Real-time Gaming Leaderboard
6 min readDesign a leaderboard for an online mobile game. Users earn points for winning matches. Leaderboard shows top players and a specific user's position.
Figure 1: Leaderboard for Marvel Contest of Champions
Step 1 - Understand the Problem and Establish Design Scope
Requirements:
- Simple point system: +1 point per match win
- All players included
- Monthly tournaments (new leaderboard each month)
- Display top 10 + specific user's rank (bonus: 4 places above/below user)
- 5M DAU, 25M MAU
- 10 matches per player per day (avg)
- Same score → same rank (ties allowed, can discuss tie-breaking)
- Real-time updates (not batched)
Non-functional: real-time score updates, real-time leaderboard reflection, general scalability/availability/reliability.
Back-of-the-envelope estimation:
- 5M DAU evenly distributed → avg 50 users/sec (5M / 86,400 ≈ 50)
- Peak: 5× average = 250 users/sec
- QPS for scoring: 50 × 10 games = ~500 QPS avg, peak 2,500
- QPS for top-10 fetch: ~50 (once per game open)
Step 2 - Propose High-Level Design and Get Buy-In
API design
POST /v1/scores— Internal API (game server only, NOT client). Updates score on win. Params:user_id,points. Returns 200/400.GET /v1/scores— Fetch top 10. Response:[{user_id, user_name, rank, score}, ...],total: 10GET /v1/scores/{:user_id}— Fetch specific user's rank. Response:{user_info: {user_id, score, rank}}
High-level architecture
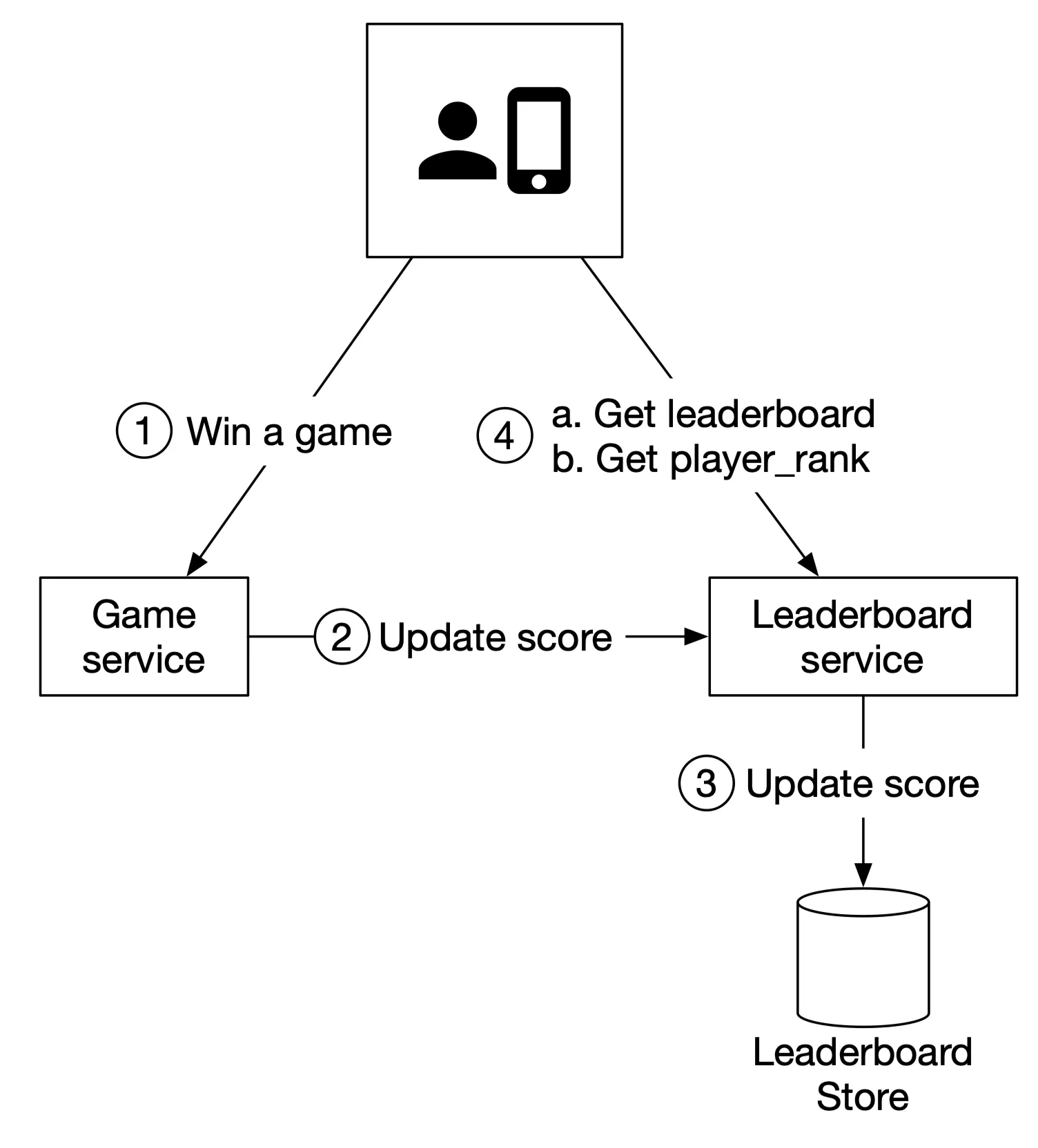
Figure 2: High-level design
- Player wins → client → game service
- Game service validates win → calls leaderboard service to update score
- Leaderboard service updates leaderboard store
- Players fetch leaderboard data (top 10 + own rank) directly from leaderboard service
Why server-side score setting only?
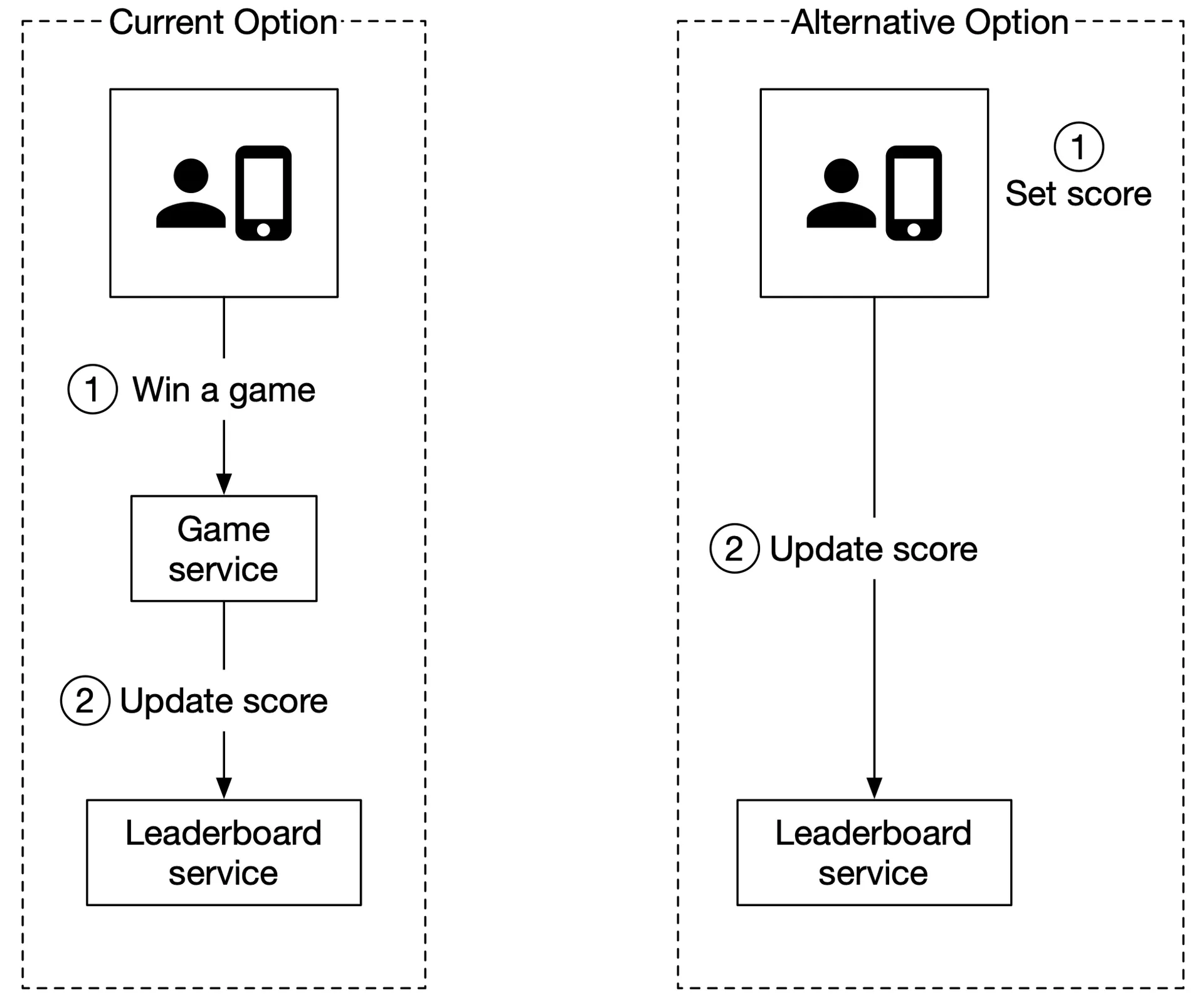
Figure 3: Who sets the leaderboard score
Client-side is insecure (MITM attack, proxy manipulation). Server-authoritative games (e.g. online poker) don't need explicit client calls — game server knows when game finishes.
Message queue? Optional. Use Kafka if scores feed multiple services (leaderboard, analytics, push notifications). Not required here.
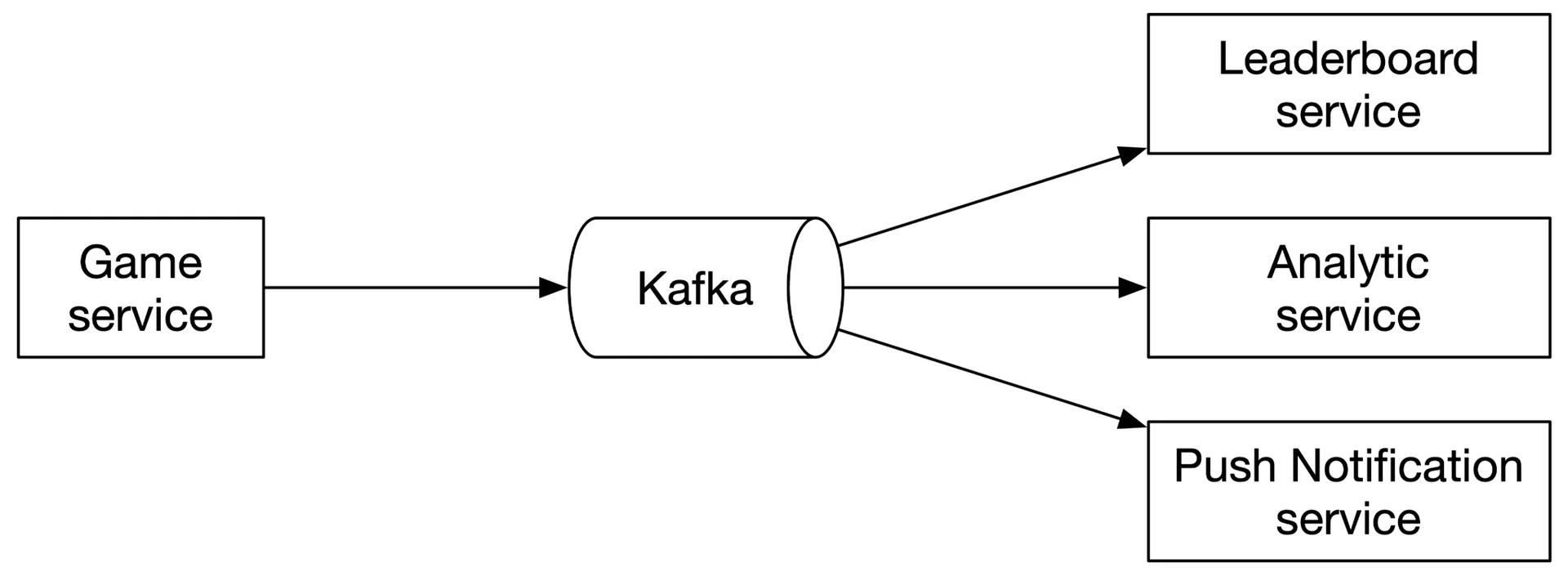
Figure 4: Game scores used by multiple services
Data models
Relational database solution (rejected)

Figure 5: Leaderboard table
- Insert:
INSERT INTO leaderboard (user_id, score) VALUES ('mary1934', 1); - Update:
UPDATE leaderboard SET score = score + 1 WHERE user_id = 'mary1934'; - Rank query:
SELECT (@rownum := @rownum + 1) AS rank, user_id, score FROM leaderboard ORDER BY score DESC;
Why it fails at scale: Sorting millions of rows takes 10s of seconds. Not real-time. Caching infeasible due to constant changes. LIMIT 10 with index helps top-10 but doesn't solve user rank lookup (requires table scan).
Redis sorted set solution (chosen)
Sorted set internals: hash table (user→score) + skip list (score→user). Sorted by score.
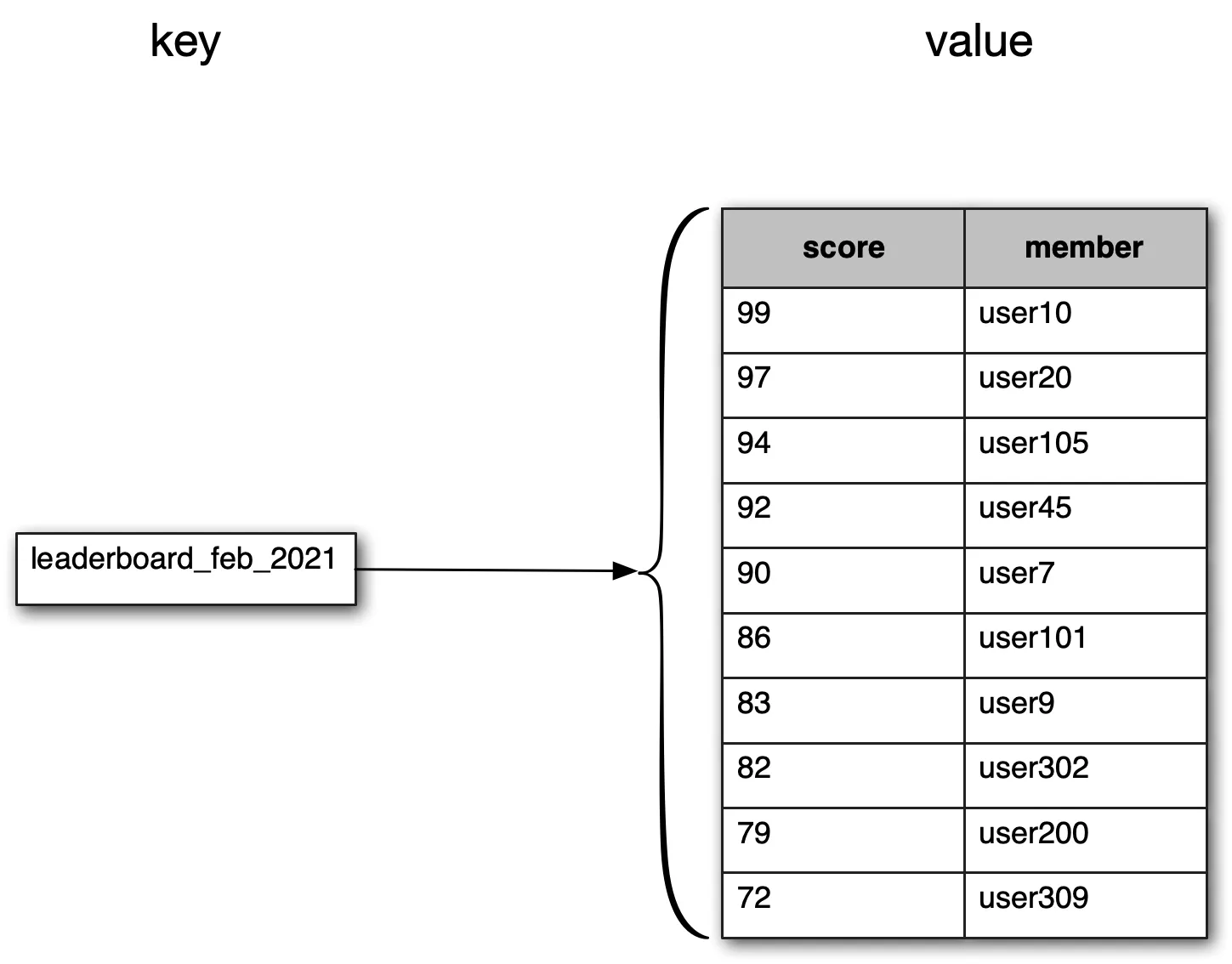
Figure 8: February leaderboard as sorted set
Skip list: base sorted linked list + multi-level indexes. Search O(log n) vs O(n) for linked list.
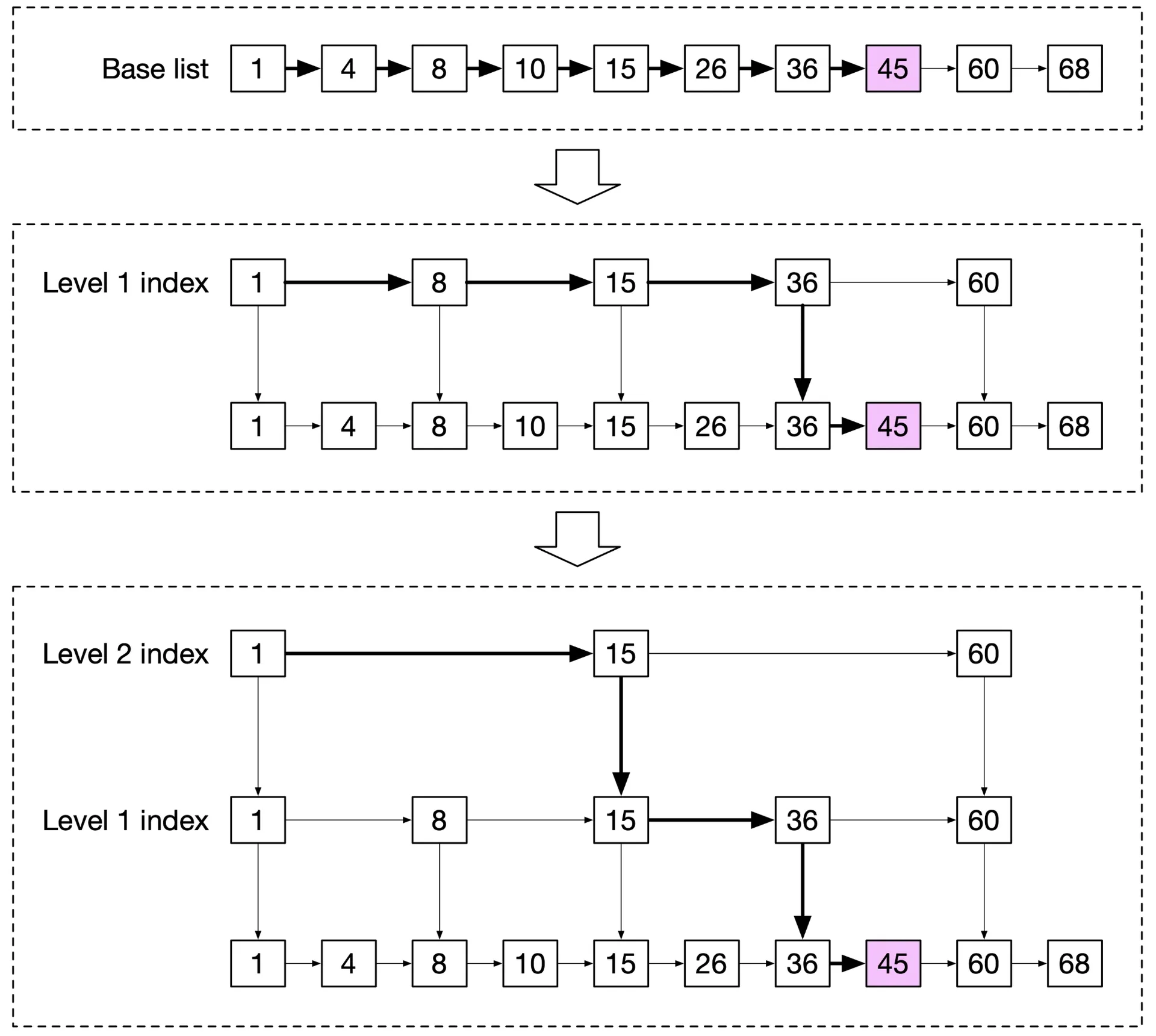

Figures 9-10: Skip list
Redis operations: O(log n) complexity.
ZADD: insert or update user scoreZINCRBY: increment score by amountZRANGE/ZREVRANGE: fetch range sorted by score. O(log n + m) where m = entries fetched.ZRANK/ZREVRANK: fetch position (ascending/descending). O(log n).
Workflows:
- User scores a point:
ZINCRBY leaderboard_feb_2021 1 'mary1934'

Figure 11: A user scores a point
- Fetch top 10:
ZREVRANGE leaderboard_feb_2021 0 9 WITHSCORES

Figure 12: Fetch top 10
- Fetch user rank:
ZREVRANK leaderboard_feb_2021 'mary1934'

Figure 13: Fetch user's rank
- Fetch relative position (4 above/below):
ZREVRANGE leaderboard_feb_2021 357 365(for rank 361)
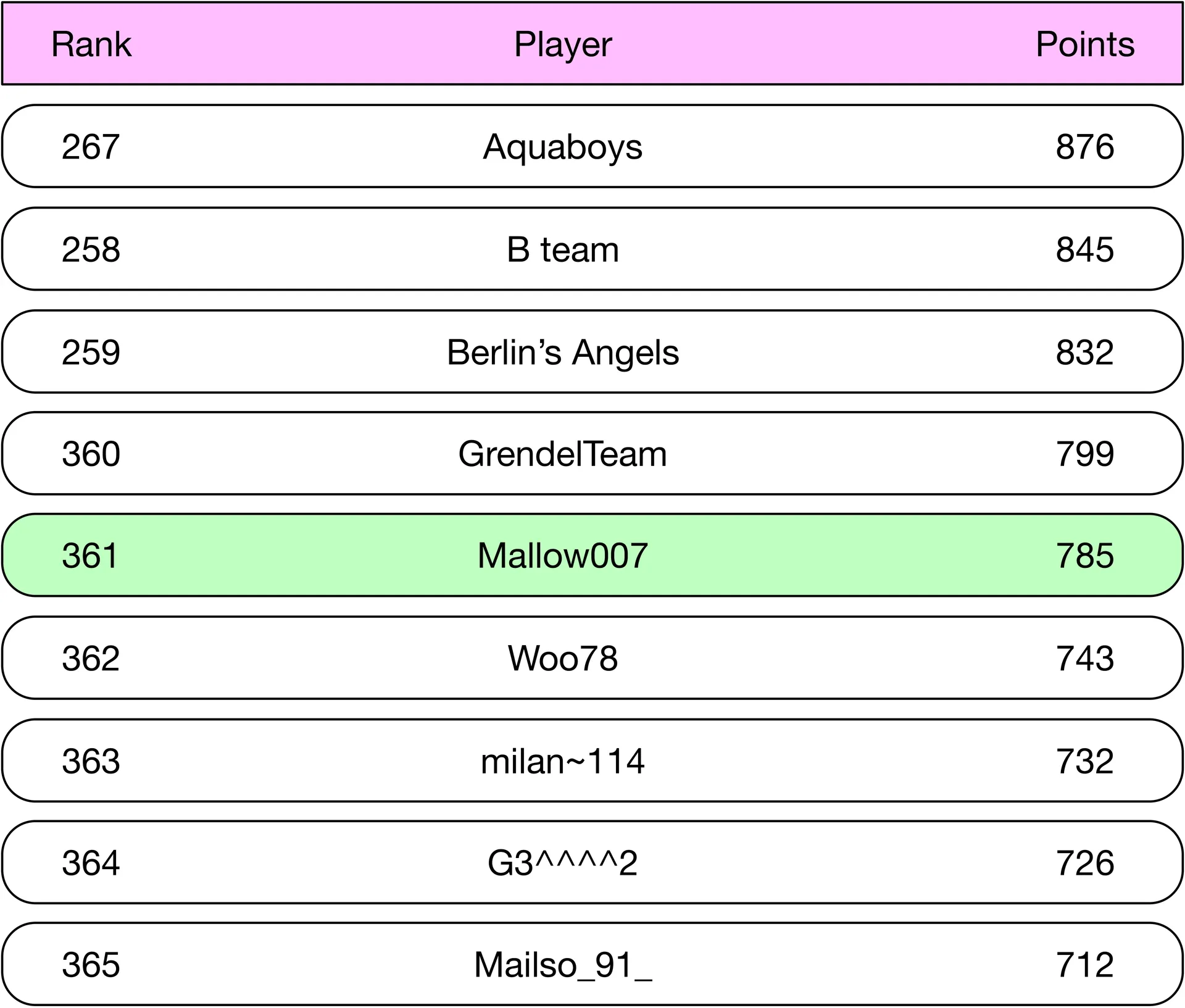
Figure 14: Fetch 4 above/below
Storage: 25M MAU × (24 char ID + 2 byte score) = 26 bytes → ~650 MB. Even 2× for skip list/hash overhead, one Redis server is enough. Peak 2,500 updates/sec — within single Redis capacity.
Persistence: Redis supports persistence (snapshotting). Configure read replica; on failure promote replica, attach new replica. Also persist to MySQL (user table + point table with timestamps) for recovery.
Step 3 - Design Deep Dive
Cloud vs self-managed
Self-managed
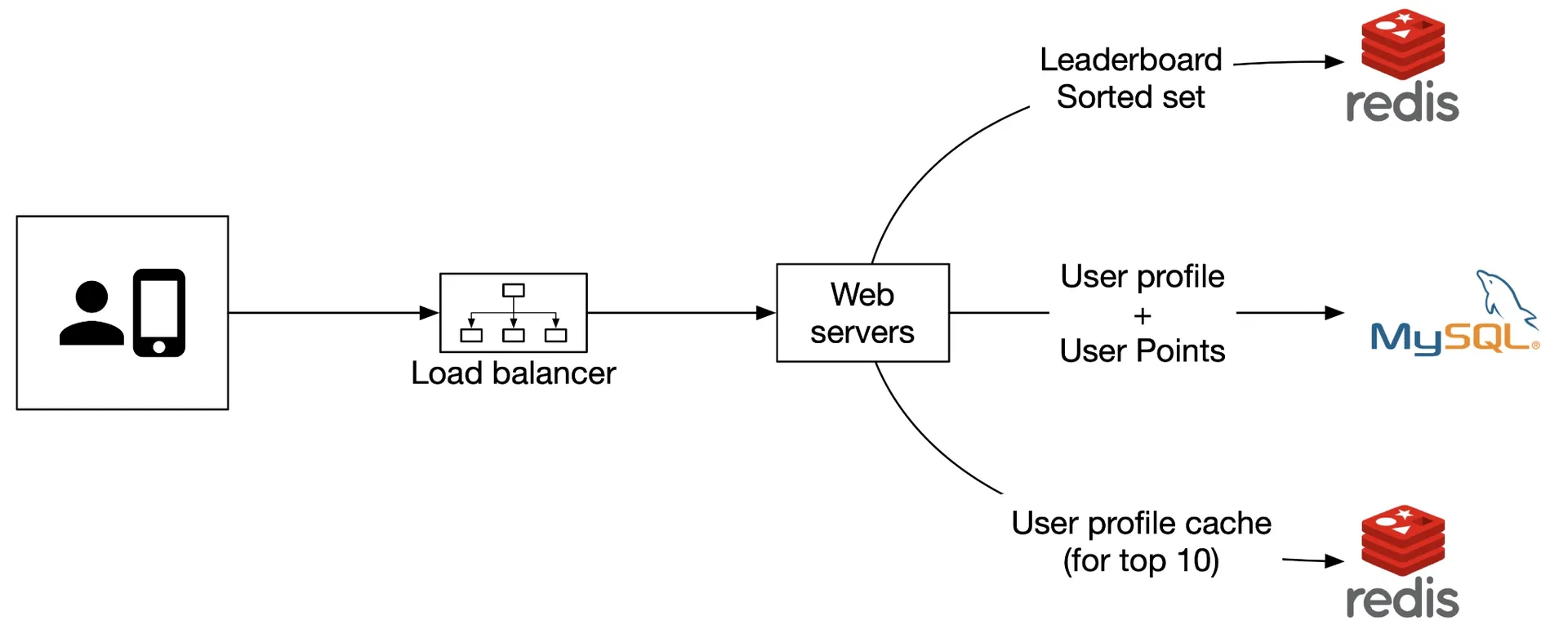
Figure 15: Manage our own services
Monthly sorted set in Redis for scores. User details (name, profile image) in MySQL. Fetch leaderboard → also query DB for user details. Cache top-10 user profiles for performance.
Cloud (AWS serverless)
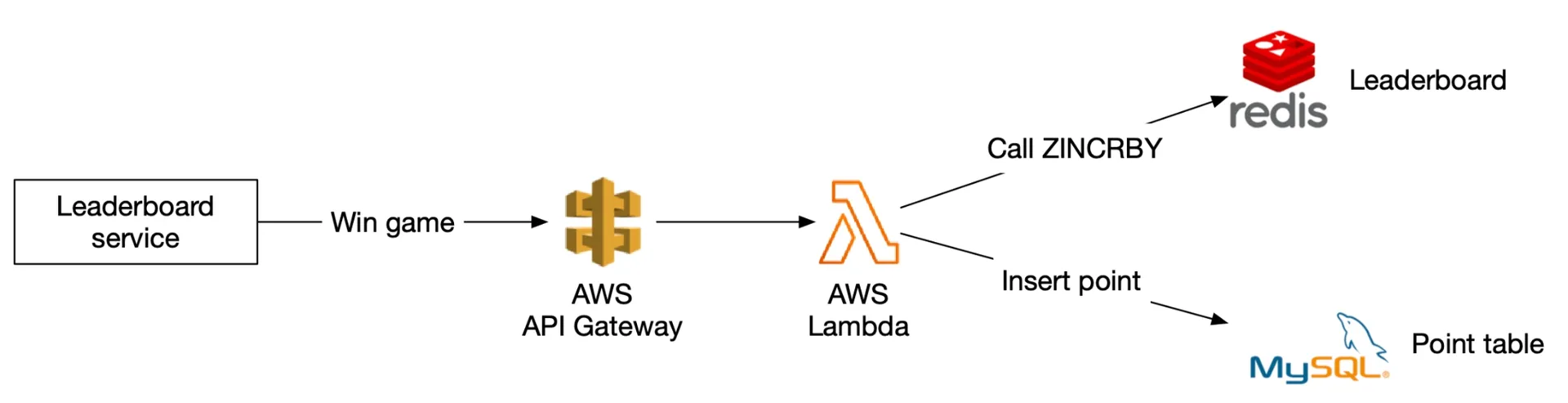
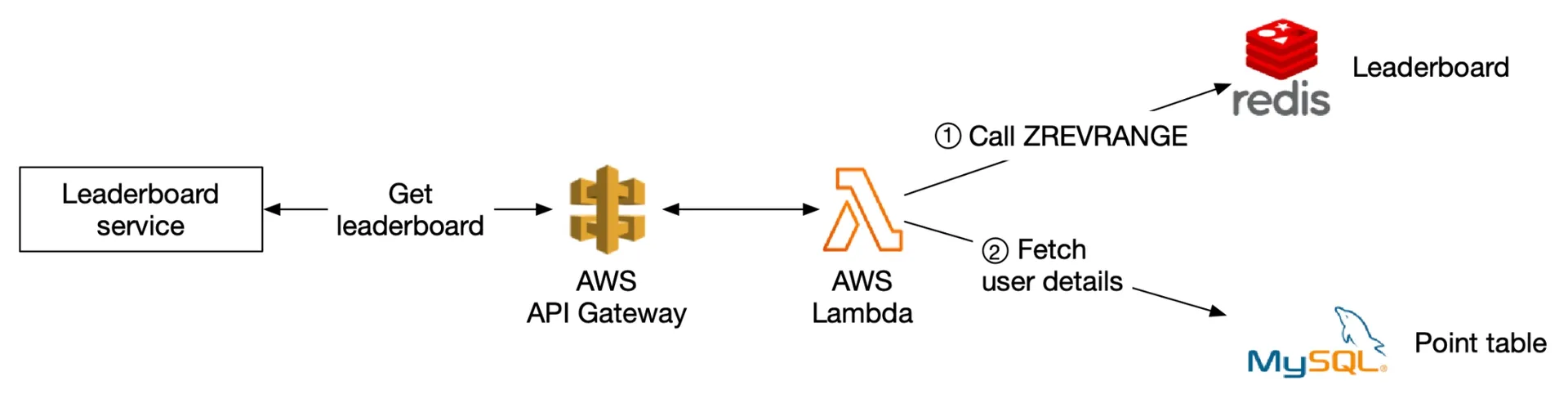
Figures 16-17: Score a point, Retrieve leaderboard
Amazon API Gateway + AWS Lambda. Lambda functions invoke Redis/MySQL. Auto-scaling built-in. Recommended for greenfield projects.
Scaling Redis (500M DAU, 100× original)
65 GB storage, 250,000 QPS → sharding needed.
Fixed partition (chosen)

Figure 18: Fixed partition
Split by score range into N shards (e.g. 1-100, 101-200, ...). Need even score distribution; adjust ranges otherwise. Application-level sharding.
- Insert/update: know user's current score → route to shard. Maintain secondary cache (user_id → score). When score increases across shard boundary → remove from old, add to new, update cache.
- Top 10: fetch from highest-score shard.
- User rank: local rank (within shard) + total players in all higher-score shards.
INFO KEYSPACEgives shard size in O(1).
Hash partition (Redis cluster)
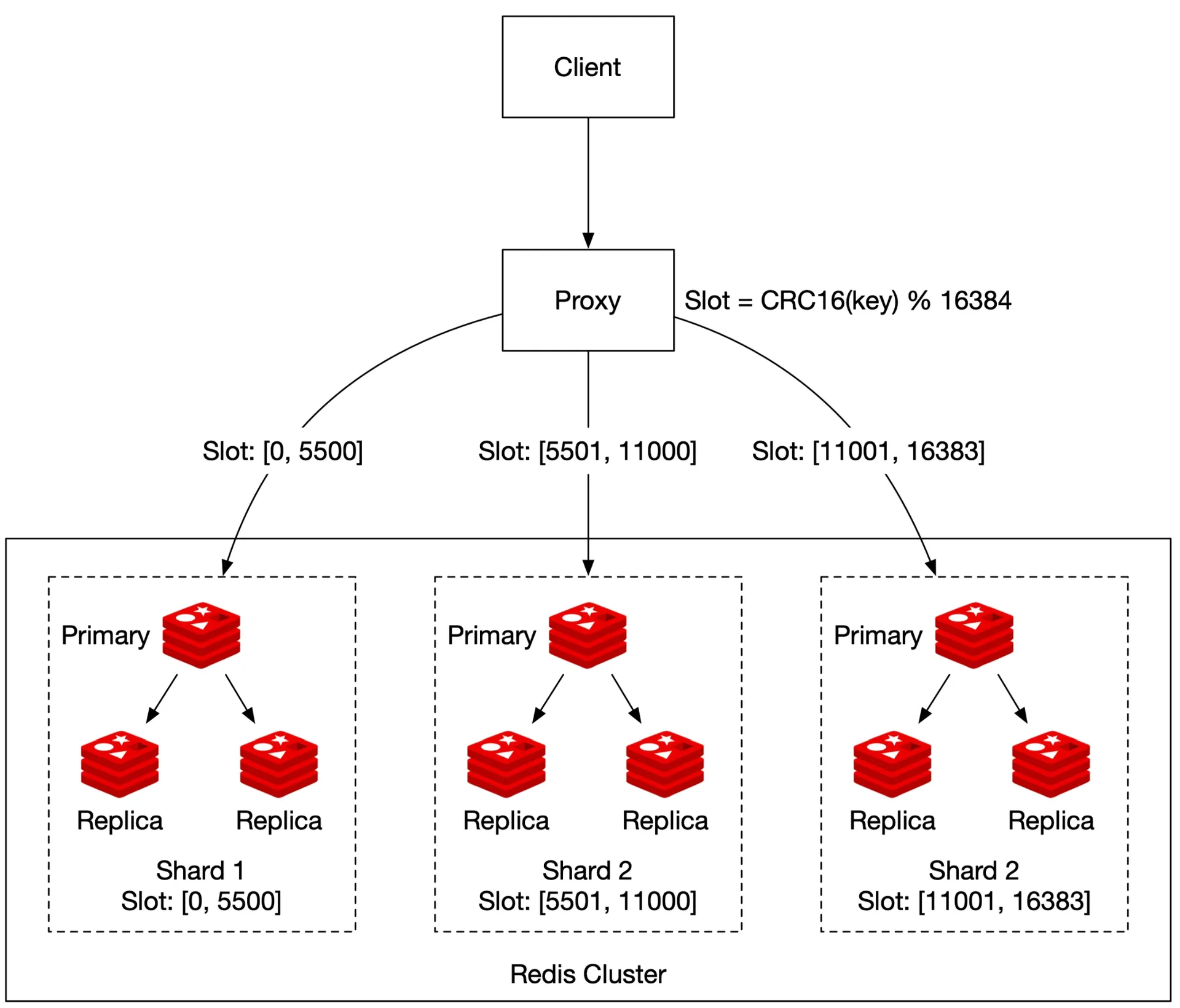
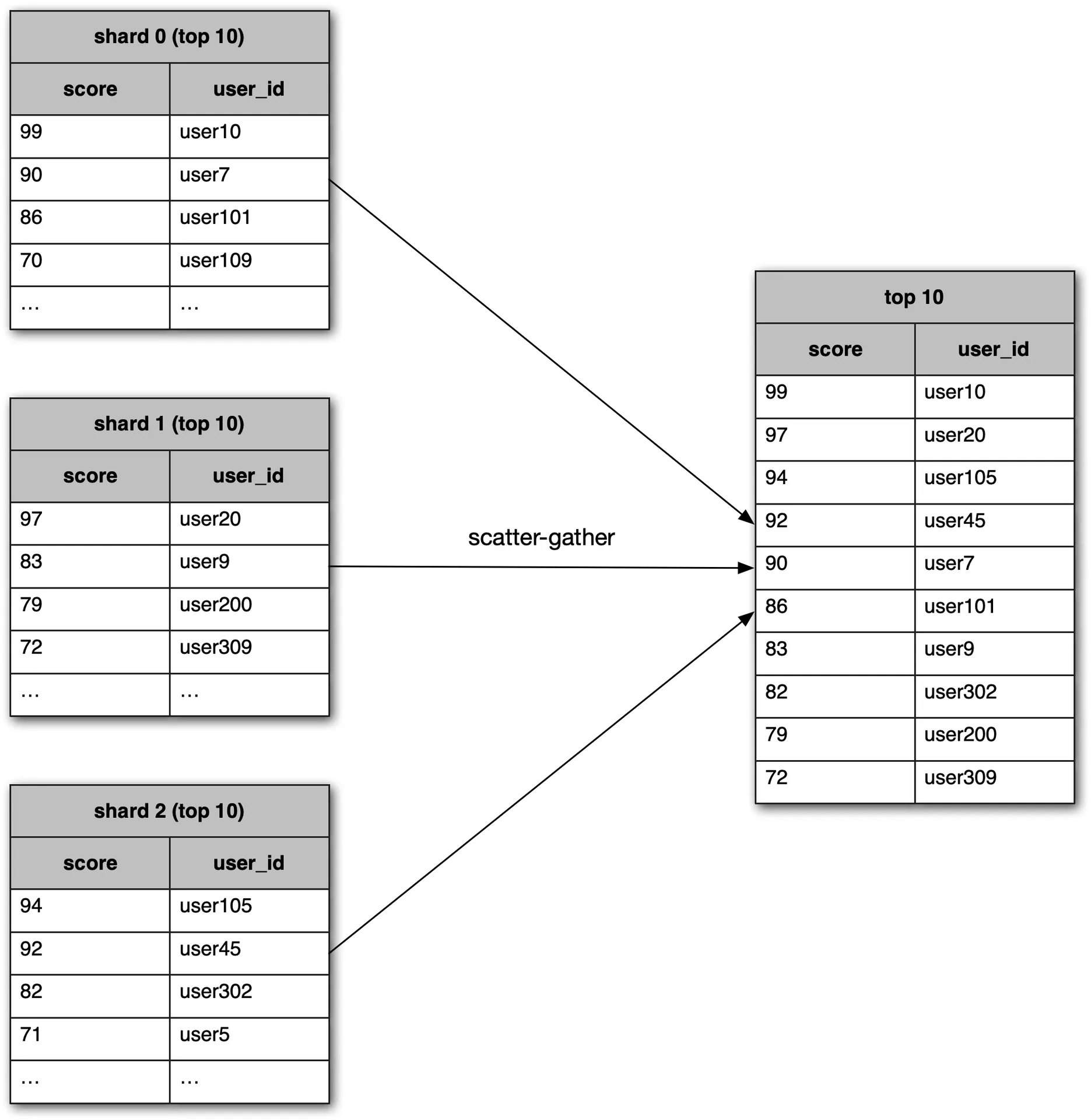
Figures 19-20: Hash partition, Scatter-gather
CRC16(key) % 16384 → hash slot → node. 16,384 hash slots across nodes.
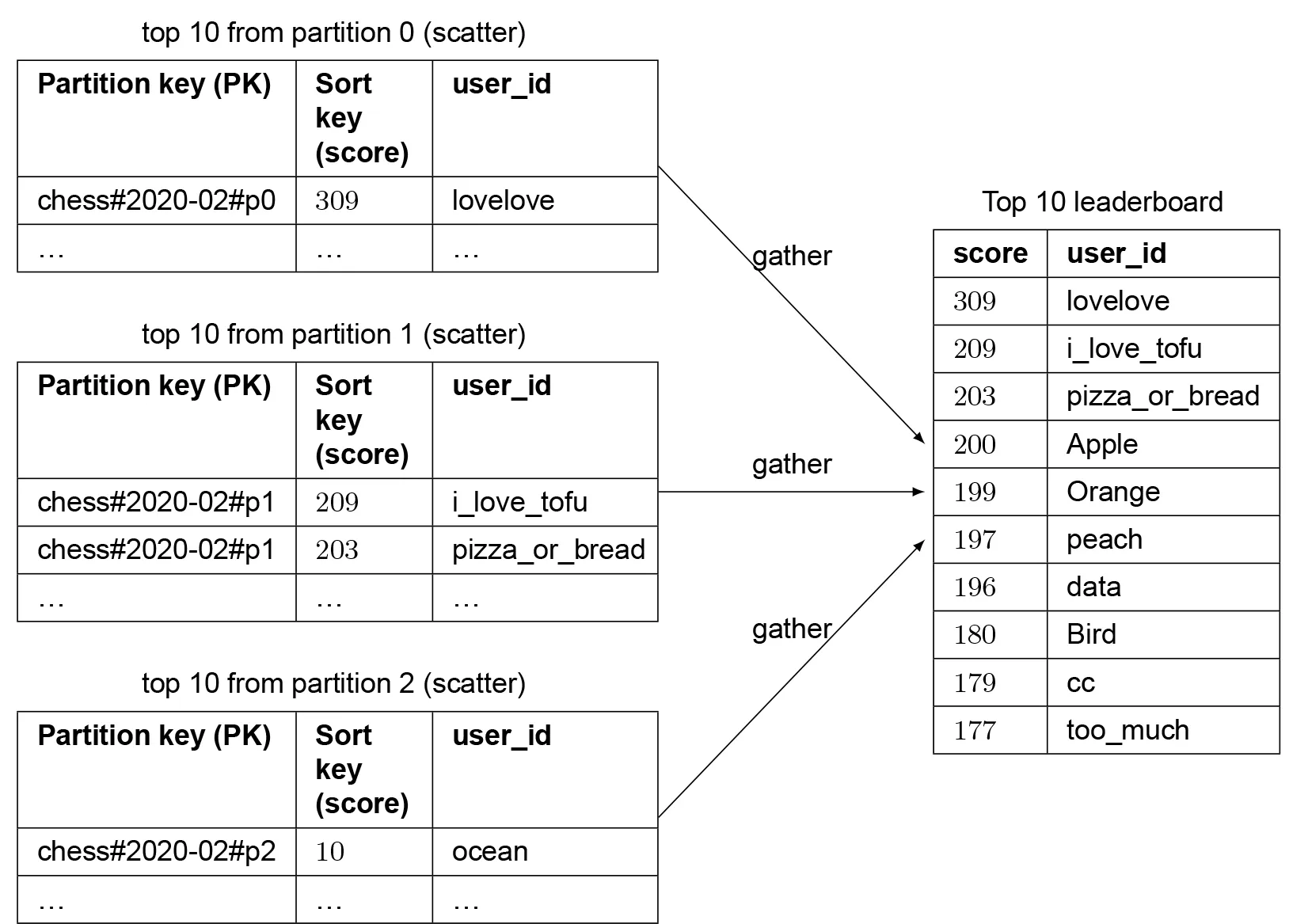
- Top K: scatter-gather: get top 10 from each shard, merge in app. Latency high for large K. No straightforward per-user rank. Not recommended vs. fixed partition.
Sizing Redis: write-heavy apps → allocate 2× memory for snapshot safety. Use redis-benchmark for hardware sizing.
Alternative: NoSQL (DynamoDB)

Figure 21: DynamoDB solution
Requirements: optimized for writes, efficient in-partition sort by score.
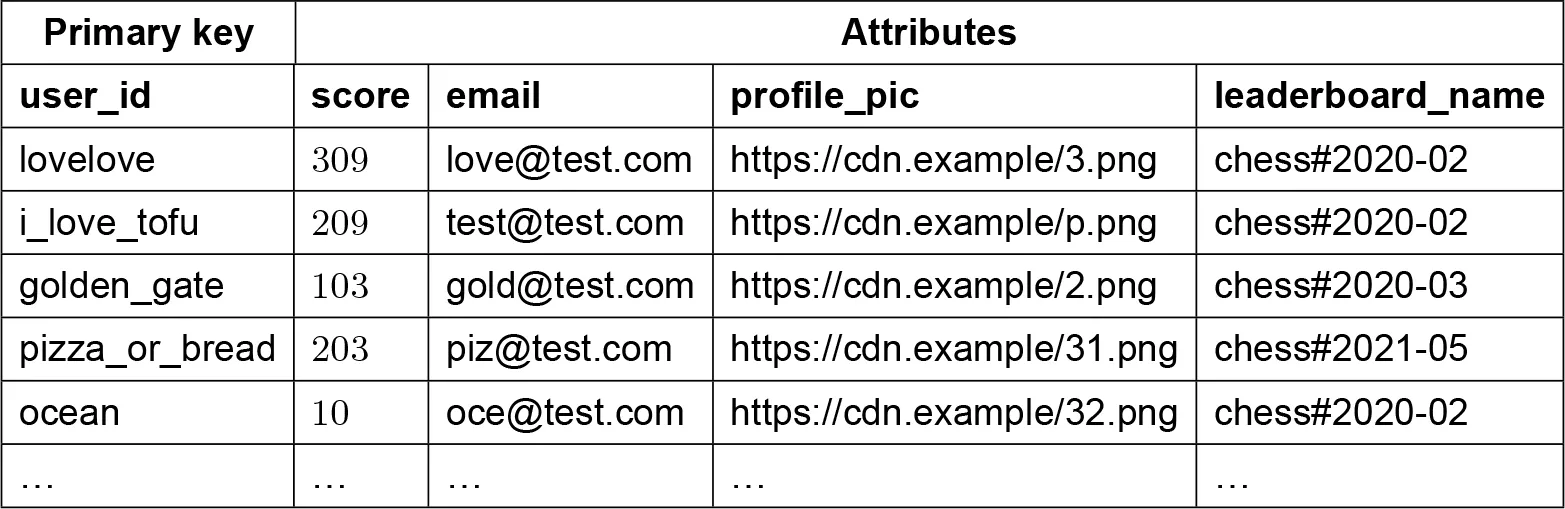
Table design:
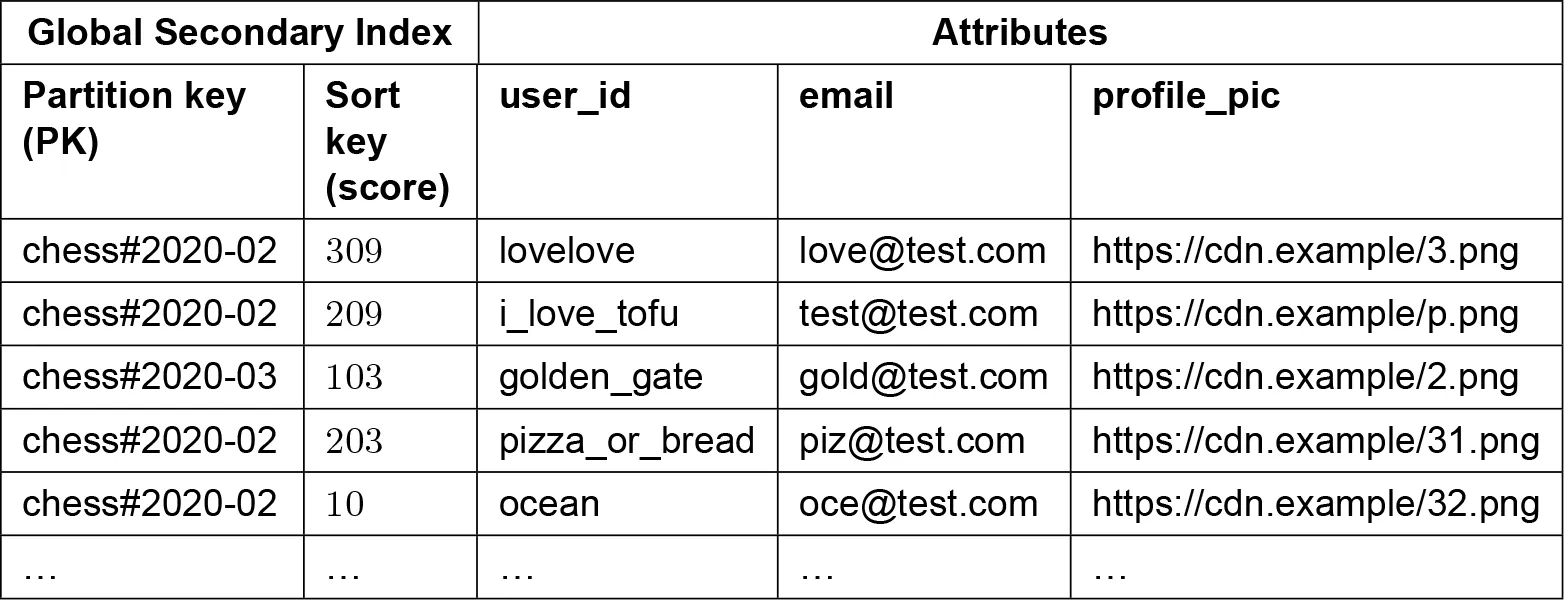
- Partition key:
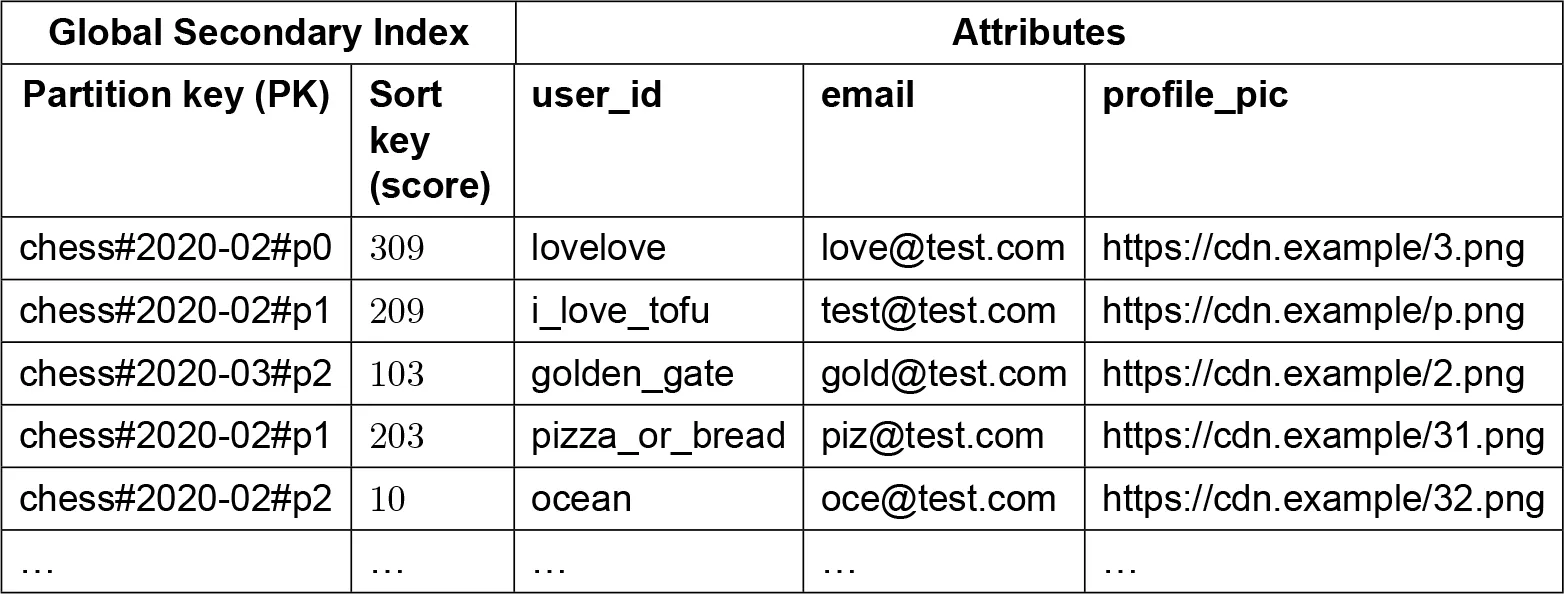
game_name#{year-month}+ sort key:score. Problem: hot partition (all current month data in one partition). - Write sharding: partition key =
game_name#{year-month}#p{partition_number}(N =user_id % number_of_partitions). N partitions, each locally sorted.
Figures 22-25: Denormalized view, partition/sort keys, updated partition key, scatter-gather
- Top 10: scatter-gather across N partitions → merge results.
- User rank: no straightforward solution. Use percentile approximation (cron job analyzes score distribution per shard, caches percentile ranges). e.g. "You're in the top 10-20%."
Trade-off: more partitions = less load per partition but more read complexity (scatter-gather).
Step 4 - Wrap Up
MySQL rejected (no real-time at scale) → Redis sorted sets (O(log n), in-memory, skip list + hash). Scaling from 5M to 500M DAU via fixed-partition sharding. Alternative NoSQL (DynamoDB with write sharding). Extra topics: Redis Hash for fast user detail retrieval; tie-breaking by timestamp (older score wins); recovery via MySQL replay → ZINCRBY rebuild.