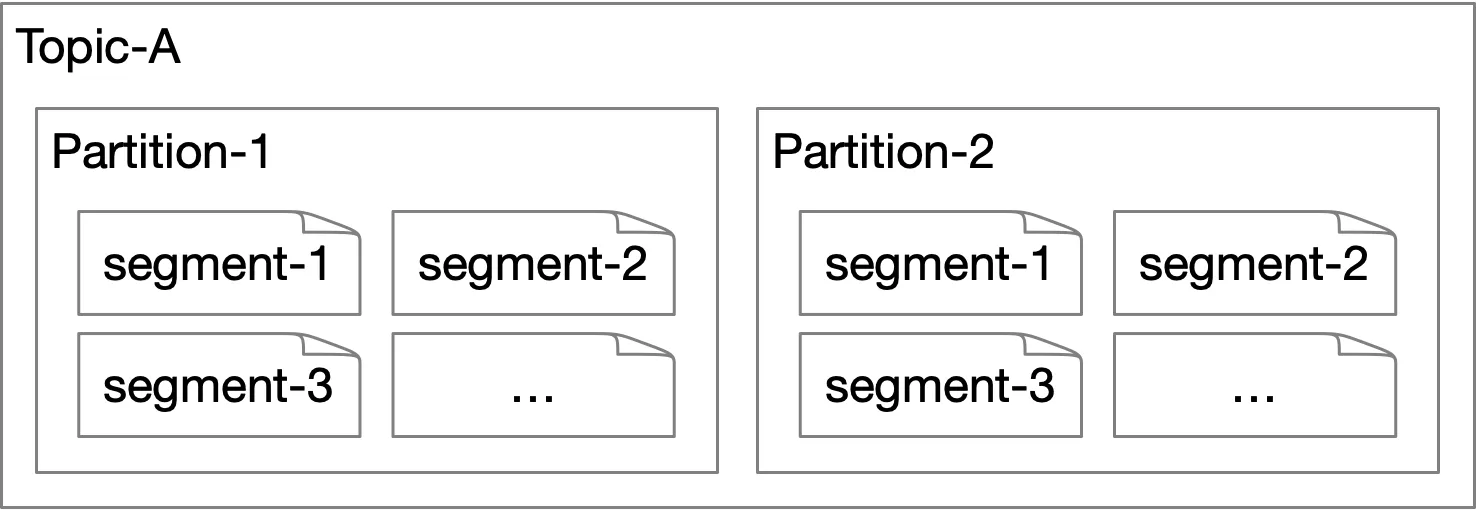
Data storage
Traffic pattern: write-heavy, read-heavy. No updates/deletes. Predominantly sequential access.
Option 1: Database — Not ideal. Hard to design for both write-heavy + read-heavy at scale.
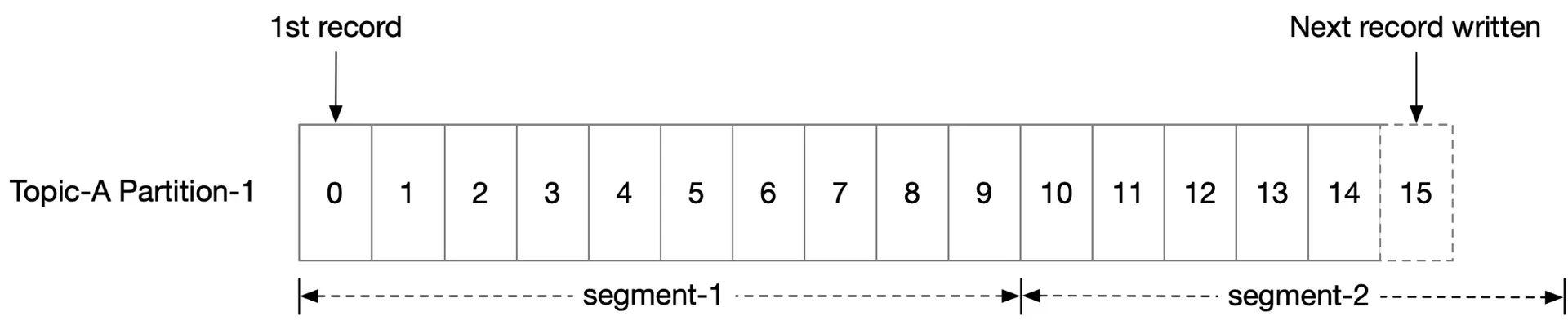
Option 2: Write-ahead log (WAL) — Recommended. Append-only log file. Sequential read/write. Rotational disks in RAID → several hundred MB/sec. OS aggressively caches disk data in main memory.
Segments: Active segment (appends) → when full → becomes inactive (read-only). Old segments truncated after retention period.
Message data structure
| Field | Type |
|---|---|
| key | byte[] |
| value | byte[] |
| topic | string |
| partition | integer |
| offset | long |
| timestamp | long |
| size | integer |
| crc | integer |
- Key: Determines partition via hash(key) % numPartitions. Not unique. Not equivalent to partition number.
- Value: Payload (plain text or compressed binary).
- CRC: Integrity check.
No data copying through the pipeline — producers, queue, and consumers agree on format.
Batching
Critical for performance:
- OS groups messages in single network request (amortizes round trips).
- Brokers write in large chunks → larger sequential writes, larger contiguous disk cache.
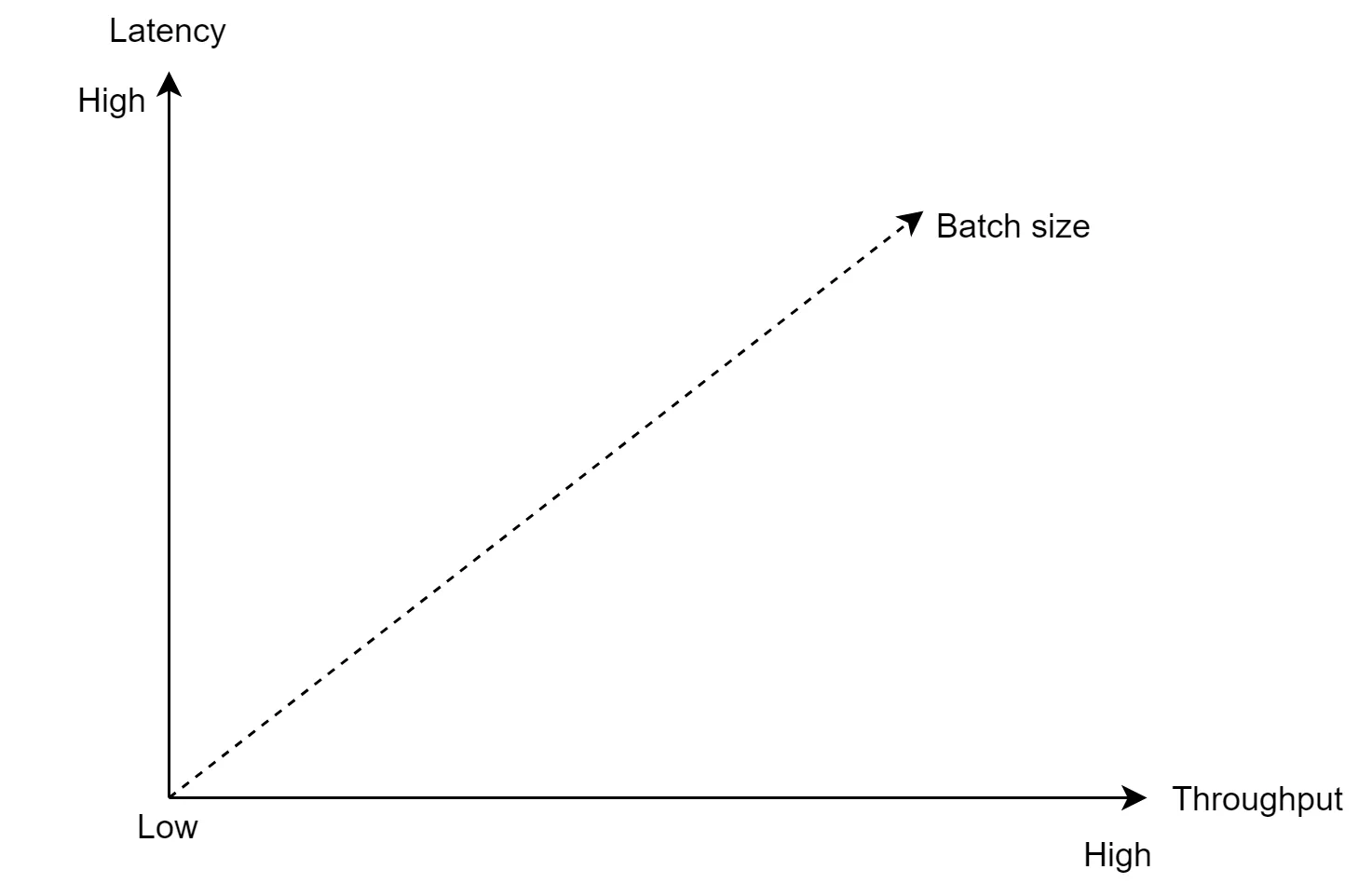
Tradeoff: large batch → higher throughput, higher latency. Configurable per use case.
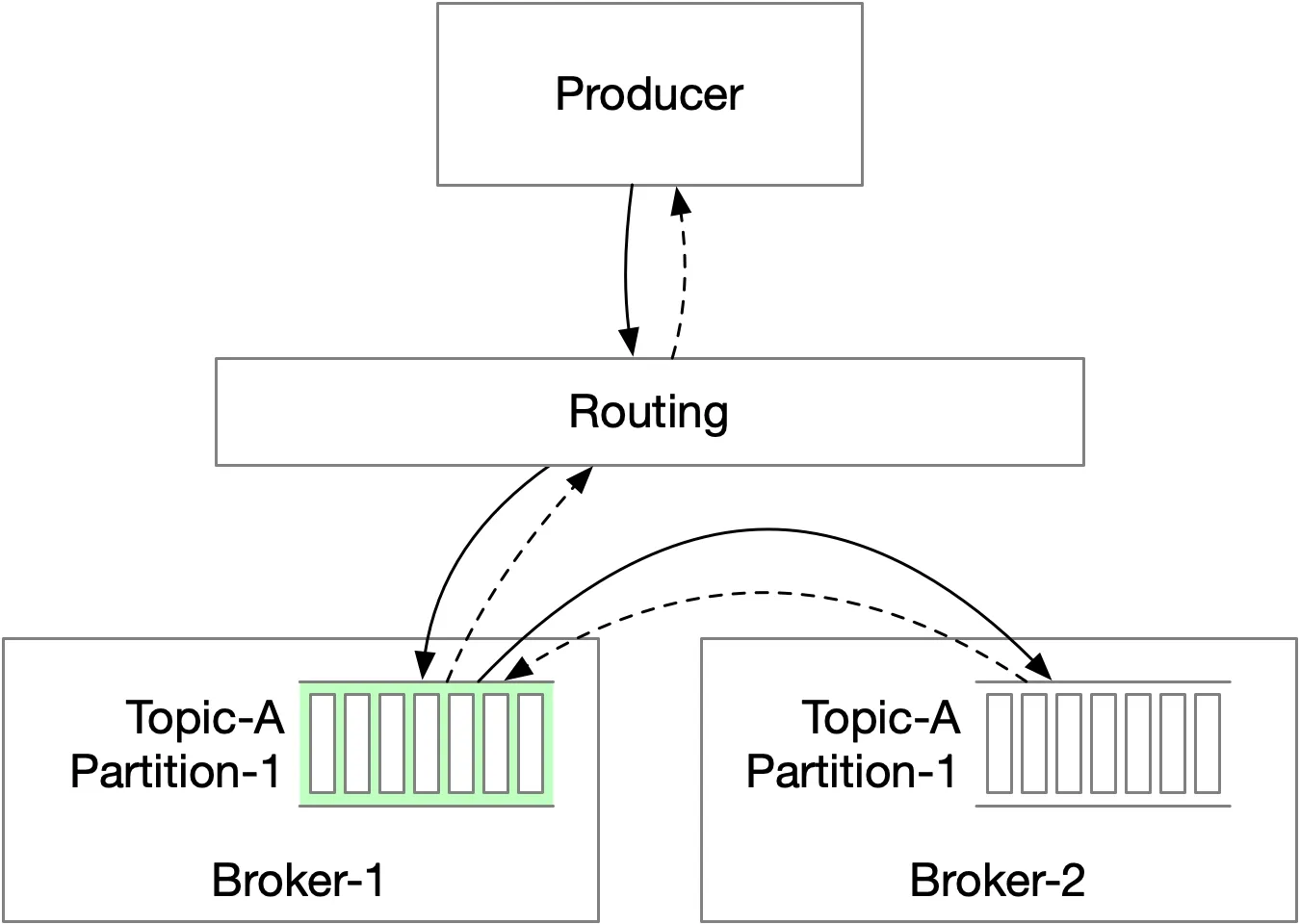
Producer flow
Option 1 (routing layer): Extra network hop, no batching → rejected.
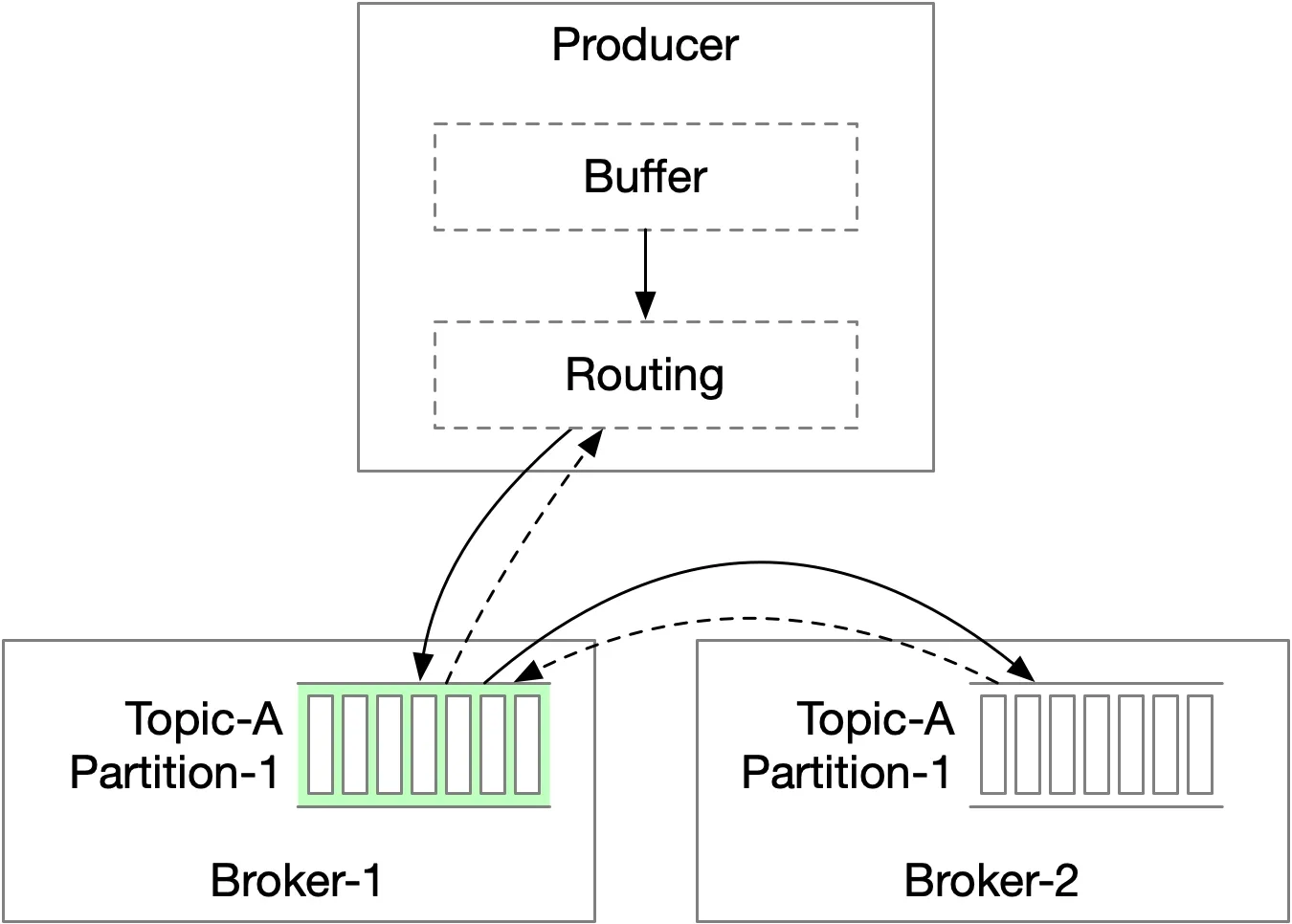
Option 2 (routing in producer client library): Improved. Buffer + routing in producer. Benefits: fewer hops, producer controls partition logic, batching in memory → large batches → higher throughput.
Batch size tradeoff: large = high throughput + high latency; small = low latency + low throughput.
Consumer flow (pull model)
Push vs Pull:
| Model | Pros | Cons |
|---|---|---|
| Push | Low latency (immediate) | Consumers can be overwhelmed; hard with diverse processing power |
| Pull | Consumers control rate; better for batching; can catch up later | Wastes resources when idle (mitigated by long polling) |
Pull model chosen. Long polling: wait specified time for new messages when queue is empty.
Consumer flow:
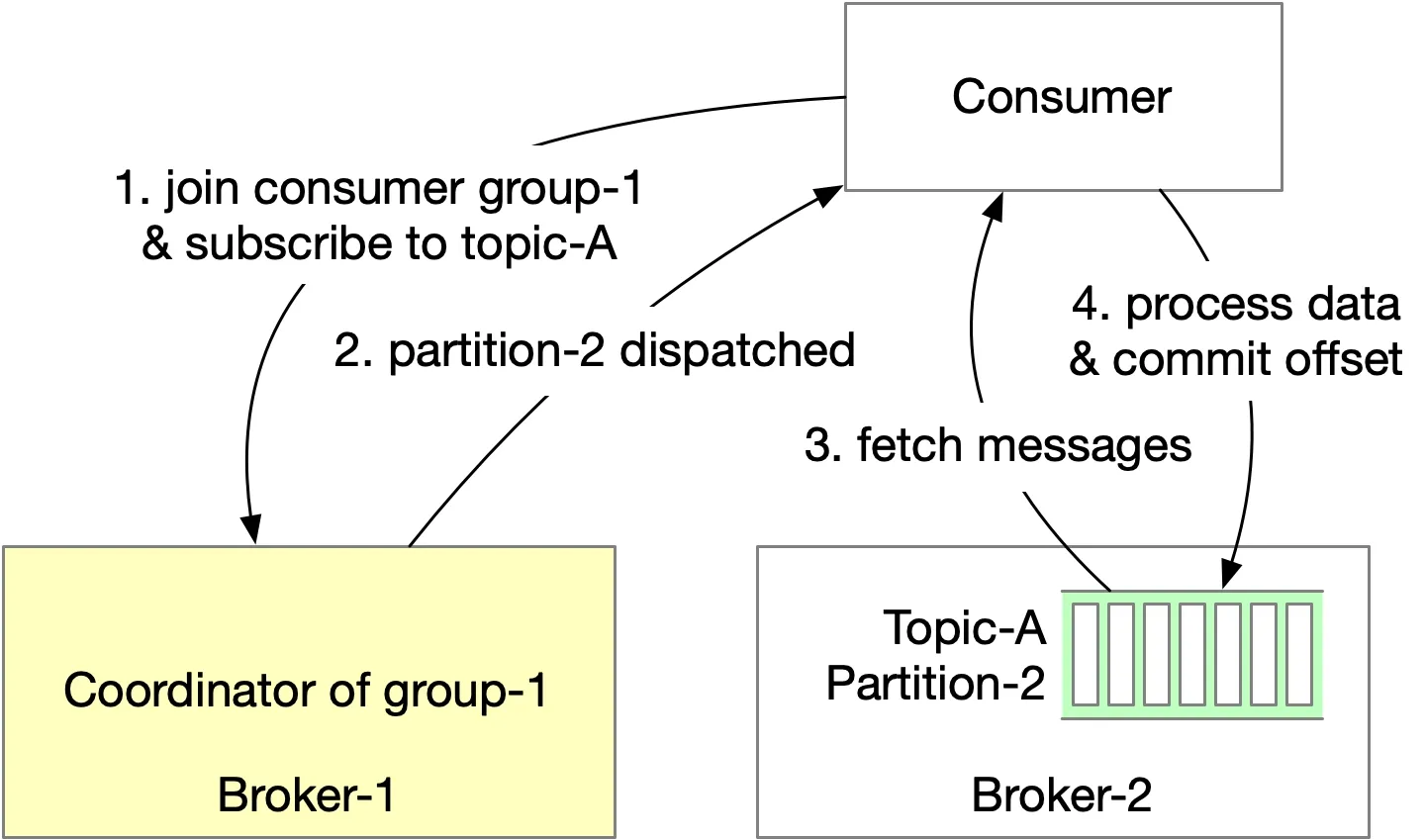
- New consumer joins group, finds coordinator by hashing group name.
- Coordinator assigns partitions (round-robin, range, etc.).
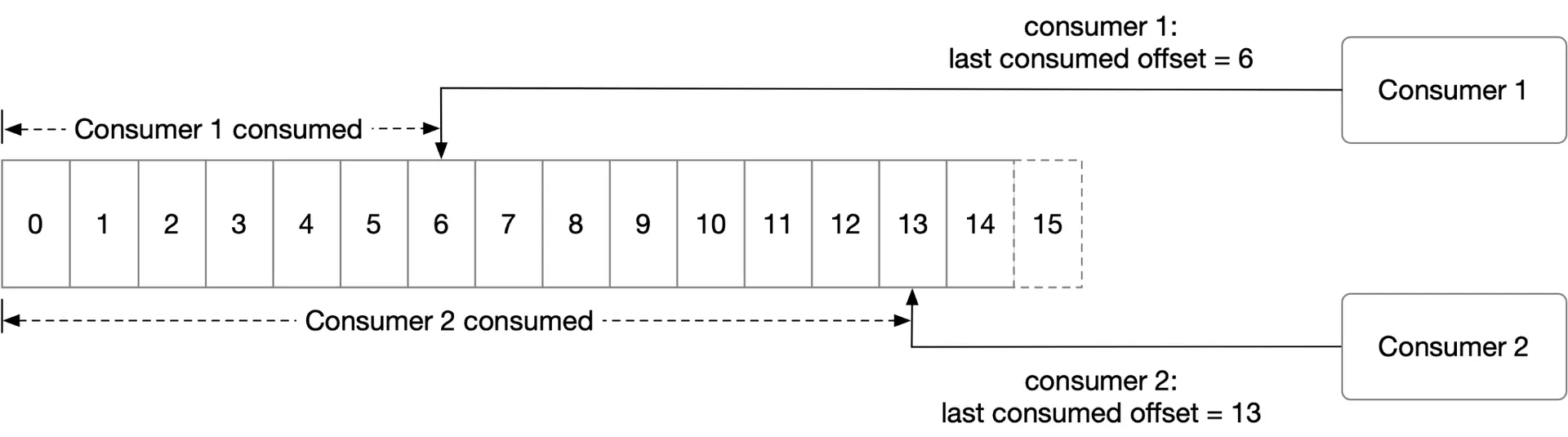
- Consumer fetches from last committed offset (state storage).
- Consumer processes, commits offset. Commit timing affects delivery semantics.
Consumer rebalancing: Triggered by consumer join/leave/crash or partition change. Coordinator manages heartbeat, elects group leader, leader generates partition dispatch plan → coordinator broadcasts.
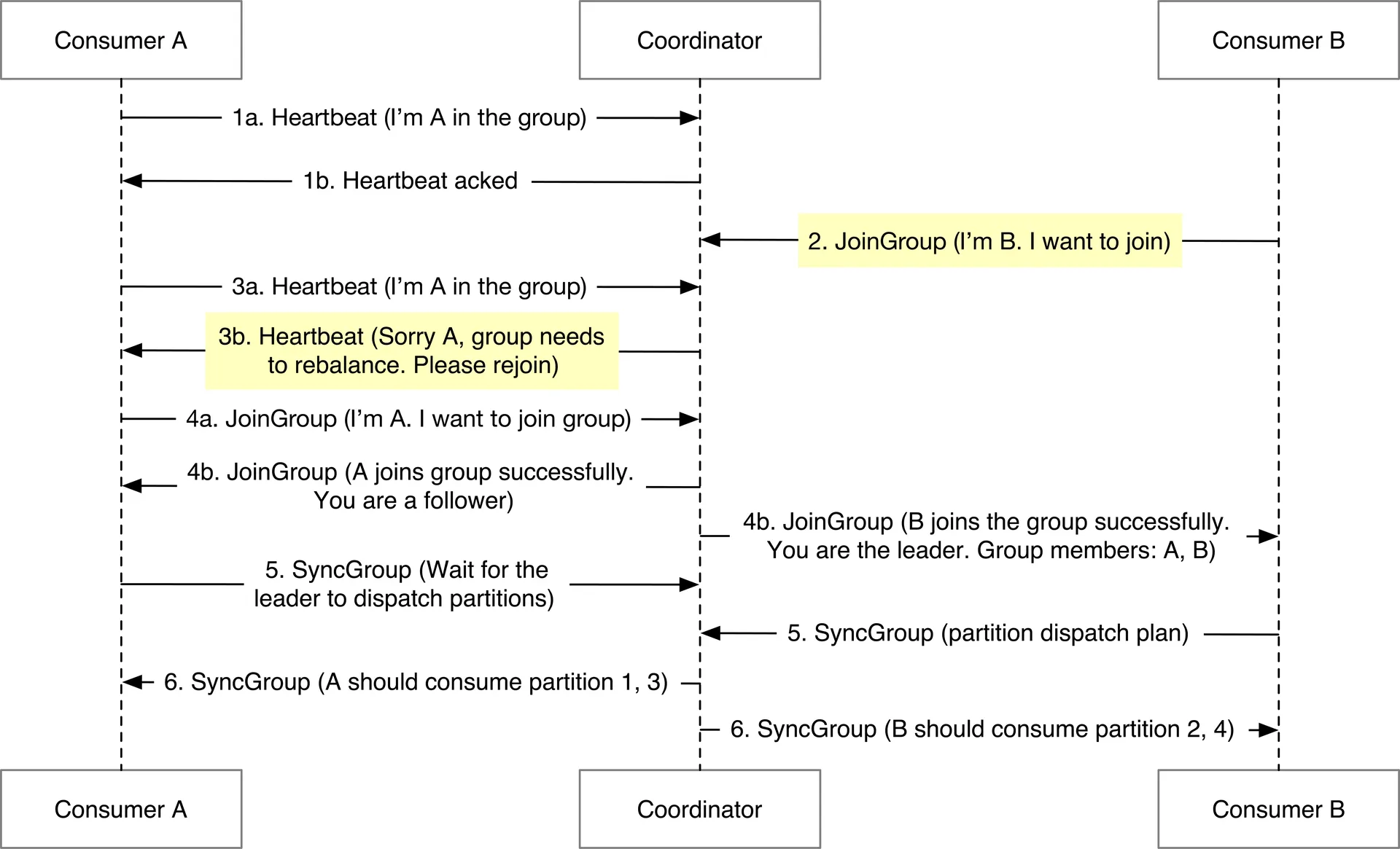
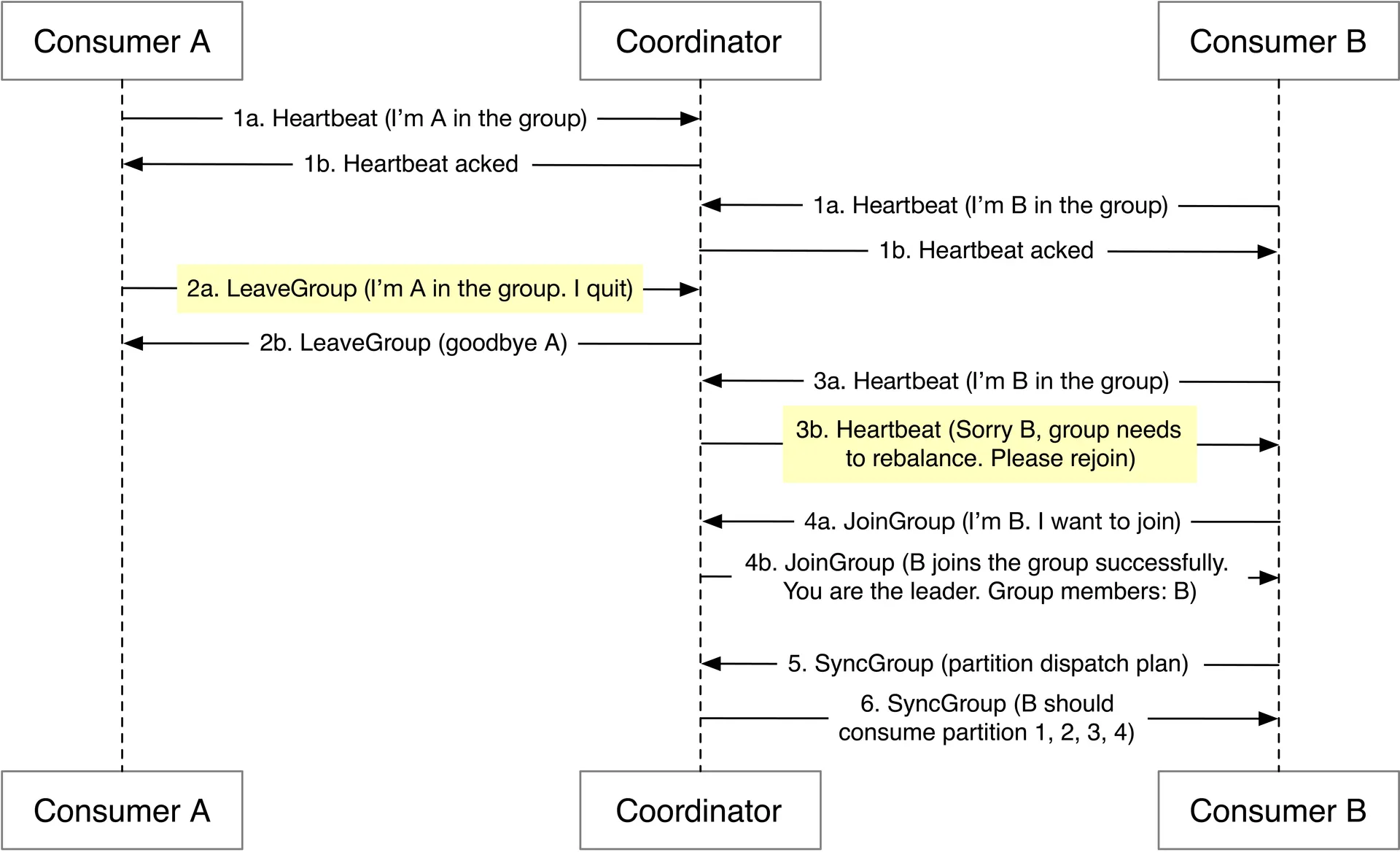
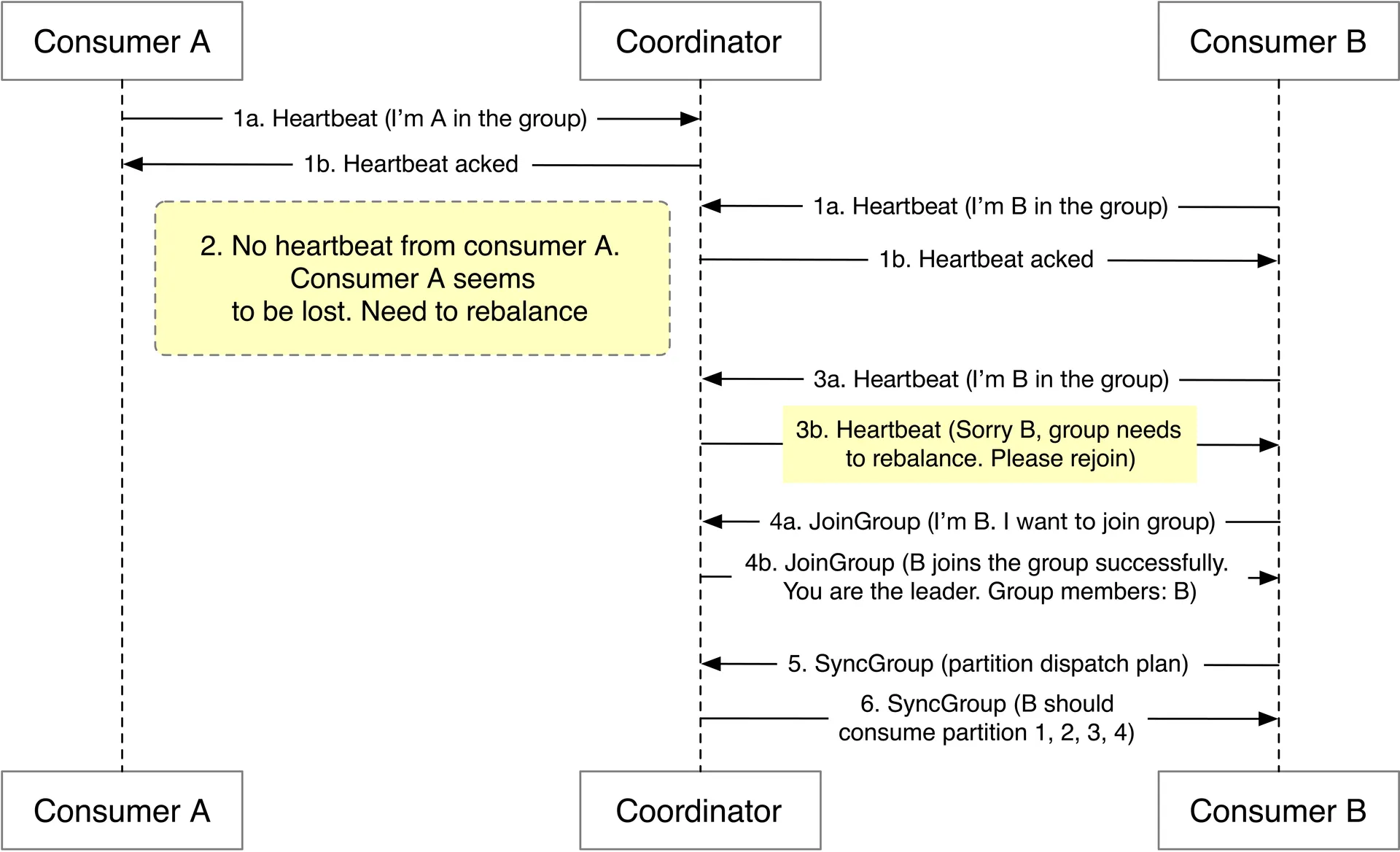
State storage
Stores: partition↔consumer mapping, last consumed offset per consumer group per partition.
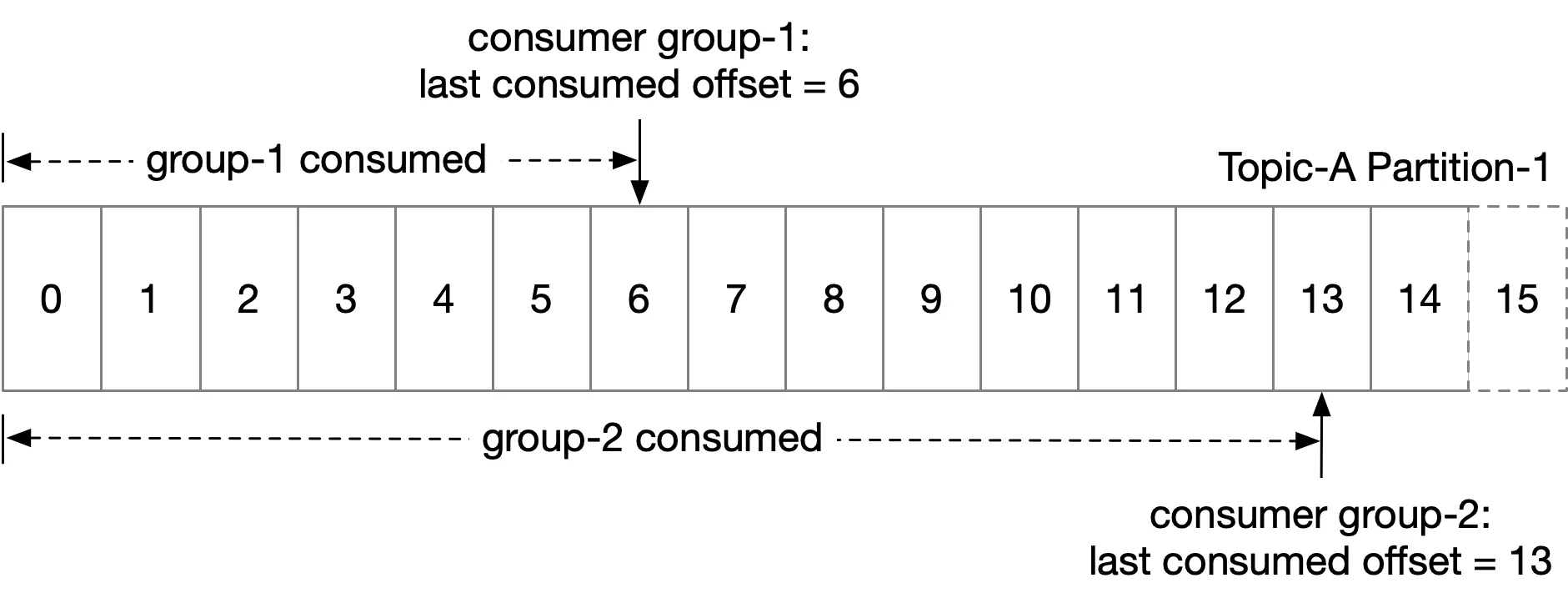
Access pattern: frequent read/write (low volume), rarely deleted, random access, consistency important. → Zookeeper (KV store) is a good fit. (Kafka later moved offset storage to brokers.)
Metadata storage
Topic config: number of partitions, retention period, replica distribution. Low volume, high consistency. → Zookeeper.
Zookeeper consolidation
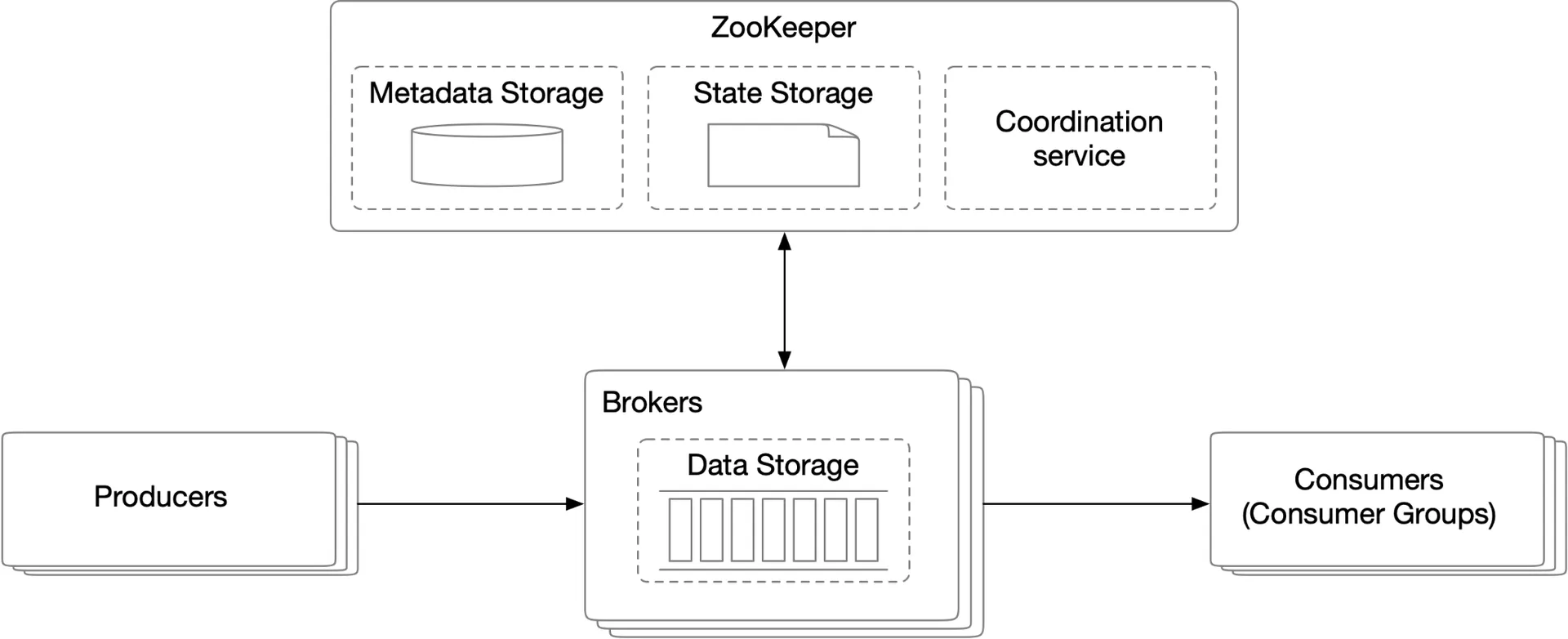
Zookeeper handles: metadata storage, state storage (consumer offsets), broker leader election. Broker now only maintains message data storage.
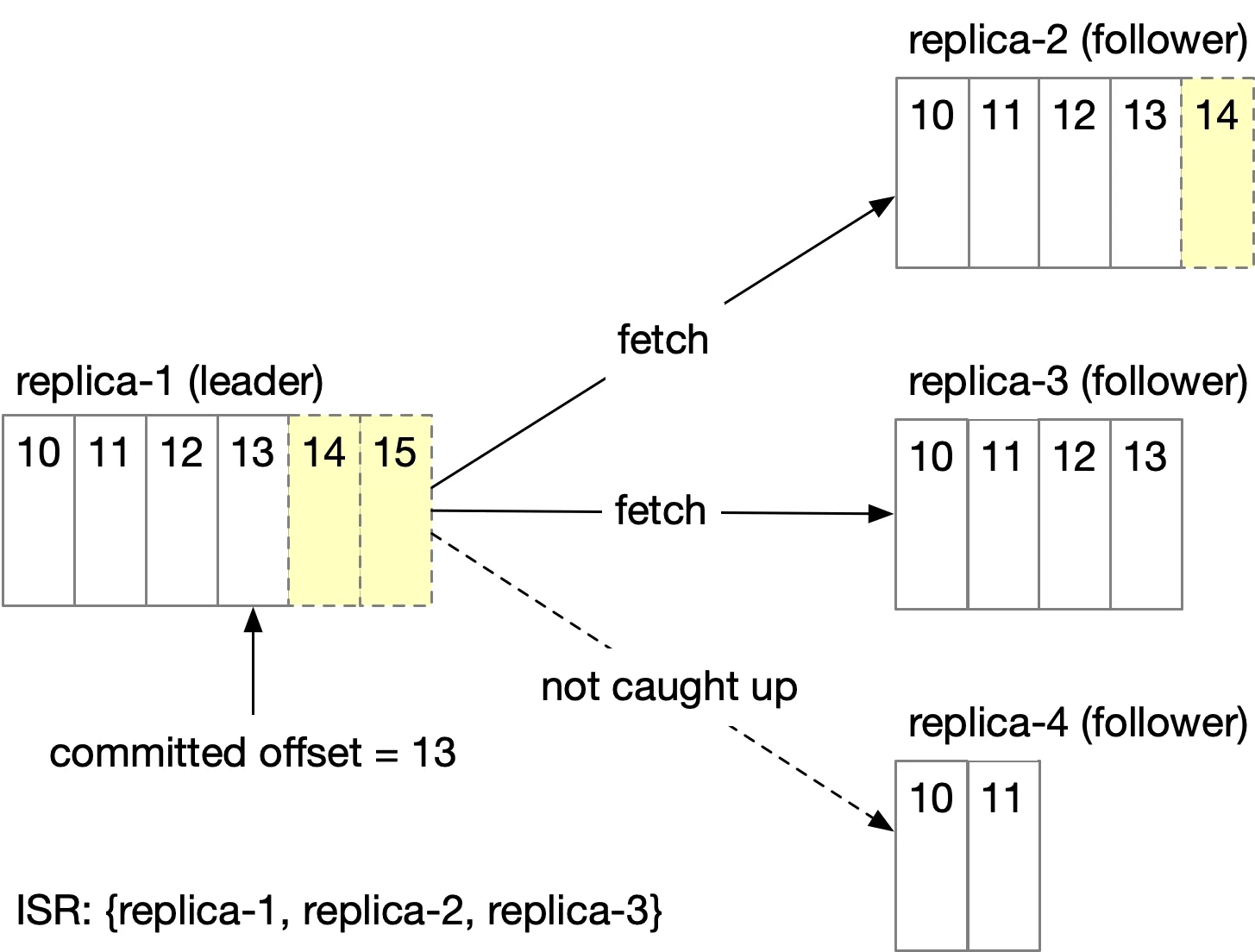
Replication
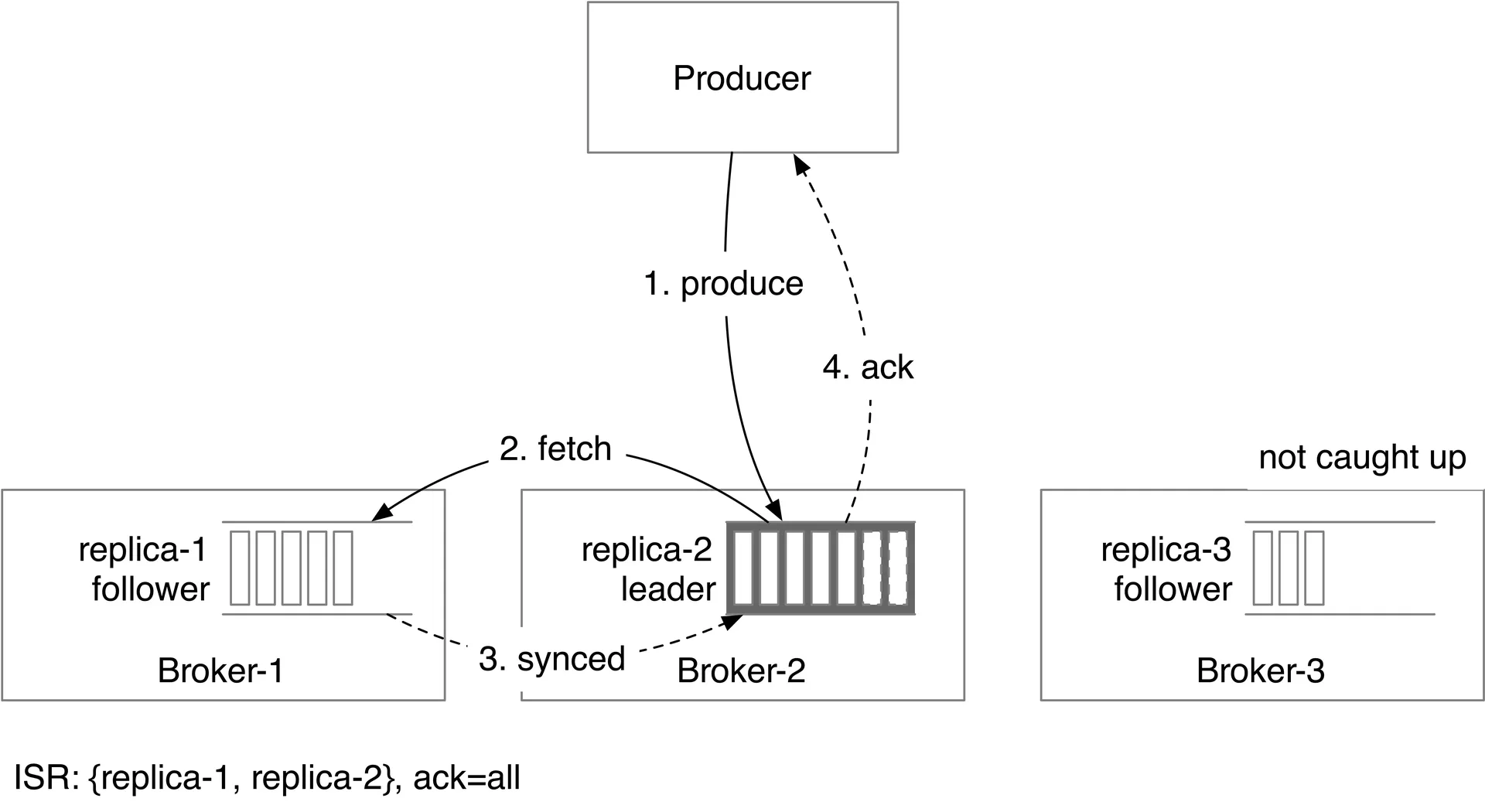
Each partition: 3 replicas across different brokers. Leader handles writes; followers pull from leader. Producer acks after "enough" replicas sync.
Replica distribution plan: Generated by active controller (elected broker). Persisted in metadata storage.
In-sync replicas (ISR): Replicas caught up with leader (within configurable lag). Leader always in ISR.
Acknowledgment settings:
| ACK | Behavior | Durability | Latency |
|---|---|---|---|
| ACK=all | All ISRs must receive | Strongest | Highest |
| ACK=1 | Leader persists only | Medium (lost if leader fails before replication) | Medium |
| ACK=0 | No ack, no retry | Lowest | Lowest |
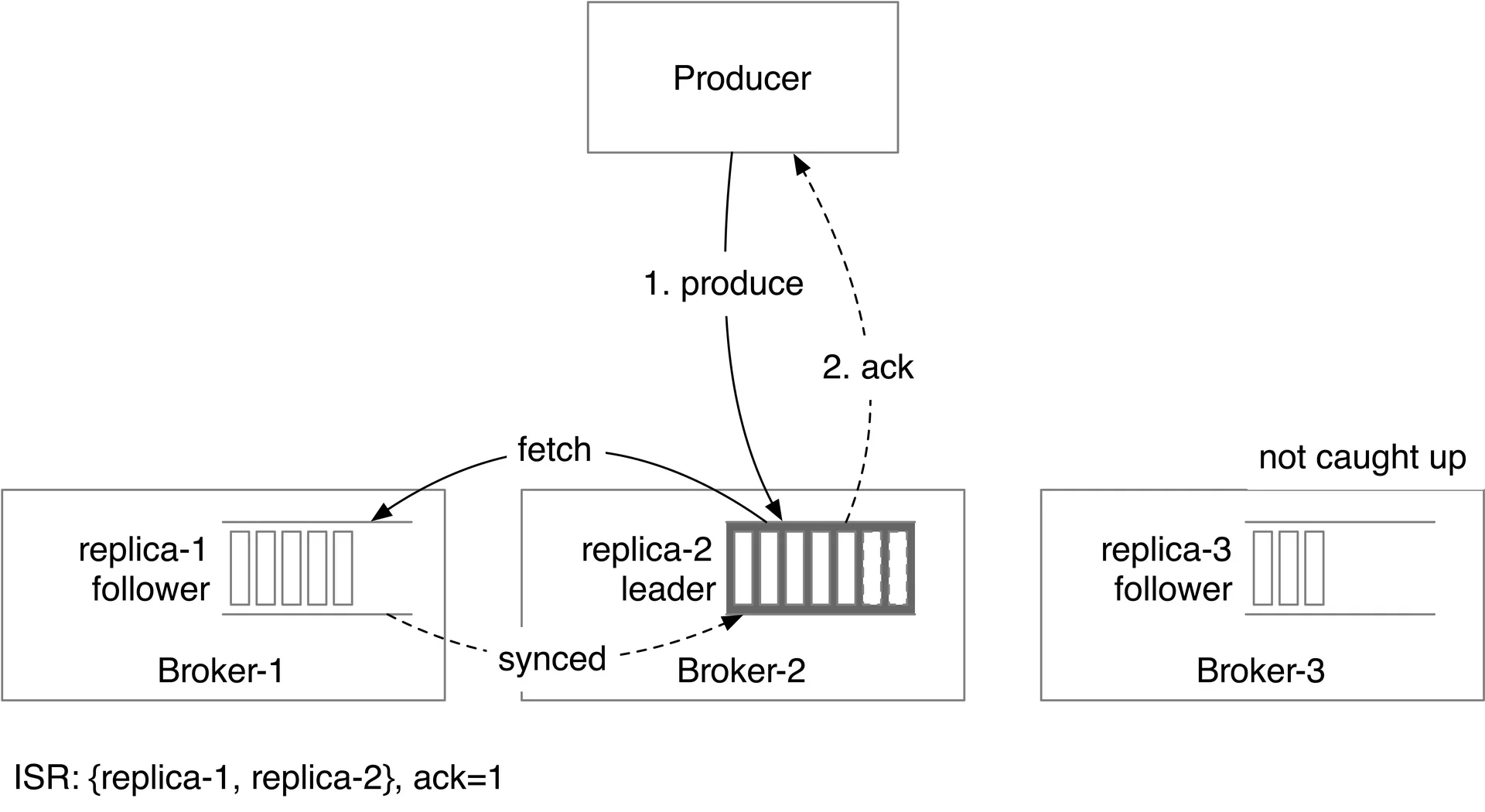
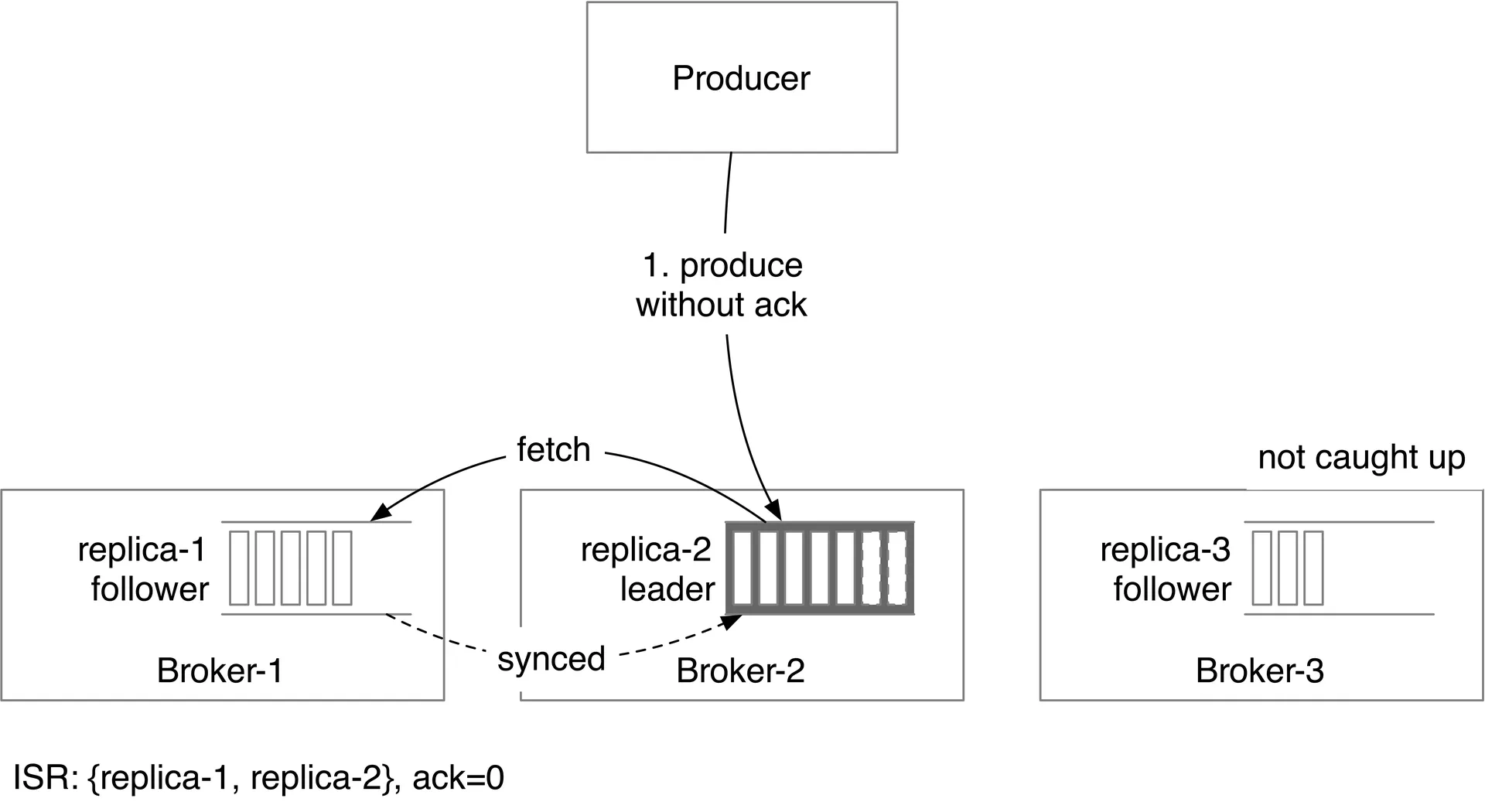
Consumers read from leader replicas (simplicity, limited connections per partition). If topic is hot → scale partitions + consumers. Alternative: read from closest ISR for cross-DC scenarios.
Scalability
Producers: Easy — add/remove instances.
Consumers: Consumer groups isolated → easy add/remove groups. Rebalancing handles group-internal changes.
Brokers (failure recovery):
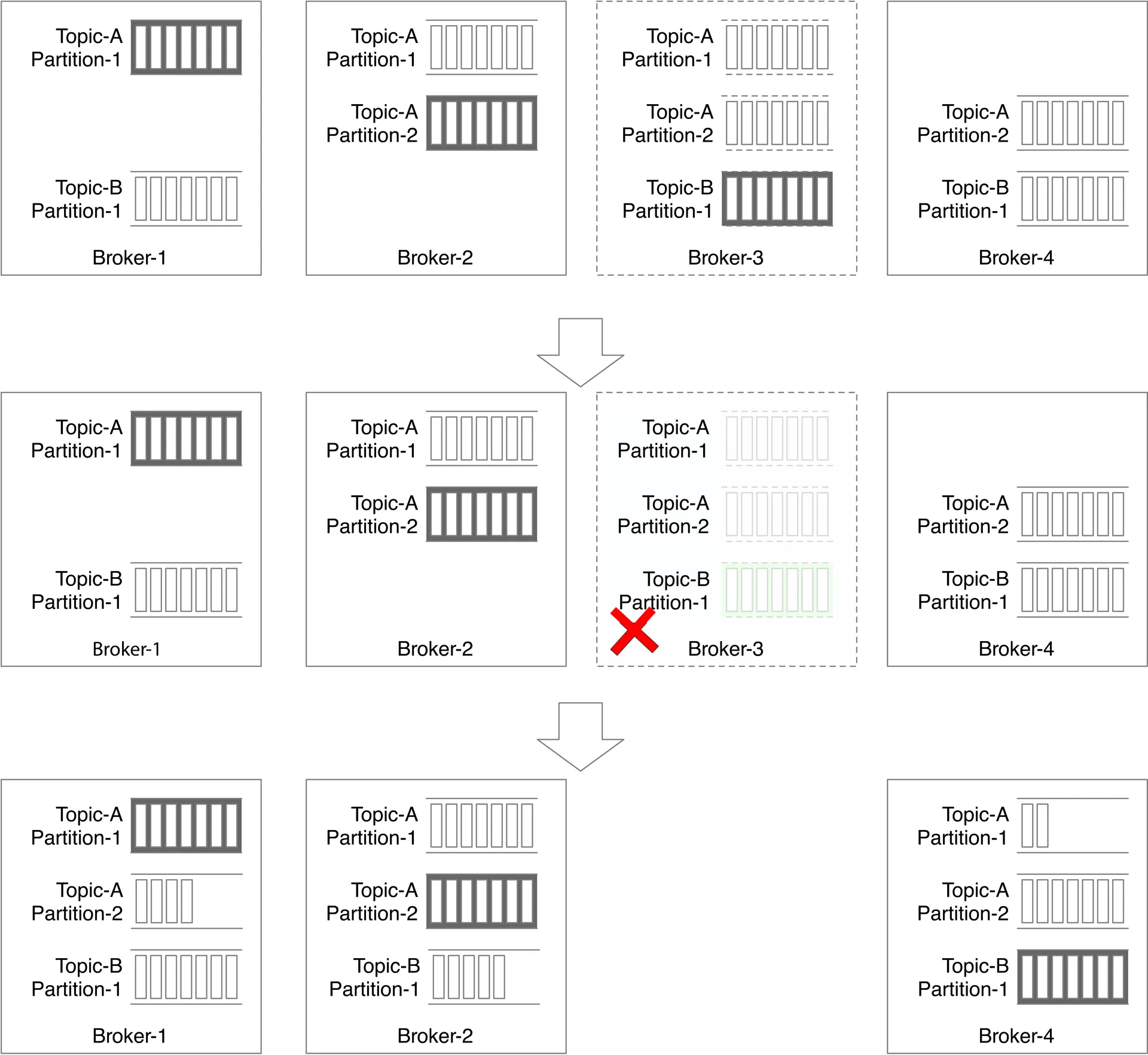
When broker crashes → controller detects, generates new replica distribution plan. New replicas catch up as followers.
Fault-tolerance considerations:
- Min ISR count: balances latency vs safety.
- Replicas on different nodes (never same broker).
- Cross-DC replicas → safer but higher latency/cost. Data mirroring as workaround.
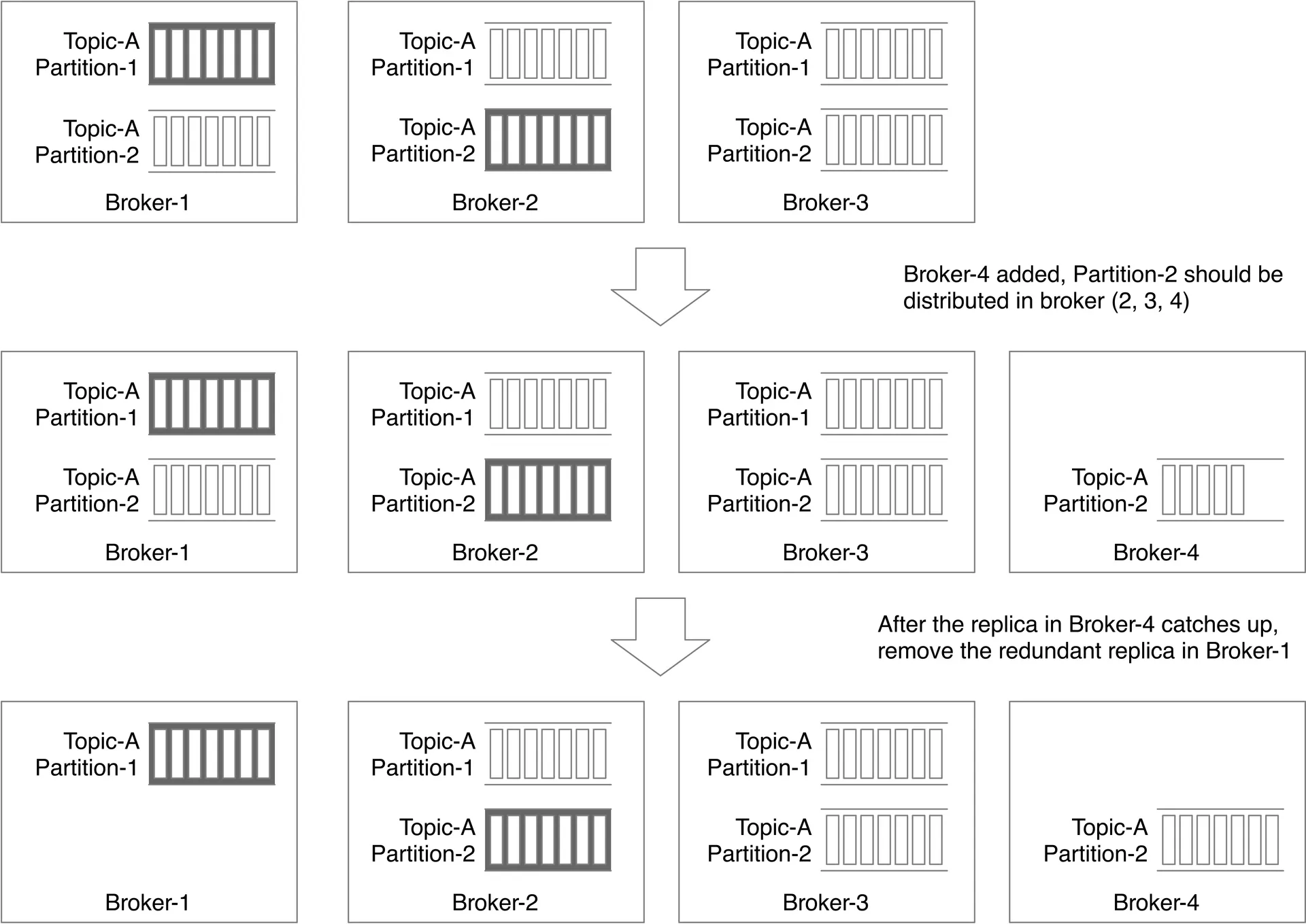
Adding brokers: Controller temporarily allows extra replicas → new broker catches up → remove redundant replicas. No data loss.
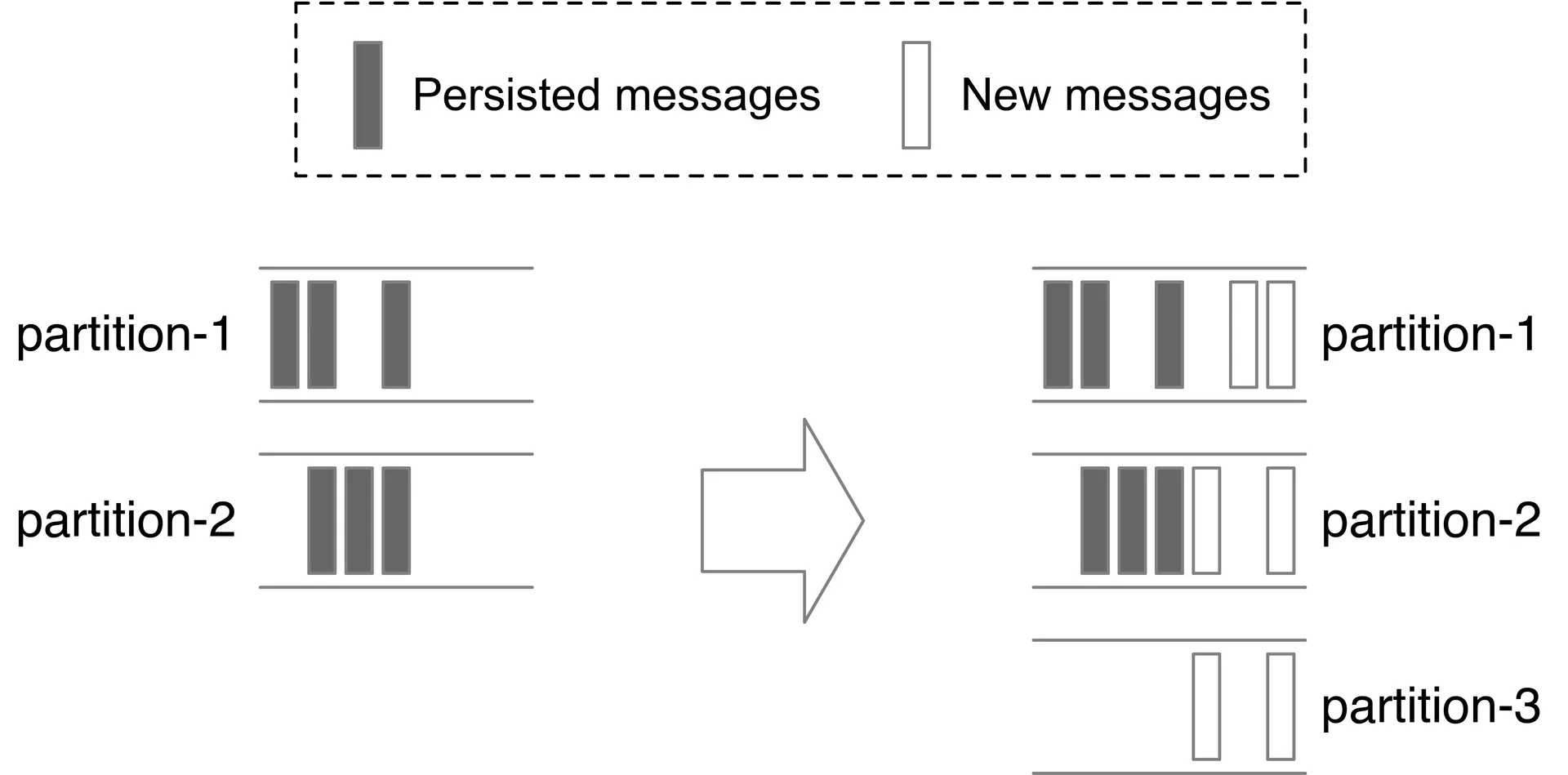
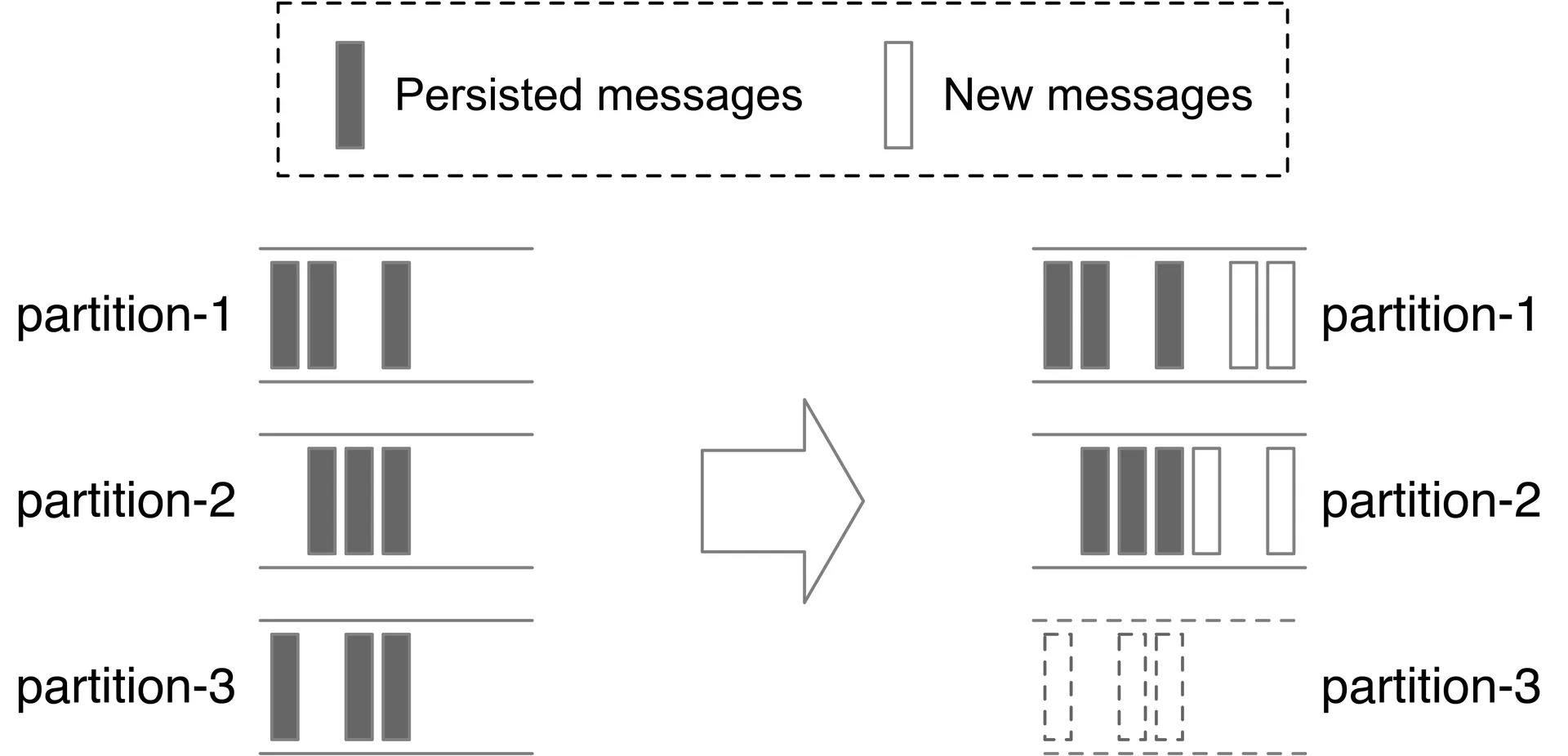
Partitions: Increasing — new messages go to all partitions; old messages stay. Decreasing — decommissioned partition stops receiving new messages but remains readable until retention expires. No immediate data migration.
Data delivery semantics
At-most once:
- Producer: async, ack=0, no retry.
- Consumer: commit offset BEFORE processing. Crash after commit → message lost.
- Use: metrics/logging (small data loss acceptable).

At-least once:
- Producer: ack=1 or ack=all, retry on failure/timeout.
- Consumer: commit offset AFTER processing. Crash after processing but before commit → re-consume (duplicate).
- Use: most cases; deduplication handled by unique key on consumer side.

Exactly once:
- Most difficult. High performance/complexity cost.
- Use: financial (payment, trading, accounting) where duplication unacceptable.

Advanced features
Message filtering
Problem: consumer needs only subset of topic messages. Naive: consumer fetches all, filters client-side (wasteful). Better: broker-side filtering via message tags (metadata, not payload — avoids decryption/deserialization overhead). Tags support multi-dimensional filtering. Complex logic (formulae) → too heavyweight for message queue.

Delayed & Scheduled messages
Delayed: Message held in temporary storage, delivered to topic after specified delay. Example: order payment check after 30 min.
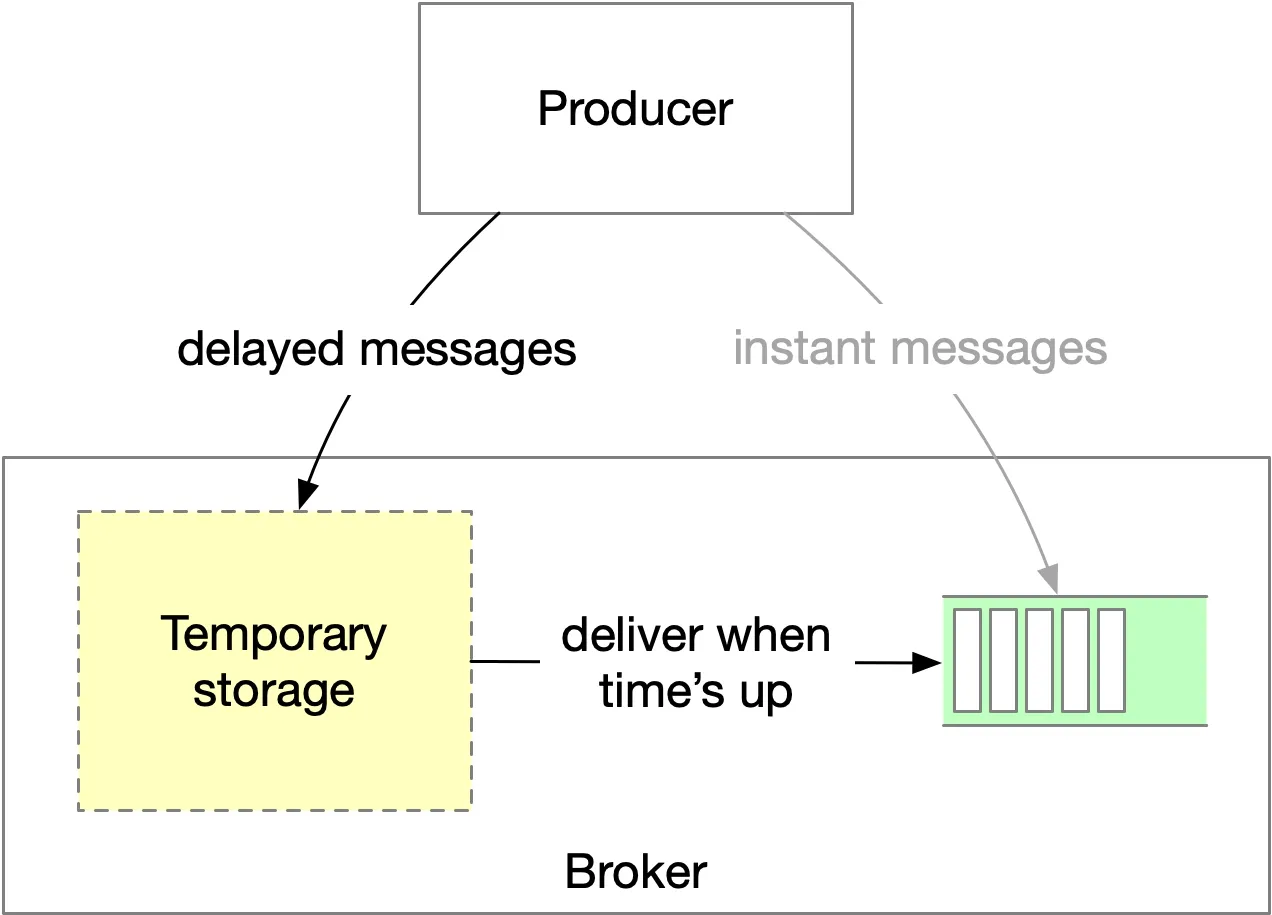
Timing implementations:
- Dedicated delay queues with predefined levels (RocketMQ: 1s, 5s, 10s, 30s, 1m, 2m, 3m, 4m, 6m, 8m, 9m, 10m, 20m, 30m, 1h, 2h).
- Hierarchical time wheel.
Scheduled: Similar design; message delivered at specific scheduled time.
Step 4 - Wrap Up
Additional talking points:
- Protocol: AMQP, Kafka protocol — cover all activities (produce, consume, heartbeat), transport large data, data integrity.
- Retry consumption: Failed messages → dedicated retry topic for later consumption.
- Historical data archive: Truncated messages archived to HDFS or object storage for replay.